ChatGPT模型疯狂训练背后的秘密
发表时间: 2024-06-19 12:50
原文标题:Will We Run Out of Data? Limits of LLM Scaling Based on Human-Generated Data
原文作者:Pablo Villalobos, Anson Ho, Jaime Sevilla, Tamay Besiroglu, Lennart Heim, Marius Hobbhahn
原文来源:Epochai
编译:AIGC开放社区
AI发展科研机构Epochai在官网发布了一项,关于大模型消耗训练数据的研究报告。
目前,人类公开的高质量文本训练数据集大约有300万亿tokens。但随着ChatGPT等模大型的参数、功能越来越强以及过度训练,对训练数据的需求呈指数级增长,预计将在2026年——2032年消耗完这些数据。
研究人员特别提到了“过度训练”(Overtraining)是加速消耗训练数据进程的主要原因之一。例如,Meta最新开源的Llama 3的8B版本过度训练达到了惊人的100倍,如果其他模型都按照这个方法来训练,数据可能在2025年就消耗尽了;70B版本还好,过度训练只有10倍。
所以,无论是闭源还是开源大模型,已经进入比拼训练数据的阶段,谁的模型学习的数据更多、维度更广,即便是小参数同样可以战胜大参数模型,尤其是在RAG、MoE、MTL等加持下效果更明显。

过度训练是在深度学习领域,特别是在大模型的训练过程中,开发者有意让模型使用的训练数据量超过计算最优模型所需的量。这种做法与传统的机器学习中避免过拟合的目标不同。
过拟合发生在模型过于复杂或者训练时间过长,以至于模型开始记忆训练数据中的噪声而非泛化到未见数据。但在大模型的过度训练是一种优化策略,可以节省推理成本和效率,同时模型开始学习训练数据中的噪音和细节,而不是潜在的数据分布。
这就像学生学习历史一样,如果只记住大量的日期和事件,而没有理解它们之间的联系和意义,在面对新的问题或需要综合分析时,可能无法给出准确的逻辑答案。
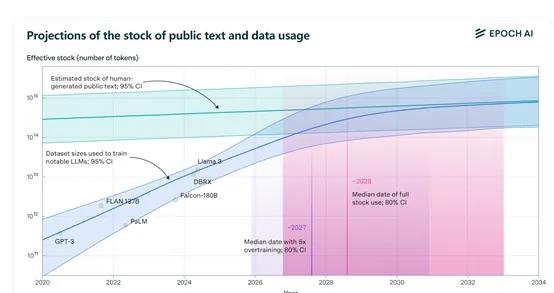
此外,大模型过度训练意味着参数量与训练数据量的比例超过了Chinchilla缩放定律建议的最佳比例大约D/N比为20。
在Chinchilla缩放定律下,保持这个比例可以使得模型在固定的训练计算预算下达到最低的可减少损失。不过开发者可能会选择让这个比例高于最优值,会让模型使用更多的数据来训练。
这样做虽然会增加训练阶段的数据需求,但能够减少模型在推理阶段的算力成本。因为相对于昂贵GPU,训练数据就便宜的多,尤其是在超大规模参数模型中的收益更明显。
Meta最新开源的Llama 3系列模型是过度训练的典型,GPT-3、Flan137B、Falcon-180B等模型也都存在这一现象。
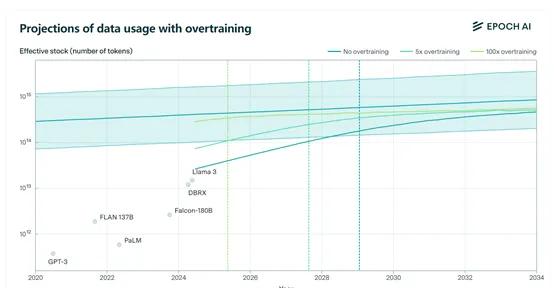
如果保持在5——10倍的过度训练量,训练数据的消耗度还在可控范围之内,如果在100倍以上,将呈指数级增长,而Llama 3的8B版本过度训练就已经达到100倍。
在大模型领域,训练数据已经和AI算力一样变得非常重要,是决定模型性能的关键元素之一。虽然可以再生,但消耗速度过快可能会盖过生成速度出现无数据可用的局面。Epoch ai给出了以下4种获取训练数据的新方法。
