栈:数据结构与算法系列深度解析
发表时间: 2019-03-10 10:01
什么是栈
栈是一种运算受限制的线性表,只允许在表的一端进行插入和删除操作。这一端被称为栈顶,另一端被称为栈底。向一个栈中插入新数据叫做进栈、入栈或者压栈,是把新元素放到栈顶上边,使其成为新的栈顶元素;删除数据叫做出栈或者退栈,就是把栈顶的元素删掉,使其下边的元素称为新的栈顶元素。
举一个容易理解的例子,就是有一摞盘子,我们用的时候从上往下一个一个取,放的时候都是从下往上一个一个放,一般不从中间取或者放。这种先进后出,后进先出的数据结构就是栈。
这种操作受限的数据结构在什么情况下用呢,我们为什么不能用操作更为方便的数组或者链表呢。当某个数据只涉及在一端的插入和删除数据,并满足先进后出,后进先出的特点,我们就可以用栈这种数据结构,而数组和链表因为操作的灵活性,有时候会使一些数据不可控,更容易出现错误。
栈的实现
从功能上,我们是可以用数组和链表来实现栈,只要实现栈的入栈和出栈的操作,即从栈顶插入新的数据,从栈顶删除数据。用数组实现的栈叫做顺序栈,用链表实现的栈叫做链表栈。下边我们分别看一下用数组和链表实现栈的代码。这里用Java代码实现。
//基于数组实现的栈public class ArrayStack{ //数组 private String[] items; //栈的大小 private int length; //栈中元素的个数 private int count; public ArrayStack(int len){ items = new String[len]; length = len; count = 0; } //入栈 public boolean Push(String x){ //数组空间不足 if(count == length){ return false; } items[count] = x; count++; return true; } //出栈 public String Pop(){ //栈为空 if(count == 0){ return null; } String tem = items[count-1]; count--; return tem; }}//基于链表实现的栈public class ListNodeStack { private ListNode top; //进栈 public void Push(int val) { ListNode node = new ListNode(val, null); if (top == null) { top = node; } else { node.next = top; top = node; } } //出栈 public int Pop() { if (top == null) { return -1; } int val = top.val; top = top.next; return val; } //链表的结点 class ListNode { private int val; private ListNode next; public ListNode(int x, ListNode next) { val = x; this.next = next; } public int GetValue() { return val; } }}上边代码用数组实现的栈是一个固定大小的栈,当栈满了之后就没法办插入新的数据了,那么我们能不能用数组实现一个动态扩容的栈呢?前边我们将数组的时候说过,实现一个动态扩容的数组,是在数组满了的时候,我们重新创建一个大小为原来两倍的数组,然后把原来数组的数据拷贝到新的数组中,所以我们也可以用这个方法来实现一个动态扩容的栈。我们看一下代码实现。
//基于数组实现的栈public class ArrayStack { //数组 private String[] items; //栈的大小 private int length; //栈中元素的个数 private int count; public ArrayStack(int len) { items = new String[len]; length = len; count = 0; } //入栈 public void Push(String x) { //数组空间不足 if (count == length) { DilatationArray(); } items[count] = x; count++; } //出栈 public String Pop() { //栈为空 if (count == 0) { return null; } String tem = items[count - 1]; count--; return tem; } //数组扩容 private void DilatationArray() { String[] newArray = new String[length * 2]; for (int i = 0; i < length; i++) { newArray[i] = items[I]; } items = newArray; }}栈的实际应用
在Java的虚拟机中有一个内存区域被称为虚拟机栈。每个方法在执行的时候都会创建一个“栈帧”。用来存储局部变量表(包括参数)、操作栈、动态链接、方法出口等信息。每个方法从调用到结束就会有栈帧在虚拟机栈中入栈和出栈。
举一个简单的例子。
public class AddClass{ public int Main(){ int a = 0; int b = 5; int c = 0; a = Add(2, 3); c = a + b; return c; } public int Add(int x, int y){ int sum = 0; sum = x + y; return sum; }}从代码中我们看到 Main 方法中首先声明了几个变量,然后调用了 Add 方法,然后经过一些运算,最后返回一个值。我们画图来更直观的看一下这个过程。

