下一代测序工具开发:Go、Java、C++,谁更胜一筹?
发表时间: 2020-05-03 17:14

作者 | Pascal Costanza, Charlotte Herzeel & Wilfried Verachtert
译者 | 弯月,责编 | 夕颜
出品 | CSDN(ID:CSDNnews)

简介
背景介绍
我们有一个成熟的多线程框架:elPrep,用于在测序流水线中准备SAM和BAM文件。为了获得良好的性能,我们的软件体系结构希望一次通过一个SAM/BAM文件执行多个准备步骤,并尽可能地将测序数据保留在主存储器中。与其他SAM/BAM工具类似,elPrep中堆的内存管理是一项复杂的任务,而且在近期的开发中,这个问题成为了该项目实现编程语言中严重的生产力瓶颈。因此,我们研究了三种可以替代的编程语言:首先是Go和Java(使用并发以及并行垃圾回收器),还有C++ 17(使用引用计数来处理大量堆对象)。我们用这三种语言重新实现了elPrep,并分别测试了运行时的性能和内存使用。
结果
Go实现的性能最佳,可在运行时性能和内存使用之间达到最佳平衡。尽管Java基准报告的运行时间比Go快一些,但运行Java的内存使用量明显偏高。C++ 17的运行速度明显慢于Go和Java,而且使用的内存却比Go还要多。我们的分析表明,对于我们这种情况来说,与引用计数相比,通过并发以及并行垃圾回收管理大量对象的效果更好。
结论
根据我们的基准测试结果,我们选择Go作为新的elPrep实现语言,而且我们认为Go是开发其他处理SAM/BAM数据生物信息学工具的理想选择。

背景介绍
序列比对/映射格式(SAM / BAM)是生物信息学界存储映射测序数据的标准。分析SAM/BAM文件的工具有很多。Broad和Sanger研究所开发的SAMtools、Picard以及Genome Analysis Toolkit(GATK)软件包被视为SAM/BAM文件许多操作的参考实现。这些操作包括读取排序、标记聚合酶链反应和光学复制、重新校准基质量得分、插入缺失重新排列以及各种过滤选项。
很多替代软件包专门提供这些操作的优化,这些软件包或提供替代算法,或使用并行化、分布或其他特定于实现语言(通常是C、C++或Java)的优化技术。
我们开发的elPrep是一个开源的多线程框架,用于在测序流水线中处理SAM/BAM文件,专门为优化计算性能而设计。它可以代替SAMtools、Picard和GATK实现的许多操作,而且还会产生相同的结果。elPrep允许用户通过一个命令在一个流水线中指定任意组合的SAM/BAM操作。然后,elPrep独特的软件体系结构可确保无论你指定了多少操作,运行这样的流水线时只需传递一次SAM/BAM文件。该框架能够合并和并行执行操作,明显加快流水线的整体执行速度。
虽然我们并没有将精力集中在优化单个SAM/BAM操作上,但结果表明,我们合并操作的方法更优。例如,与使用GATK4相比,elPrep执行4个步骤的广泛最佳实践的速度提高了13倍,整个基因组数据的处理速度提高了7.4倍,而耗费的计算资源则更少。
大多数编程语言都包含类似的通过显式或隐式分配内存存储堆对象的方法,堆对象与堆栈值不同,并不局限于函数或方法调用的生命周期。然而,各个编程语言在如何重新分配堆对象的内存方面有很大不同。
