PostgreSQL教程:字符串操作的初级指南(三)
发表时间: 2024-03-10 22:35
上次关于数值类型的介绍太简短了点,介绍几个有意思的操作
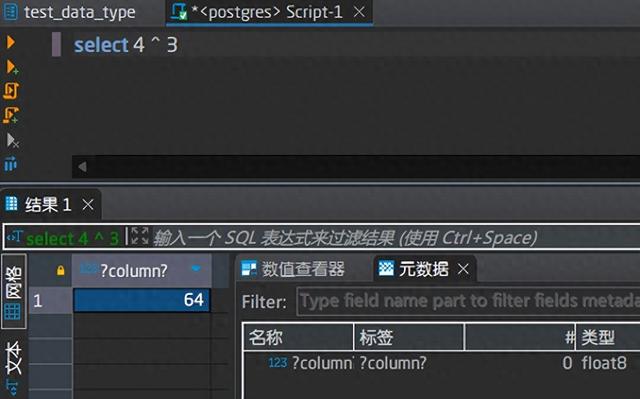
注意:计算出来的结果是一个float8的浮点数,也就是double
设计者是一个有趣的灵魂,尽可能地在模拟数学当中的平方根符号
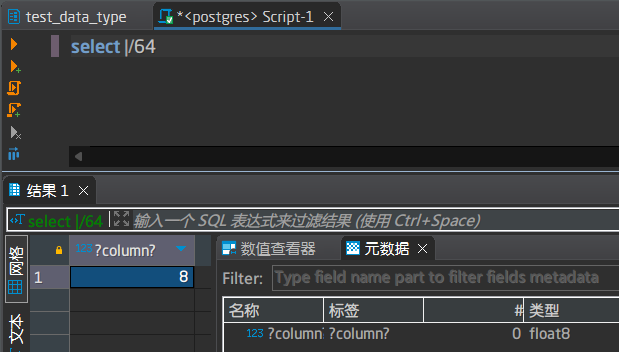
注意:这里得到的也是一个float8的浮点数,也就是double
我以为会是|值|来表示,没想到直接一个@符号就解决了
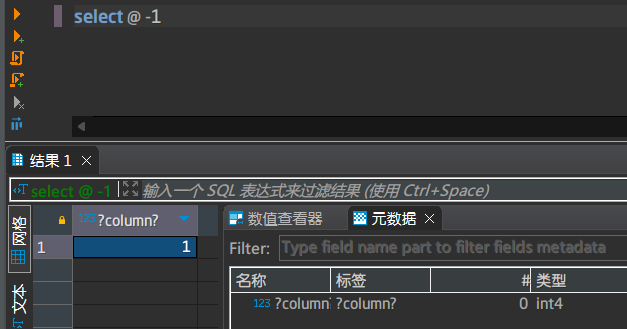
注意:@和数值之间至少要留一个空格
还有几个常用的操作,位运算&、|,以及左移<<和右移>>
好了,就补充这么多吧,还有许多函数后面再研究介绍。
接下来看下字符串和日期
字符串分3种,前面大致介绍过
简称char,最大存储1个G的数据,定长
简称varchar,最大存储1个G的数据,长度可变
跟MYSQL中的text是一样的
举一个示例:

