云原生技术助力实现“数据库大数据一体化”,鱼与熊掌兼得
发表时间: 2020-10-26 15:26
允中 发自 凹非寺
量子位 编辑 | 公众号 QbitAI
10月23日数据湖高峰论坛上,阿里巴巴集团副总裁、阿里云智能数据库产品事业部负责人、达摩院数据库与存储实验室负责人李飞飞表示:“云原生作为云计算领域的关键技术与基础创新,正在加速数据分析全面进入数据库大数据一体化时代”。

△ 阿里巴巴集团副总裁、阿里云智能数据库产品事业部负责人李飞飞
他表示,随着数字化转型进程深入推进,企业的数据存储、处理、增长速度发生了巨大的变化,传统数据分析系统在成本、规模、数据多样性等方面面临很大的挑战。云计算的发展正在加速推进数据分析系统进入“数据库大数据一体化”时代,以更好得帮助企业加速迈入数字原生时代加速业务数智化。
近年来,企业数据需求呈现出海量、数据类型多样化、处理实时化、智能化等新特点,对数据分析系统提出了弹性扩展、结构化/半结构化/非结构化海量数据存储计算、一份存储多种计算及低成本等核心诉求。
而传统商业化数据仓库及大数据技术,因存在扩展性、建设维护成本、系统复杂读等一系列挑战,无法很好得满足业务诉求。例如,大量企业需要对数据进行离线ETL计算、机器学习及多维度查询分析等多种计算时,使用大数据技术或传统数据仓库,企业需要组合使用多种技术产品,通过复杂的数据集成、数据冗余来满足多样的计算诉求,整个技术架构复杂且数据冗余成本高。
针对企业面临的分析困境,是否有一种新型数据分析技术和架构能够高效解决海量数据深度计算分析的业务诉求?答案是肯定的,李飞飞表示,下一代数据分析演进方向是“以云原生为基础,在离线一体化技术融合,实现数据库大数据一体化”。
随着云计算的发展,计算存储解耦、资源池化、Serverless、流批一体等核心基础技术正在加速数据分析系统向“数据库大数据一体化”演进。“数据库大数据一体化”的云原生数据分析系统能够很好得提供弹性扩展、海量存储、多种计算及低成本等能力,有效解决海量数据深度计算分析的业务分析和创新诉求。
其实,“数据库大数据一体化”也是业界近年的发展趋势,Gartner及业界多个产品都在朝这个趋势演进:
同时,2019年6月,全球知名咨询公司Gartner发布了一篇名为“There is only one DBMS Market“的报告,报告指出过去,因为性能需求不同,根据业务场景按照分析型和交易型需求,需要独立发展OPDBMS和DMSA,而未来分析型和交易型数据操作对技术架构依赖性会更小,将不再需要独立区分OPDBMS和DMSA,未来通过一体化的数据处理技术即可满足绝大部分诉求。
从技术架构演进过程来看,数据处理发展经历了四个重要阶段:
李飞飞表示,“数据库大数据一体化”的数据分析系统应该具备如下特征:
1、云原生,数据分析系统需要支持强大的弹性扩展能力,根据业务负载动态扩展计算资源,提供大规模数据处理能力,有效满足数据分析性能诉求的同时,降低分析成本。
2、一份存储多种计算,数据分析系统必须支持在一份存储数据上兼容多种计算,包括实时增删改查、多维度交互式分析、离线ETL及机器学习。通过一份存储支持多种计算的特性,避免了数据计算过程中的数据搬迁,简化了数据分析过程,降低分析成本。
3、海量存储,支持结构化、半结构化及非结构化数据库的存储及计算。随着IOT/移动网络的发展,半结构化/非结构化数据占比越来越高,数据分析系统需要支持这些数据的低成本存储及计算,助力企业充分挖掘并发挥数据价值。
4、全面兼容数据库生态,数据分析系统需要提供并兼容数据库接口协议,且支持数据库上下游生态,降低数据分析门槛,让开发人员会数据库就会大数据。
基于“数据库大数据一体化”的演进趋势,阿里云推出了以云原生数据仓库AnalyticDB及云原生数据湖分析DLA为核心的云原生数据分析系统。深度融合数据库及大数据技术,为企业提供一体化的数据接入、数据存储、数据计算及数据分析解决方案,让会数据库的用户就会大数据。
为满足企业计算分析多元化的诉求,阿里云于2013年开始研发并推出云原生数据仓库AnalyticDB。基于云构建,秉承“数据库大数据一体化”的理念,AnalyticDB为用户提供了新一代的数据分析系统,有效解决当前企业数据分析痛点。AnalyticDB具备如下优势:
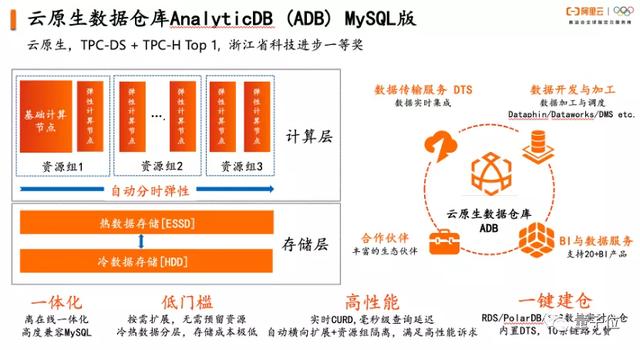
与传统数据分析系统最大的不同是,AnalyticDB基于“数据库大数据一体化”的技术架构,为用户提供一体化的数据分析系统,满足多样化的数据分析诉求,让开发人员会数据库就会大数据。

近几年数据湖的概念很火,数据湖允许以任意规模存储所有结构化、非结构化及半结构化数据,其中的数据主要用于报告、可视化、增强分析及机器学习等场景。为了实现数据湖的数据可分析,需要解决数据湖构建、元数据构建管理及数据计算引擎对接等问题。为此,阿里云2018年开始布局并推出端到端的数据湖解决方案:云原生数据湖分析Data Lake Analytics(简称:DLA),帮助企业快速构建并高效挖掘数据。

云原生数据湖分析DLA,具备四大优势:
阿里云AnalyticDB与DLA自上线以来,已覆盖游戏、广告、文旅、零售、金融、数字政府、运营商等众多行业的企业客户,且覆盖阿里巴巴集团的所有核心业务。据介绍,Yeahmobi利用DLA进行广告业务数据的深度挖掘分析,实现时间、成本、安全、计算效率等方面的优化,综合成本降低大约50%。某大型物流企业,通过AnalyticDB构建企业数据仓库,实现离在线一体化分析架构,支持 2PB数据的存储计算,分析性能大幅提升10倍,实现分析实时化。
未来数据分析系统将全面进入“数据库大数据一体化”时代,阿里云AnalyticDB及DLA将秉承“数据库大数据一体化”理念,持续打造云原生、一体化的数据分析能力,助力企业加速迈入数字原生时代。
— 完 —
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号