从整体设计角度探讨UI2Code智能生成Flutter代码
发表时间: 2019-02-27 21:00
闲鱼技术-上叶
随着移动互联网时代的到来,人类的科学技术突飞猛进。然而软件工程师们依旧需要花费大量精力在重复的还原UI视觉稿的工作。
UI视觉研发拥有明显的特征:组件,位置和布局,符合机器学习处理范畴。能否通过机器视觉和深度学习等手段自动生成UI界面代码,来解放重复劳动力,成为我们关注的方向。
UI2CODE项目是闲鱼技术团队研发的一款通过机器视觉理解+AI人工智能将UI视觉图片转化为端侧代码的工具。
2018年3月UI2CODE开始启动技术可行性预研工作,到目前为止,经历了3次整体方案的重构(或者重写)。我们参考了大量的利用机器学习生成代码的方案,但都无法达到商用指标,UI2CODE的主要思想是将UI研发特征分而治之,避免鸡蛋放在一个篮子里。我们着重关注以下3个问题的解法:
视觉稿还原精度:我们的设计师甚至无法容忍1像素的位置偏差;准确率:机器学习还处于概率学范畴,但我们需要100%的准确率;易维护性:工程师们看的懂,改的动是起点,合理的布局结构才能保障界面流畅运行。
UI2CODE插件化运行效果,如下视频:进过几轮重构,最终我们定义UI2CODE主要解决feeds流的卡片自动生成,当然它也可以对页面级自动生成。
https://yunqivedio.alicdn.com/od/mm4Te1551157852340.mov
架构设计:
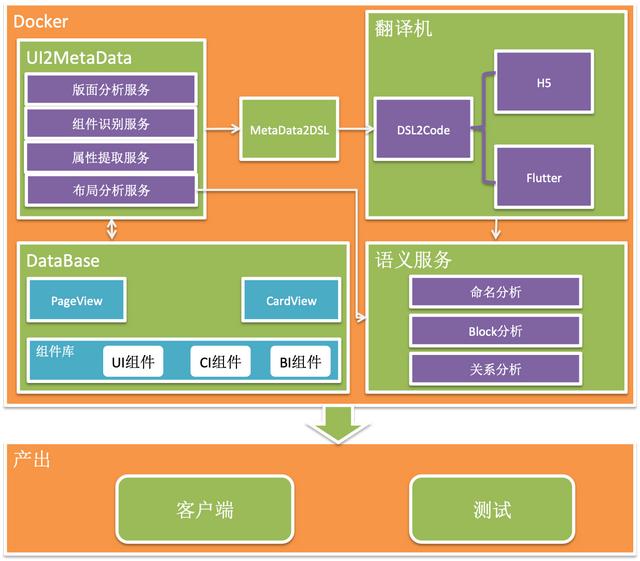
简化分析下UI2CODE的流程:
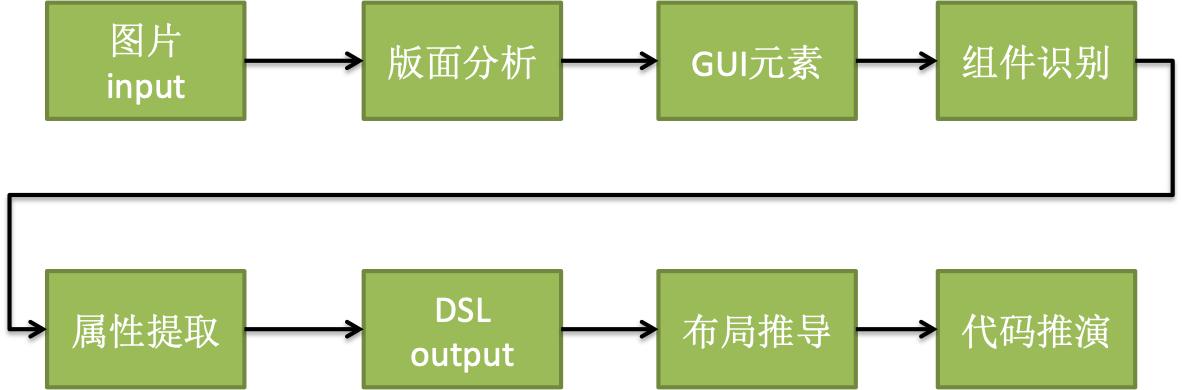
大体分为4个步骤:
1.通过机器视觉技术,从视觉稿提取GUI元素2.通过深度学习技术,识别GUI元素类型3.通过递归神经网络技术,生成DSL4.通过语法树模板匹配,生成flutter代码
版面分析只做一件事:切图。
图片切割效果直接决定UI2CODE输出结果的准确率。我们拿白色背景的简单UI来举例:

上图是一个白色背景的UI,我们将图片读入内存,进行二值化处理:
def image_to_matrix(filename): im = Image.open(filename) width, height = im.size im = im.convert("L") matrix = np.asarray(im) return matrix, width, height得到一个二维矩阵:将白色背景的值转化为0.