简单来说,主要有三种方法:手动管理内存必须在程序源代码中显式释放内存(例如,在C中调用free)。垃圾回收内存由运行时库中单独的组件(称为垃圾收集器)自动管理。在任意时间点,它都需要遍历对象图,以确定正在运行的程序仍可直接或间接访问哪些对象,并回收不可访问的对象占用的内存。使用这种方法时不必明确地针对对象生命期进行建模,并且可以在程序中更自由地传递指针。大多数垃圾回收器实现都会中断正在运行的程序,然后在垃圾回收完成后继续执行,并使用顺序算法执行对象图遍历。
然而,Java和Go所采用的高级实现技术可以在运行程序的同时遍历对象图,尽可能减少中断,并使用多线程并行算法加速现代多核处理器上的垃圾收集。引用计数通过维护每个堆对象的引用计数来管理内存。每当发生指针分配时,引用计数就会根据每个对象引用的指针数目相应的增加或减少。每当引用计数降至零时,就释放对应的对象。
elPrep最初(直到2.6版)是使用Common Lisp编程语言实现的。大多数现有的Common Lisp实现都使用会中断应用程序的顺序垃圾收集器。为了获得良好的性能,我们有必要明确控制垃圾收集器运行的频率和时间,以避免不必要地中断主程序,尤其是在并行阶段。因此,我们还必须避免不必要的内存分配,并尽可能重用已分配的内存,以减少垃圾收集器运行的次数。
然而,我们最近在尝试为elPrep添加更多功能(例如光学重复标记、基本质量得分重新校准等)时,需要为这些新步骤分配额外的内存,于是情况更加复杂,并且保持内存分配和垃圾回收检查成为了严重的生产力瓶颈。因此,为了继续开发elPrep并实现良好的性能,我们开始寻找其他拥有不同的内存管理方法的编程语言。
现有关于比较编程语言及其实现性能的文献通常都会使用特定的算法或内核,而根本不关心这些语言是否涵盖特定领域,如生物信息学、经济学或数值计算,还是只与编程有关的一般编程语言。仅有一篇文章考虑了并行算法。比较编程语言性能的在线资源也将重点放在特定的算法或内核上。elPrep的性能不仅来自并行排序或并发重复标记等步骤的高效并行算法,还源于将这些步骤整理成单通道、多线程流水线的整体软件架构。
由于现有的文献未涵盖此类软件体系结构,因此在本文中我们进行了一番研究。
elPrep是一个开放式软件框架,允许流水线中不同功能步骤的任意组合,例如重复标记、读取排序、替换读取组等;另外,elPrep还提供了编写第三方工具的功能步骤。这种开放性导致很难在程序运行期间准确地确定分配对象的生存周期。众所周知,在开发此类软件框架时,手动管理内存会导致生产力极其低下。例如,IBM的旧金山项目,从手动管理内存的C++转换到拥有垃圾回收的Java后生产力提高了大约300%。其他处理SAM/BAM文件的开放式软件框架包括GATK4、Picard以及htsjdk。
因此,手动管理内存对elPrep来说并不实际,而且并发、并行的垃圾回收和引用计数是唯一的选择。我们希望选择能够得到社区长期支持的成熟编程语言,最后我们发现Java和Go是唯一支持并发以及并行垃圾回收的编程语言,而C++则采用引用计数。
我们的研究包括使用C++ 17、Go和Java中重新实现elPrep,并对运行时的性能和内存使用进行基准测试。这些都是非常成熟的编程语言,从某种意义上说,它们完全支持各种调用的常见准备流水线工作,包括读取排序、重复标记和其他一些常用步骤。尽管elPrep的这三种重新实现仅支持有限的功能集,但在每种情况下,我们都可以通过额外的努力来完善软件体系结构,以支持elPrep 2.6版及更高版本的所有功能。

结果
