大数据概念、处理技巧与流行技术详解
发表时间: 2019-12-02 09:33
当前这个数据时代,各领域各业务场景时时刻刻都有大量的数据产生,如何理解大数据,对这些数据进行有效的处理成为很多企业和研究机构所面临的问题。本文将从大数据的基础特性开始,进而解释分而治之的处理思想,最后介绍一些流行的大数据技术和组件,读者能够通过本文了解大数据的概念、处理方法和流行技术。作者:皮皮鲁的AI星球

什么是大数据?
大数据,顾名思义,就是拥有庞大体量的数据。关于什么是大数据,如何定义大数据,如何使用大数据等一系列问题,不同领域背景的朋友理解各不相同。IBM将大数据归纳为5个V[^1],涵盖了大数据绝大多数的特性。
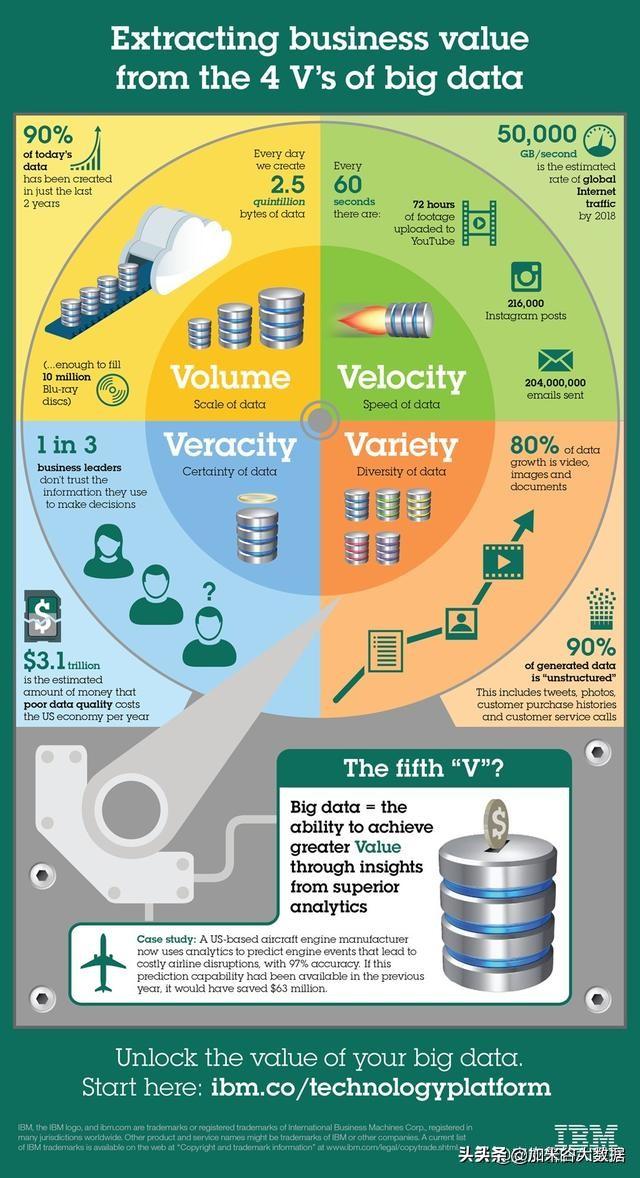
大数据的5个V
在数据分析领域,研究对象的全部被称为总体(Population),总体包含大量的数据,甚至说数据可能是无限的。比如调查15个国家的国民的诚信情况,所有国民是总体。很多情况下,我们无法保证能收集和分析总体的所有数据,因此研究者一般基于研究对象的一个子集进行数据分析。样本(Sample)是从总体中抽取的个体,是研究对象的子集,通过对样本的调查和分析,研究者可以推测总体的情况。在诚信调查的案例中,我们可以在每个国家抽取一部分国民作为样本,以此推测该国国民的诚信水平。
在大数据技术成熟之前,受限于数据收集、存储和分析能力,样本数量相对较小,大数据技术的出现让数据存储和分析能力不再是瓶颈,研究者可以在更大规模的数据上,以更快地速度进行数据分析。但数据并非天然有价值,如何让数据点石成金非常有挑战。在诚信调查中,如果我们直接询问样本对象:“你是否谎报了自己和家庭的资产以获取更大的金融借贷额度?”十之八九,我们得不到真实的答案,但我们可以综合多种渠道来分析该问题,比如结合样本对象的工作经历、征信记录等数据。
可见,大数据具有更大的数据量、更快的速度、更多的数据类型的特点。在一定的数据真实性基础上,大数据技术最终为数据背后的价值服务。
随着大数据技术的发展,数据的复杂性越来越高,有人在这5个V的基础上,又提出了一些补充,比如增加了动态性(Vitality),强调整个数据体系的动态性;增加了可视性(Visualization),强调数据的显性化展现;增加了合法性(Validity),强调数据采集和应用的合法性,特别是对于个人隐私数据的合理使用等;增加了数据在线(Online),强调数据永远在线,能随时调用和计算。
分布式计算 分而治之
计算机诞生之后,一般是在单台计算机上处理数据。大数据时代到来后,一些传统的数据处理方法无法满足大数据的处理需求,将一组计算机组织到一起形成一个集群,利用集群的力量来处理大数据的工程实践逐渐成为主流方案。这种使用集群进行计算的方式被称为分布式计算,当前几乎所有的大数据系统都是在集群进行分布式计算。