默认情况下,字符串会被存储为text类型,我们可以强制转换成其它字符串类型
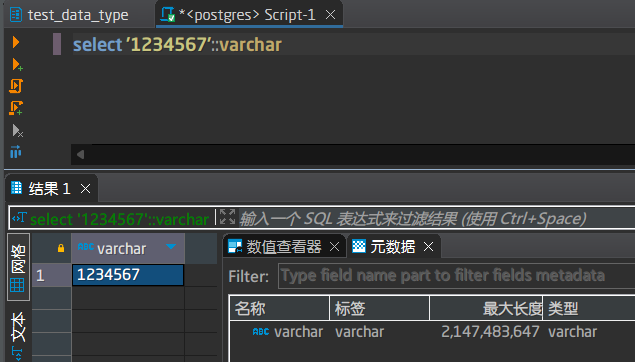
这里我们可以看到text和varchar的最大存储长度,2147483647。这个值其实可以存储最大2G(准确地说,还有1个字节才到2G),而一般网上说的都是1G,我的PG版本是14,所以大家在学习和工作过程中要尽量自己亲自实践去了解下具体的情况。当然,正常情况下,我们设计系统,单个值存储不到这么大,如果有这么大,我们首先考虑的是能否从业务和系统设计2方面思考优化。
再看下转char
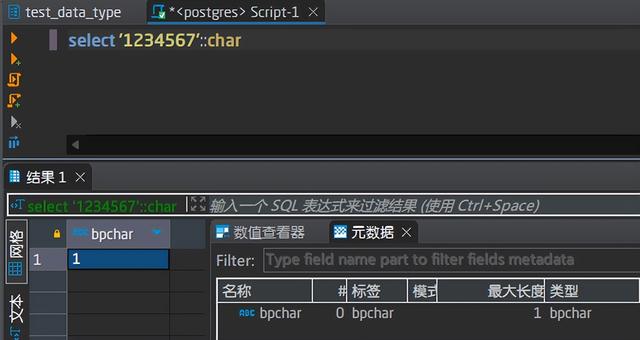
问题来了,1234567变成了1,再看数据类型变成了bpchar,长度为1。那思考一下,char不指定长度,默认长度就是1,那指定长度呢,再看2个测试:
取5个长度
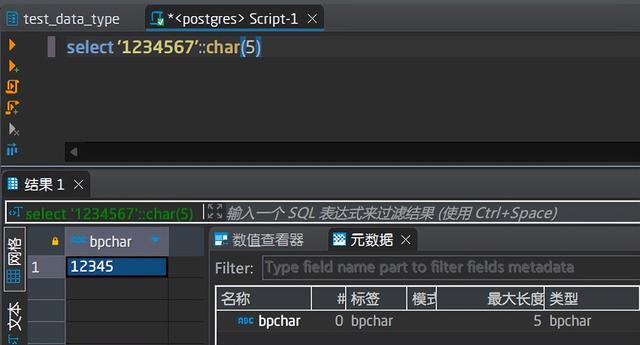
取9个长度

当字符串长度超过char设定长度时,会自动从开头截取指定长度的字符串存储,当字符串长度小于char设定长度时,会在尾部自动补齐缺少的长度个空格
好,接下来再看下与字符串相关的函数,我们在官网上可以查到PG与字符串相关的操作函数和操作符:
首先放上链接,函数和操作符太多,先有个整体浏览:
https://www.postgresql.org/docs/current/functions-string.html
我们只取其中不太好理解的几个函数试下,未详细介绍的基本上跟Java或者C#这些开发语言中字符串提供的功能类似,类比理解一下即可。
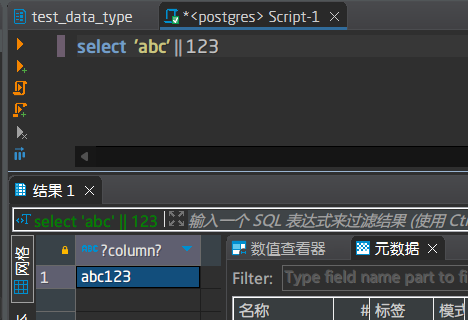
输入:2个文本
输出:合并后的文本