我们使用elPrep的软件体系结构,以选定的三种编程语言运行了一条常见的准备流水线工作,结果表明Go实现的性能最佳,其次是Java实现,最后是C++ 17实现。
为了确认这个结果,我们针对全基因组测序数据集执行了五步准备流水线。该准备流水线包括以下步骤:
通过排序读取调整顺序
删除未映射的读取
标记重复读取
替换读取组
重新排序和过滤序列字典
我们针对每个实现,运行了30次该流水线作业,并使用Unix time命令记录了每次运行所耗费的时钟时间和最大内存使用量。此外,我们还确定了每组运行的标准偏差和置信区间。
C++ 17和Java允许对内存管理进行细致的调整,因此各自产生了四种变化。在最终排名中,我们挑选出了每种变化的最佳结果,一个是C++ 17的变化,一个是Java的的变化。Go的基准测试是使用默认设置执行的。
三种实现的运行时性能的基准测试结果如下图所示。Go平均需要7分56.152秒,标准偏差为8.571秒;Java平均需要6分54.546秒,标准偏差为5.376秒;C++ 17平均需要10分23.603秒,标准偏差为22.914秒。Go和Java的置信区间非常窄,而C++ 17的置信区间稍微宽一些。
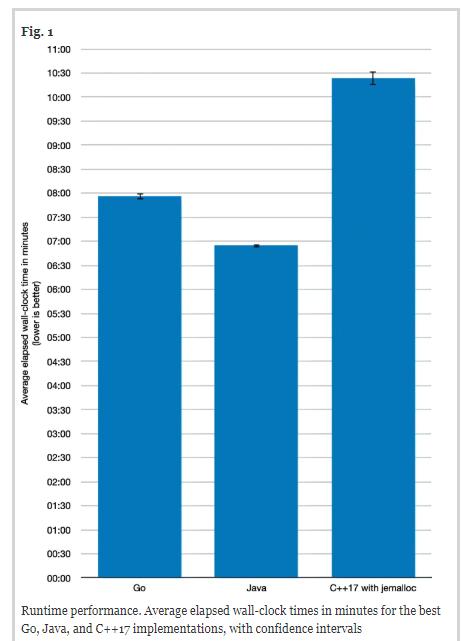
关于最大内存使用情况的基准测试结果如下图所示。Go平均需要221.73GB,标准偏差为6.15GB;Java平均需要大约335.46GB,标准偏差为 0.13GB;而C++ 17平均大约需要 255.48GB,标准偏差约为 2.93GB。置信区间非常窄。
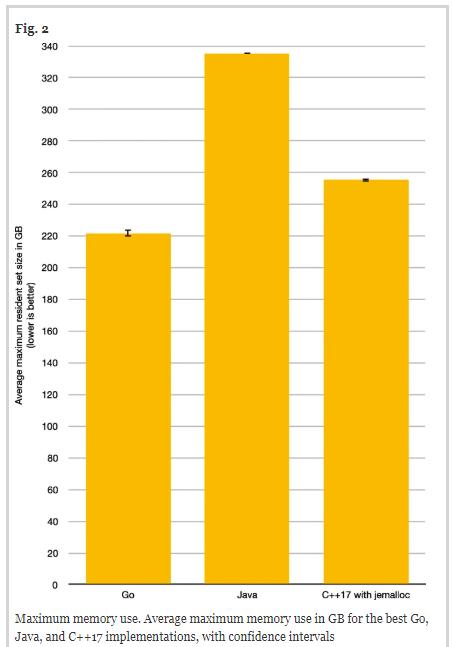
elPrep的目标是同时降低运行时间和内存使用。因此,为了确定最终排名,我们用实际流逝的时间(以小时h为单位) 乘以平均最大内存使用量(以千兆字节GB为单位)。最后得出的结果如下图所示(千兆字节小时,GBh的值越低越好):
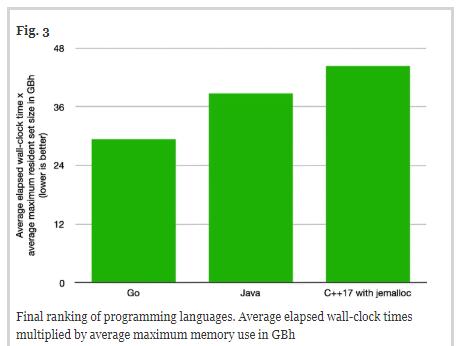
Go:29.33GBh
Java:38.63GBh
C++ 17:44.26 GBh
这从一定程度上反映了基准测试的结果:尽管Java基准测试报告的运行时间比Go基准测试快一些,但Java的内存使用量明显偏高,因此Java的GBh值高于Go。C++ 17的运行速度比Go和Java慢很多,这也就是解释了为什么C++ 17在报告中得出的GBh值最高。因此,我们认为Go是最佳选择,它在运行时性能和内存使用之间实现了最佳平衡,其次是Java,最后是C++ 17。

讨论
关于elPrep中内存管理的细节
在elPrep的所有步骤中,最常见的用例是执行读取排序和重复标记。这样的流水线分两个阶段执行:在第一个阶段,elPrep读取BAM输入文件,将读取的条目解析为对象,并即时执行重复标记和一些过滤步骤。一旦所有读取都作为堆对象存储在RAM中后,就使用并行排序算法对它们进行排序。然后,在第二个阶段,将修改后的读取转换回BAM输出文件的条目并回写。elPrep将读取的处理分为两个阶段,因为只有在完全掌握重复项,并在RAM中排序读取项后,才能将读取回写到输出文件。
第一个阶段分配各种数据结构,同时将BAM文件中的读取表示形式解析为堆对象。在第一个阶段完成之后,这些对象的子集就被淘汰了。上述“背景介绍”提到了如何以不同的内存管理方法处理这些临时的对象。