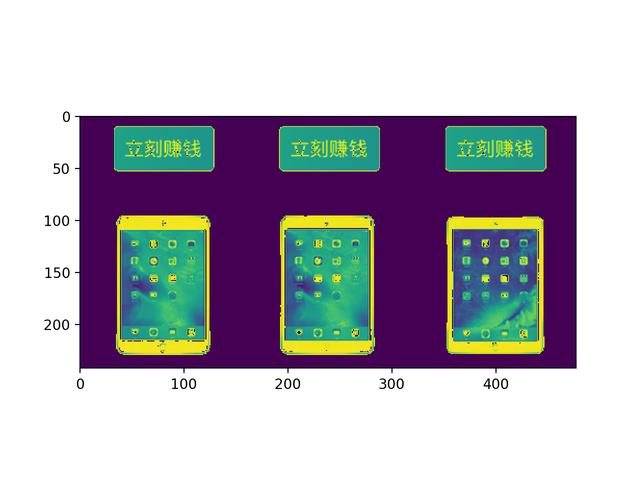
像切西瓜一样,我们只需要5刀,就可以将GUI元素分离,切隔方法多种多样:(下面是横切的代码片段,实际切割逻辑稍微复杂些,基本是递归过程)
def cut_by_col(cut_num, _im_mask): zero_start = None zero_end = None end_range = len(_im_mask) for x in range(0, end_range): im = _im_mask[x] if len(np.where(im==0)[0]) == len(im): if zero_start == None: zero_start = x elif zero_start != None and zero_end == None: zero_end = x if zero_start != None and zero_end != None: start = zero_start if start > 0: cut_num.append(start) zero_start = None zero_end = None if x == end_range-1 and zero_start != None and zero_end == None and zero_start > 0: zero_end = x start = zero_start if start > 0: cut_num.append(start) zero_start = None zero_end = None
客户端的UI基本都是纵向流式布局,我们可以先横切在纵切。

将切割点的x,y轴坐标记录下来,它将是处理组件位置关系的核心。切割完成后,我们获取到2组数据:6个GUI元素图片和对应的坐标系记录。后续步骤通过分类神经网络进行组件识别。
在实际生产过程中,版面分析会复杂些,主要是在处理复杂背景方面。
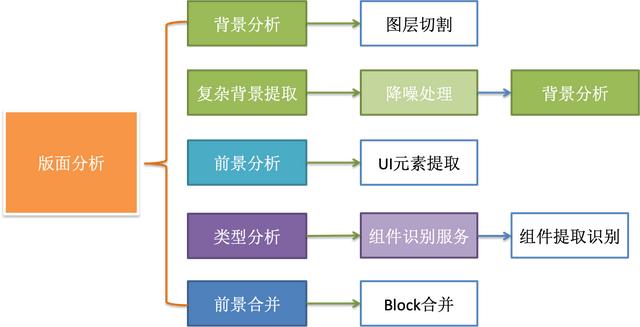
关注我们的技术公众号,我们后续会详细分解。
进行组件识别前我们需要收集一些组件样本进行训练,使用Tensorflow提供的CNN模型和SSD模型等进行增量训练。
UI2CODE对GUI进行了几十种类型分类:IMAGE, TEXT,SHAP/BUTTON,ICON,PRICE等等,分别归类为UI组件,CI组件和BI组件。
UI组件,主要针对flutter原生的组件进行分类。CI组件,主要针对闲鱼自定义UIKIT进行分类。BI组件,主要针对具备一定业务意义的feed卡片进行分类。
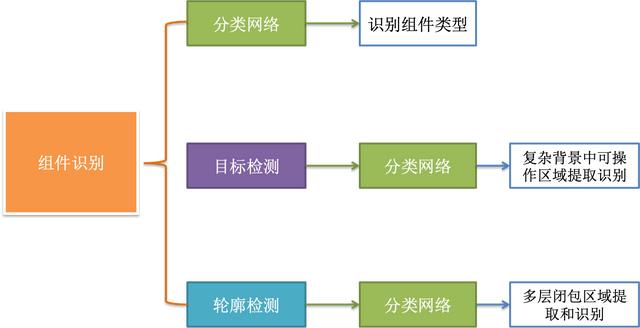