输入:1个文本和一个非文本
输出:合并后的文本
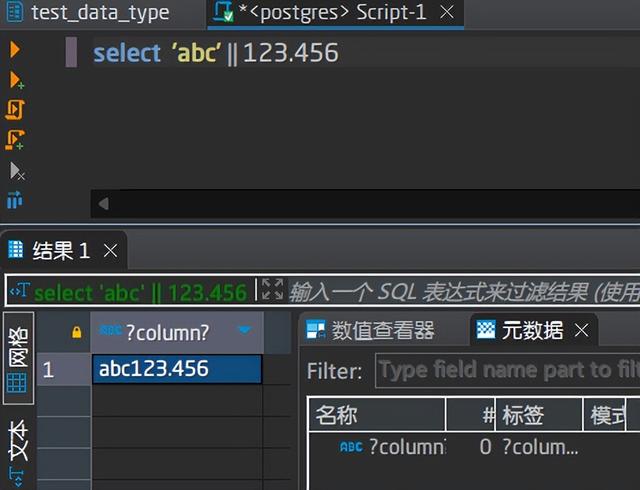
和日期做拼接:
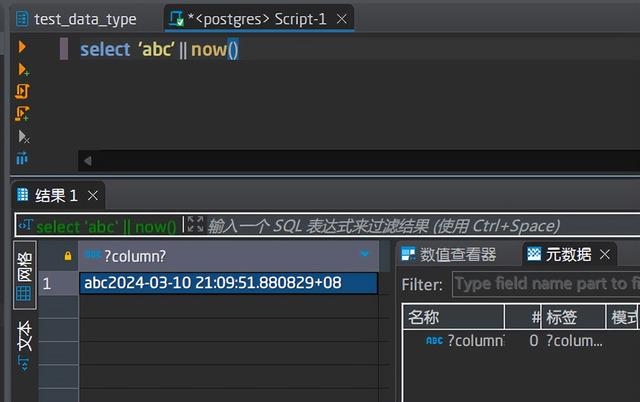
日期后面再详细介绍,这里了解一下其输出格式即可
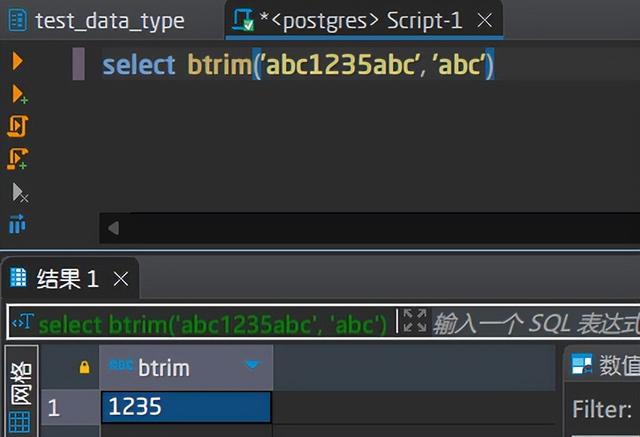
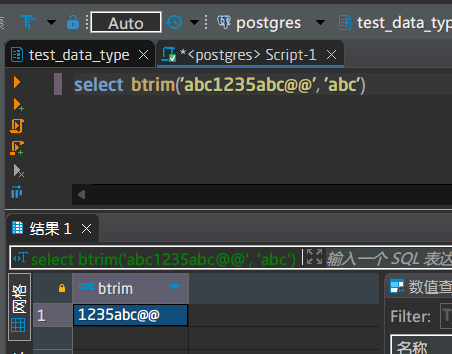
输入:第1个为要进行抽取的字符串,第2个为要从第1个字符串中移除的字符串。注意:字符串只去开头和结尾,如果开头和结尾找不到该字符串,则不会移除任何字符串
输出:移除开头和结尾匹配第2个参数后的字符串
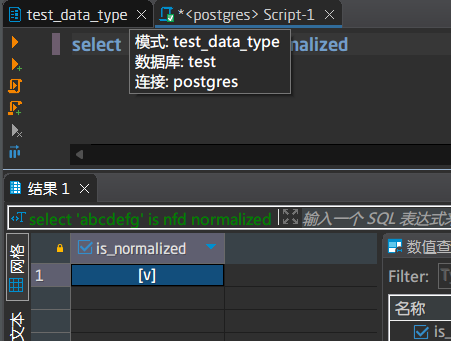
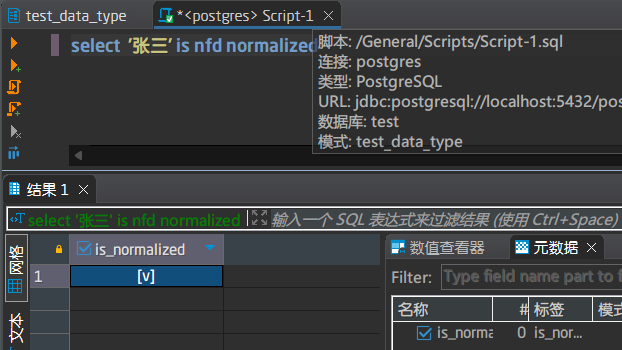
判断一个字符串是不是已经做了特定编码
输入:一个字符串,后面 is normalized是必须的,可以加上not和form表示的特定的编码格式
输出:如果与指定的编码匹配,则返回true,否则返回false
注意: 这个操作只有在服务器编码为UTF-8的情况下才有用,其它情况下返回值没有任何参考意义
说明:form表示的标准化形式有NFC、NFD、NFKC、NFKD,是Unicode 标准化形式的四种不同形式,便于在比较、搜索和其他文本处理任务中能够准确地识别等价字符串。NFC和NFD是一对,NFKC和NFKD是一对,C表示组合,D表示分解,带K表示兼容,这部分需要详细阐述,有机会可以再单独发一篇记录一下
举几个例子先有个印象:
输入:1个文本
输出:文本中包含的位数,注意是位的个数