1)合成数据:合成数据主要利用深度学习来模拟真实数据,来生成全新的数据。这种方法在数据短缺的情况下显得尤为重要,因为提供了一种潜在的无限扩展数据集的方式。目前,很多科技巨头已经在使用这个方法,不过也有很大的弊端。
合成数据的质量可能会比较差并出现过拟合行,这是因为在合成的过程中无法完全捕捉到真实数据的复杂性和多样性。
例如,合成数据可能缺乏真实文本中的某些细微的语言特征,或者可能过于依赖模型训练时使用的特定数据集,导致生成的文本缺乏多样性。此外,合成数据可能会引入一些新的偏差,这些偏差可能会影响模型的性能。
2)多模态和跨领域数据学习:多模态学习是一种涉及多种数据类型的学习方法,它不仅限于文本,还包括图像、视频、音频等多种形式的数据。通过结合不同模态的信息,可以更全面地理解和处理复杂的任务。
例如,GPT-4o、GPT-4V、Gemini等可以同时处理文本描述和相应的图片,以更好地理解场景和语境。这也是目前多模态大模型的主要训练数据方法之一。
此外,开发者也可以将目光投向其他领域,例如,金融市场数据、科学数据库、基因数据库等。根据预测,基因领域的数据增长每年保持在几百万亿甚至上千万亿,可以产生源源不断的真实数据。
3)私有数据:根据Epoch ai调查数据显示,目前全球文本数据包含私有总量大概在3100万亿tokens。而公开数据只有300万亿,也就是说还有90%的私有数据可以使用。
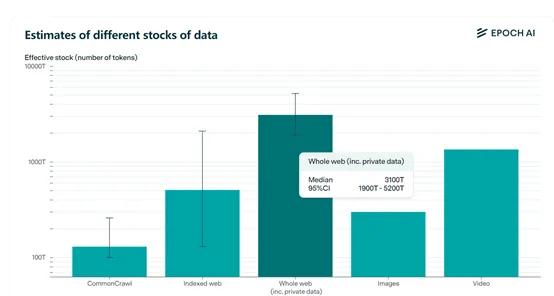
目前,已经有科技公司开始从这方面下手,例如,OpenAI成立了一个“数据联盟”专门搜集高质量、没公开过的私有数据,在训练GPT系列和最新的前沿模型。
但使用私有数据很有难度,首先,隐私和安全性是最大的顾虑,非公共数据往往包含敏感信息,如果用于模型训练,可能会引发隐私泄露的风险。例如,社交媒体上的私人对话、个人邮箱中的通信记录,这些都是用户不希望被公开的数据。
其次,获取和整合非公共数据的过程可能非常复杂。与公共数据相比,非公共数据分散在不同的平台和系统中,缺乏统一的标准和格式。这就需要开发新的技术和方法来收集、清洗和标准化这些数据,以便它们能够被有效地用于大模型训练
4)与真实世界实时交互学习:可以让模型通过与真实世界的直接互动来学习和进步。与传统的基于静态数据集的训练方法不同,这种学习方法强调的是大模型的自主性和适应性。在这种模式下,模型不仅仅是被动地接收数据,而是主动地探索环境,通过与人类交互来获得知识和技能。
但这种方法对模型的架构、性能、算力要求较高,需要具备一定的自主性和决策能力。大模型需能够准确理解用户输入的指令或问题,并根据这些指令在现实世界中采取行动。
例如,大模型可能需要根据用户的请求来推荐餐厅,这不仅需要它理解用户的偏好,还需要它能够访问和分析实时的餐厅信息。
此外,与真实世界互动的学习还需要模型具备处理不确定性的能力。现实世界是复杂多变的,充满了不确定性和偶然性。
模型需要能够适应这些不确定性,从不断变化的环境中学习并做出合理的决策。这就涉及到概率推理、风险评估和决策制定等高级认知功能。

企业、开发者们珍惜训练数据吧,就像我们珍惜水资源一样。不要等着枯竭的那一天,望着荒漠干流泪。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号