垃圾收集器需要花费时间,将这些过时的对象分类到不可访问,并回收为其分配的资源。中断应用程序的顺序垃圾回收器会导致严重的停滞,而且在停滞期间主程序无法进行。以前的elPrep版本(直到2.6版)就属于这种情况,因此我们为用户提供了一个选项,可以在这些版本中完全禁用垃圾收集。而并发并行垃圾收集器可以与在第二个阶段同时执行垃圾收集的工作,因此可以立即执行。
使用引用计数时,每当对象的引用计数降至零,该对象就会被列入淘汰之列。回收为这些对象分配的资源会引发一连串其他对象的资源回收,因为这些对象的引用计数也会间接地降至零。因为这是一个固有的顺序过程,所以也会导致与中断应用程序垃圾回收器类似的重大停滞。
关于C++ 17性能的细节
在大多数特定的算法或内核的基准测试中,C和C++的性能通常都会超越其他编程语言。由于elPrep的C ++17实现使用引用计数,因此引用计数引发的一连串资源回收会造成停滞,最终导致性能降低,如上一小节所述。
为了验证该理论,我们分别测量了C++ 17实现中每个阶段耗费的时间以及回收资源导致的停滞时间,并再次重复执行了30次基准测试,最终确定了耗费时间、标准偏差和置信区间。结果如下图所示。第一阶段平均所需时间为4分26.657秒,标准偏差为6.648秒;回收资源导致的停滞平均耗费2分18.633秒,标准偏差为4.77秒;第二阶段平均所需时间为3分33.832秒,标准偏差为17.376秒。
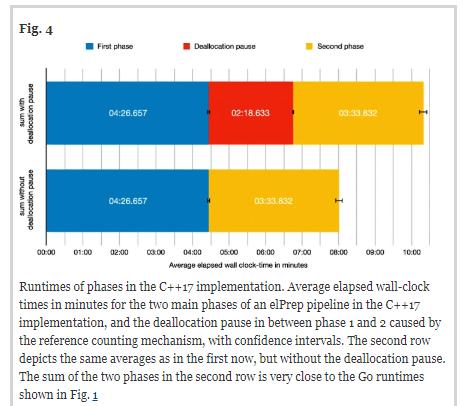
30次C++ 17运行时的平均总和为10分19.122秒,标准偏差为22.782秒。如果我们从平均总运行时间中减去回收资源导致停滞的时间,结果为8分0.489秒,标准偏差为20.605秒。这与Go的基准非常接近——Go的基准平均需要7分56.152秒。因此,我们得出的结论是:导致C++ 17与Go和Java之间的性能差距的罪魁祸首确实是C ++ 17中引用计数机制的资源回收导致的停滞。
除了引用计数之外,C++还提供了许多功能来实现更明确的内存管理。例如,它提供的分配器能够解耦合内存管理与容器中的对象处理。从原则上来说,我们可以使用这种分配器来分配已知的临时对象,而这些对象在上述回收资源导致的停滞期间已被淘汰。因此这种分配器可以被立即释放,从而避免运行时中的停滞。但是,这种方法将需要非常详细且非常容易出错的分析,这些对象不能由此类分配器管理,而且也不能很好地转换到此特定用例之外的其他种类的流水线。由于elPrep的重点是成为开放式软件框架,因此这种方法不切实际。
调整C++ 17中的内存管理
并行C/C ++程序的性能通常会受到C/C++标准库提供的低级内存分配器的影响。我们可以将高级内存分配器链接到程序来减轻这种影响,减少同步、错误共享和内存消耗等。这种内存分配器还可以将大小相似的对象分到不同的组,然后以较大的块进行分配和释放,以有效地处理程序中大量的小规模堆分配。这些技术在垃圾收集的编程语言中也很常见,但是在很大程度上与自动或手动管理内存无关。在我们的研究中,我们使用默认的未经修改内存分配器,因特尔Threading Building Blocks 的 tbbmalloc 分配器、gperftools 的 tcmalloc 分配器以及jemalloc分配器,对C++ 17实现进行了基准测试。结果如下表所示。根据表中的GBh值,jemalloc表现最佳。
分配器 | 平均运行时间 | 平均内存使用量 | 乘积 |
默认的内存分配器 | 16 mins 57.467 secs | 233.63 GB | 66.03 GBh |