abc是3个字符,一个字符用8位表示,因此是24位

张三是中文字符,一个字符在PG里面用unicode表示要用3个字节,也就是3*8=24个字节表示,因此总共占用48个位
也叫character_length ( text ) → integer
输入:1个文本
输出:字符的个数,不区分中文和字母

包括特殊符号,如@等,也是当作一个字符处理
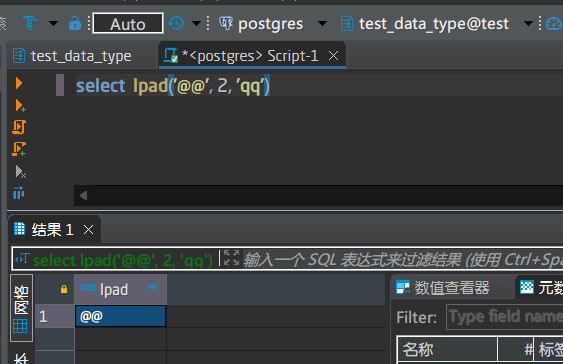
输入:第1个为原始文本,第2个为填充后的文本长度,第3个为要填充的文本
输出:长度为第2个参数表示的长度的文本
情形一:如果长度和第1个原始文本的长度要相等,则不做填充操作
情形二:如果长度比原始文本长度小,则将原始文本从右边开始截取,保留长度为第2个参数的字符串
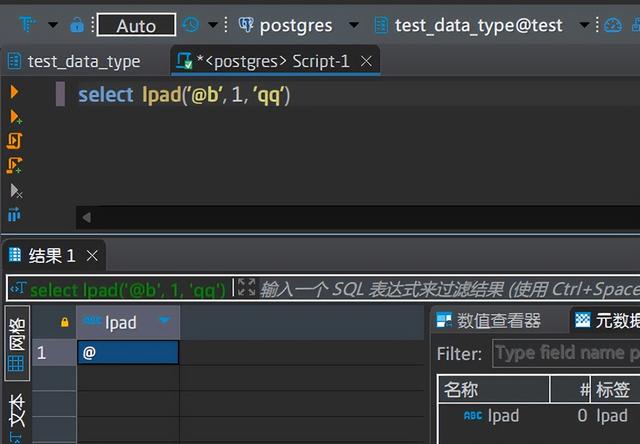
情形三:如果长度比原始文本长,则用第3个填充字符串填充
填充字符串按从左至右的顺序依次循环填充到原始字符串的开头,直到达到第2个参数指定的长度要求,如果要填充的个数不是填充字符串的整数倍,填充方式是从填充字符串的左边开始取满足长度要求的字符串即可
不太好理解,举个例子就明白了
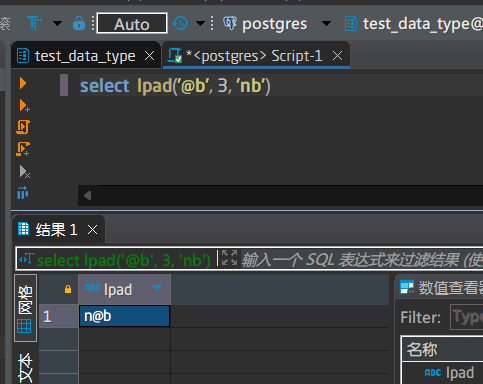
原始长度为2,填充后长度为3,只需要填充一个字符,因此从填充字符串中从左至右取1个字符填充即可,即在开头加一个n
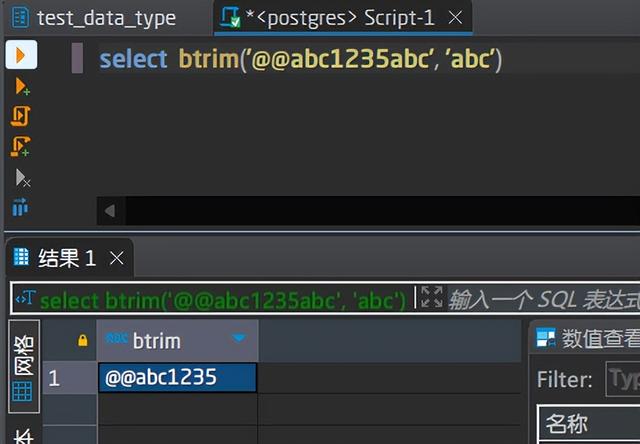
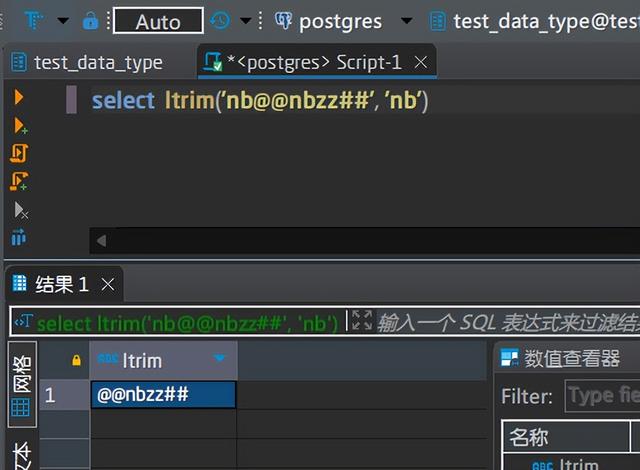
输入:第1个表示原始文本,第2个表示要从原始文本中抠除的字符集合
输出:抠除原始文本中出现的第2个文本后得到的文本。注意,这里只抠除原始字符串开头的文本,可以和btrim对比看下