分而治之的算法思想
分布式计算的概念听起来很高深,其背后的思想十分朴素,即分而治之(Divide and Conquer),又被称为分治法。分治法将一个原始问题分解为子问题,多个子问题分别在多台机器上求解,借助必要的数据交换和合并策略,将子结果汇总即可求出最终结果。具体而言,不同的分布式计算系统所使用的算法和策略根据所要解决的问题各有不同,但基本上都是将计算拆分,把子问题放到多台机器上,分而治之地计算求解。分布式计算的每台机器(物理机或虚拟机)又被称为一个节点。
分布式计算在科研界已经有很多比较成熟的方案,其中比较有名的有消息传递接口(Message Passing Interface,MPI)和MapReduce。
MPI
MPI是一个老牌分布式计算框架,主要解决节点间数据通信的问题。在前MapReduce时代,MPI是分布式计算的业界标准。MPI程序现在依然广泛运行在全球各大超级计算中心、大学、政府和军队下属研究机构中,许多物理、生物、化学、能源、航空航天等基础学科的大规模分布式计算都依赖MPI。
分治法将问题切分成子问题,在不同节点上分而治之地求解,MPI提供了一个在多进程多节点间进行数据通信的方案,因为绝大多数情况下,在中间计算和最终合并的过程中,需要对多个节点上的数据进行交换和同步。
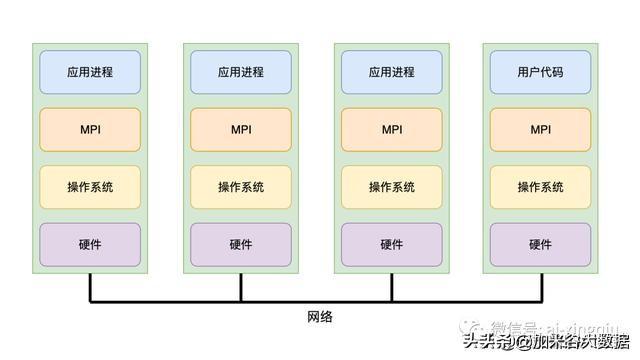
MPI并行计算示意图
MPI中最重要的两个操作为数据发送(Send)和数据接收(Recv),Send表示将本进程中某块数据发送给其他进程,Recv表示接收其他进程的数据。上图展示了MPI架构在4台服务器上并行计算的示意图。在实际的代码开发过程中,用户需要自行设计分治算法,将复杂问题切分为子问题,手动调用MPI库,将数据发送给指定的进程。
MPI能够在很细的粒度上控制数据的通信,这是它的优势,同时也是它的劣势,因为细粒度的控制意味着从分治算法设计到数据通信到结果汇总都需要编程人员手动控制。有经验的程序员可以对程序进行底层优化,取得成倍的速度提升。但如果对计算机和分布式系统没有太多经验,编码、调试和运行MPI程序的时间成本极高,加上数据在不同节点上不均衡和通信延迟等问题,一个节点进程失败将会导致整个程序失败,因此,MPI对于大部分程序员来说简直就是噩梦。
并非所有的编程人员都能熟练掌握MPI编程,衡量一个程序的时间成本,不仅要考虑程序运行的时间,也要考虑程序员学习、开发和调试的时间。就像C语言运算速度极快,但是Python语言却更受欢迎一样,MPI虽然能提供极快的分布式计算加速,但不太接地气。