组件的识别需要反复的通过全局特征反馈来纠正,通常会采用SSD+CNN协同工作,比如下图的红色“全新“shape,这该图例中是richtext的部分,同样的shape样式可能属于button或者icon。

这块的技术点比较杂,归纳起来需要处理3部分内容:shape轮廓, 字体属性和组件的宽高。
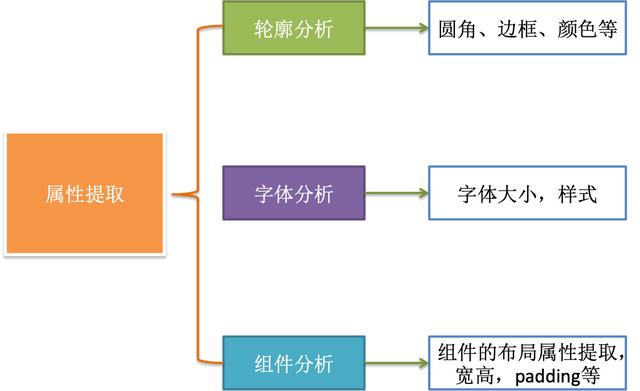
完成属性提取,基本上我们完成所有GUI信息的提取。生成的GUI DSL如下图:
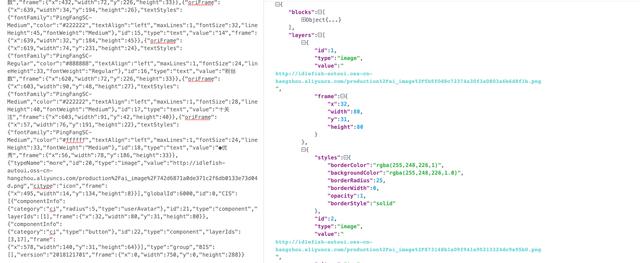
通过这些数据我们就可以进行布局分析了。
其中文字属性的提取最为复杂,后续我们会专门介绍。
前期我们采用4层LSTM网络进行训练学习,由于样本量比较小,我们改为规则实现。规则实现也比较简单,我们在第一步切图时5刀切割的顺序就是row和col。缺点是布局比较死板,需要结合RNN进行前置反馈。
https://yunqivedio.alicdn.com/od/7DD7w1551157938106.mp4
视频中展示的是通过4层LSTM预测布局结构的效果,UI的布局结构就像房屋的框架,建造完成后通过GUI的属性进行精装修就完成了一个UI图层的代码还原工作。
机器学习本质上来说还属于概率学范畴,自动生成的代码需要非常高的还原度和100%的准确率,概率注定UI2CODE很难达到100%的准确率,所以我们需要提供一个可编辑工具,由开发者通过工具能够快速理解UI的布局结构和修改布局结构。
我们将UI2CODE生成的DSL TREE进行代码模板化匹配,代码模板的内容由资深的flutter技术专家来定义,它代表目前我们发现的最优代码实现方案。
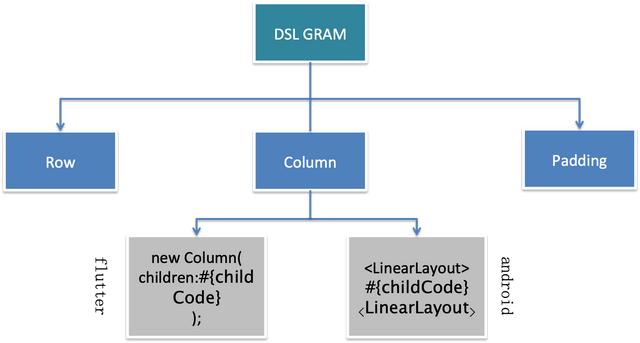
代码模板中会引入一些标签,由Intellij plugin来检索flutter工程中是否存在对应的自定义UIKIT,并进行替换,提高代码的复用度.
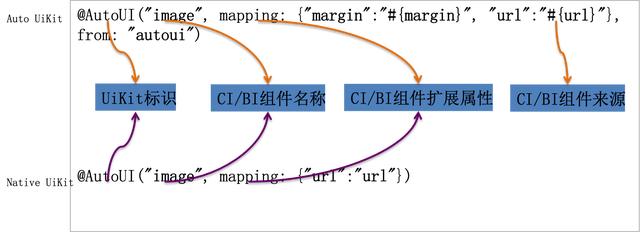
整个插件化工程需要提供自定义UIKIT的检索,替换和校验工作,以及DSL Tree的创建,修改,图示等工作,总体来说,更像ERP系统,花费一些时间能够做的更加完美。
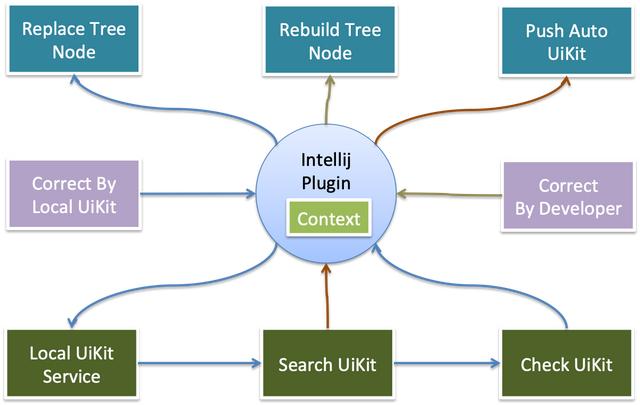
本篇我们简单介绍了UI2CODE的设计思路,我们将整个工程结构分为5个部分,其中4块内容核心处理机器视觉的问题,通过机器学习将它们链接起来。代码的线上发布是非常严格的事情,而单纯的机器学习方式,很难达到我们要求,所以我们选择以机器视觉理解为主,机器学习为辅的方式,构建整个UI2CODE工程体系。我们将持续关注AI技术,来打造一个完美的UI2CODE工具。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号