输入:第1个参数表示原始文本,第2个参数表示4个Unicode标准形式(NFC、NFD、NFKC、NFKD),先不详述,与上面的text IS [NOT] [form] NORMALIZED → boolean是一对
输出:转换后标准形式的字符串编码
同样要注意PG服务器的编码是Unicode这个前提
输入:原始文本
输出:文本包含的字节数。与bit_length对比着看下。2个函数的关系就是octet_length * 8 = bit_length
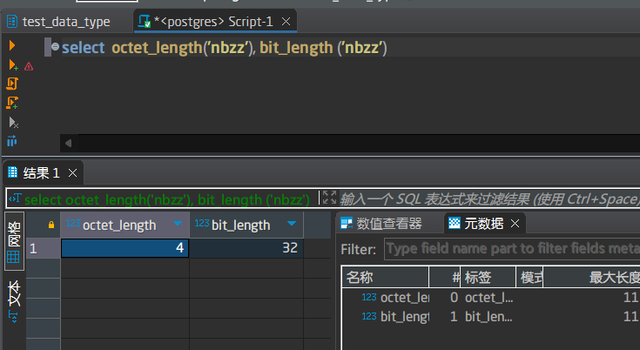
注意与octet_length ( text )在数据类型上的区别,因为character默认是1个字符,我们也只可以指定长度
输入:转换成char类型的原始文本
输出:转换后的文本长度