image.png
编辑器的表达式求值的过程,就是用栈来实现的。我们举一个简单的四则运算的表达式的求值过程来看一下。例如:1+2*3-4/2。编辑器是怎么计算来得到最后的值呢。
这个求值过程,编辑器是用两个栈来实现的,一个保存数字的栈,一个保存运算符号的栈。我们从左向右遍历表达式,当遇到数字的时候把它压入数字栈,当遇到运算符号的时候,就与运算符栈的栈顶的运算符比较,如果比栈顶的运算符优先级高,就直接压入运算符栈,如果比栈顶的运算符优先级低或者相同,那么就从运算符栈取出栈顶运算符号,从数字栈中取出两个数字进行计算,然后把结果压入数字栈,然后继续比较,依次类推,知道最后。
我们为了更形象的理解,也用画图的方式来展示一下这个过程。

image.png
我们在各中编辑器的撤销和恢复操作,浏览器中的前进和后退操作,都是用栈来实现的。
我们用两个栈 A 和 B,当我们执行操作的时候把我们的每一个操作依次压入 A 栈中,当我们执行后退的操作时,依次从 A 栈中取出,然后压入 B 栈中,当执行前进操作的时候,依次从 B 栈中取出,然后压入 A 栈中。
比如我们依次执行了 a,b,c 操作,我们依次把 a,b,c 压入 A 栈。如图
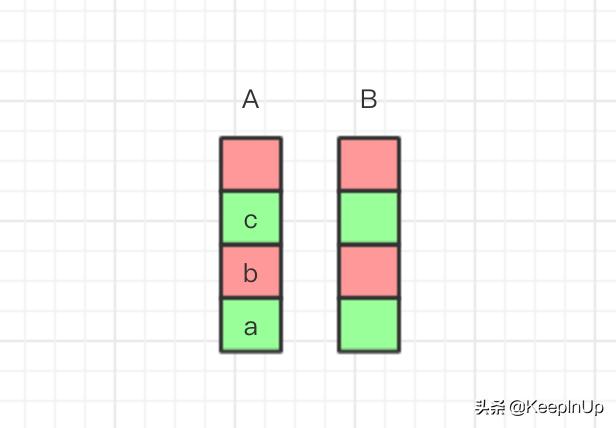
image.png
假如我们现在想要撤销 c 和 b 操作。那么它就是这样的。
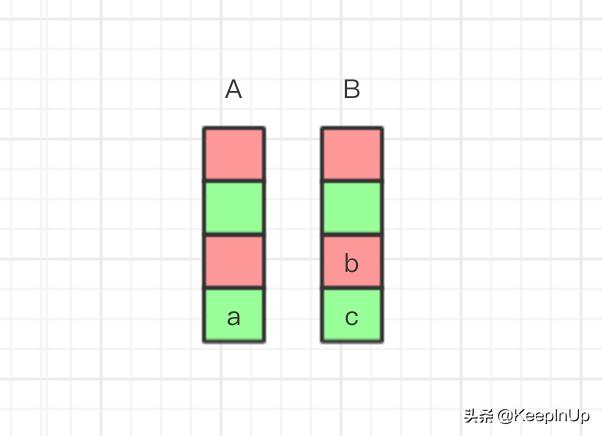
image.png
假如我又想恢复操作 b

image.png
这个时候我继续执行新的操作 d,那么无论前进后退我们都无法再回到操作 c 了,所以我们应该清空 B 栈。
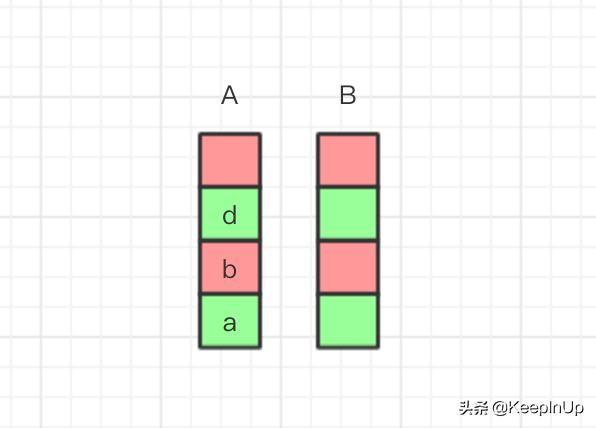
image.png
欢迎关注公众号:「努力给自己看」

公众号200x200
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号