tbbmalloc | 16 mins 26.450 secs | 233.51 GB | 63.96 GBh |
tcmalloc | 11 mins 24.809 secs | 246.78 GB | 46.94 GBh |
jemalloc | 10 mins 23.603 secs | 255.48 GB | 44.26 GBh |
调整Java中的内存管理
Java的内存管理提供了许多调整选项。由于elPrep的Java实现使用的平均最大内存明显超过了C++ 17和Go实现,因此我们更详细地研究了如下两个选项:
字符串去重复选项可以在垃圾回收期间识别内容相同的字符串,然后通过让这些字符串共享同一个基础字符数组来消除冗余。由于SAM/BAM文件中的大部分读取数据都由字符串表示,因此使用这个选项似乎有很大的好处。
使用“MinFreeHeap”和“MaxFreeHeap”选项配置垃圾收集后可用堆空间的最小和最大百分比,以最小化堆的大小。
我们使用以下配置分别运行30次Java基准测试:使用默认选项;仅使用字符串去重复选项;仅使用free-heap选项;以及同时使用字符串去重复和free-heap选项。对于free-heap选项,我们遵循Java文档的建议,在不引起性能下降过多的情况下,尽可能降低堆的大小。测量结果如下表所示:free-heap选项对运行时性能或内存使用没有明显的影响,字符串去重复选项导致实际流逝的时间有所增加,但内存使用量有轻微的减少。根据表中的GBh值,Java默认选项的表现最佳。
平均运行时间 | 平均内存使用量 | 乘积 | |
默认选项 | 6 mins 54.546 secs | 335.46 GB | 38.63 GBh |
字符串去重复 | 7 mins 30.815 secs | 338.74 GB | 42.42 GBh |
free-heap选项 | 6 mins 55.842 secs | 335.45 GB | 38.75 GBh |
同时使用字符串去重复和free-heap选项 | 7 mins 25.415 secs | 338.74 GB | 41.91 GBh |

总结
由于Go和Java的垃圾收集器具有并发性和并行性,因此用这两种编程语言重新实现elPrep的执行速度远胜于C++ 17的实现。而且由于Go实现使用的堆内存远低于Java实现,因此我们决定从3.0版开始官方的elPrep使用Go实现。
根据我们的经验,我们建议其他处理SAM/BAM数据生物信息学工具的开发都使用Go语言。
原文链接:
https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-019-2903-5
本文为CSDN翻译文章,转载请注明出处。
☞AI 世界的硬核之战,Tengine 凭什么成为最受开发者欢迎的主流框架?
☞说了这么多 5G,最关键的技术在这里
☞360金融新任首席科学家:别指望AI Lab做成中台
☞AI图像智能修复老照片,效果惊艳到我了
☞程序员内功修炼系列:10 张图解谈 Linux 物理内存和虚拟内存
☞当 DeFi 遇上 Rollup,将擦出怎样的火花?
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12


 鲁公网安备37020202000738号
鲁公网安备37020202000738号