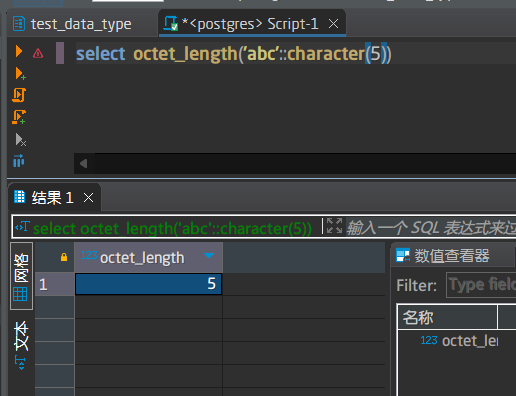
这里注意:默认时候转换只保留了1个字符,而转换成5个字符的时候,我们前面说过会在尾部填充直到有5个为止.octet_length会识别文本参数的类型是text还是char来决定调用哪个形参的方法
输入:第1个参数为原始文本,第2个表示原始文本中要进行替换的起始位置,从1开始计算而不是0,第2个表示从替换的起始位置开始要替换的字符个数,第4个表示进行替换的字符串
输出:从开始位置删除指定长度的字串,用填充串替换后得到的新字符串
看示例:

同样,如果填充的个数不是填充字符串的整数倍,会发生什么情况
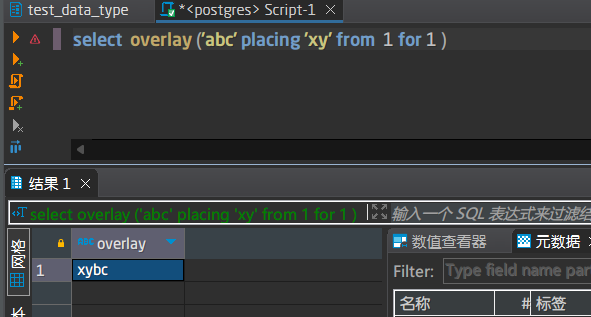
所以这里不存在lpad的问题,这个函数意思就是,你告诉我原始文本从哪开始,截几个,我把这段文本删除了,换成填充字符串即可
输入:第1个表示要查找的子串,第2个表示原始文本
输出:子串第一次出现的位置,从1开始,如果找不到,返回值为0
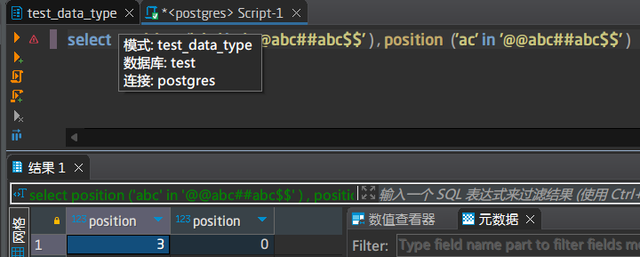
与lpad类似,这文档组织还可以优化,放到lpad下面,读者会更方便看一点。西方的思维方式确实和东方的不太一样。
输入:第1个参数是原始文本,第2个是填充后的文本长度,第3个是填充字符串,
输出:填充后达到指定长度的新字符串,原理参照lpad,这里只举例子:
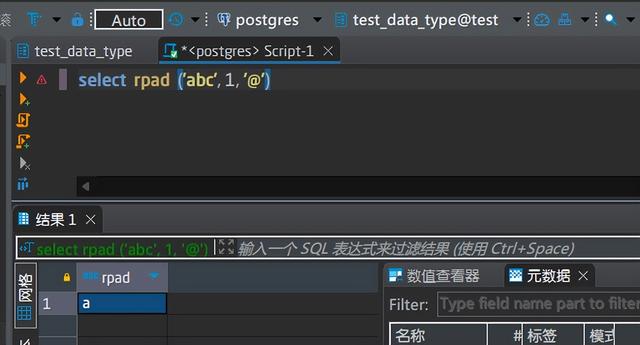


与ltrim类似,只不过这里是从后面开始截取
输入:第1个参数表示原始文本,第2个表示要截取的字符串
输出:截取完后的字符串
直接用官方提供的示例,很直接

好了,今天先写这么多,还有不少函数,难倒不是多难,只不过细节多,这也是做软件工程里面特别要注意的一个方面,往往找不到问题的原因就是漏掉或者不清楚某个细节
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号