MapReduce
为了解决分布式计算学习和使用成本高的问题,研究人员提出了更简单易用的MapReduce编程模型[^2]。MapReduce是Google 2004年提出的一种编程范式,比起MPI将所有事情交给程序员控制不同,MapReduce编程模型只需要程序员定义两个操作:map和reduce。
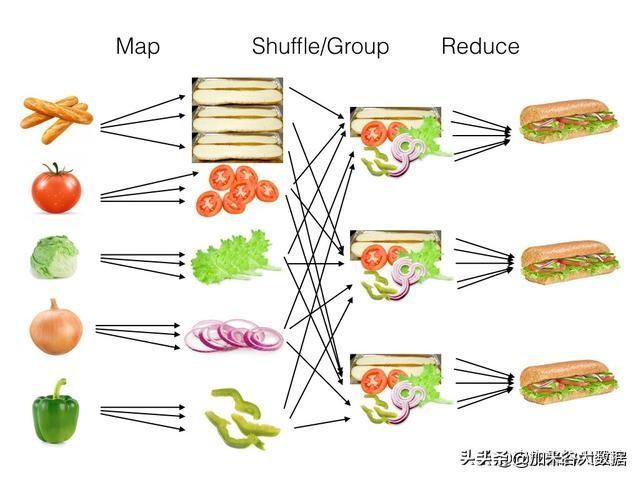
使用MapReduce制作三明治
网络上有很多MapReduce的介绍和解释,这里我们用三明治的制作过程对MapReduce进行了分解。假设我们需要大批量地制作三明治,三明治的每种食材可以分别单独处理,map阶段将原材料在不同的节点上分别进行处理,生成一些中间食材,shuffle阶段将不同的中间食材进行组合,reduce最终将一组中间食材组合成为三明治成品。可以看到,这种map + shuffle + reduce的方式就是分而治之思想的一种实现。
基于MapReduce编程模型,不同的团队分别实现了自己的大数据框架:Hadoop是最早的一种开源实现,如今已经成为大数据领域的业界标杆,之后又出现了Spark和Flink。这些框架提供了编程接口和API,辅助程序员存储、处理和分析大数据。
比起MPI,MapReduce编程模型将更多的中间过程做了封装,程序员只需要将原始问题转化为更高层次的API,至于原始问题如何切分为更小的子问题、中间数据如何传输和交换、如何将计算伸缩扩展到多个节点等一系列细节问题可以交给大数据框架来解决。因此,MapReduce相对来说学习门槛更低,使用更方便,编程开发速度更快。
数据与数据流
在大数据的5V定义中我们已经提到,数据的容量大且产生速度快。从时间维度上来讲,数据源源不断地产生,形成一个无界的数据流(Unbounded Stream)。例如我们每时每刻的运动数据都会累积到手机传感器上,金融交易随时随地发生着,传感器会持续监控并生成数据。数据流中的某段有界数据流(Bounded Stream)可以组成一个数据集。我们通常所说的对某份数据进行分析,指的是对某个数据集进行分析。随着数据的产生速度越来越快,数据源越来越多,人们对时效性的重视程度越来越高,如何处理数据流成了大家更为关注的问题。
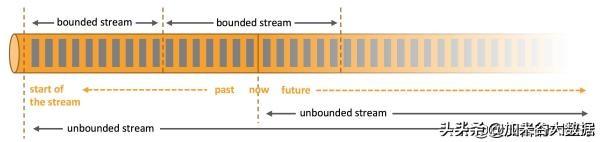
数据与数据流
批处理
批处理(Batch Processing)是对一批数据进行处理。我们身边批量计算比比皆是,最简单的批量计算例子有:微信运动每天晚上有一个批量任务,把用户好友一天所走的步数统计一遍,生成排序结果后推送给用户;银行信用卡中心每月账单日有一个批量任务,把一个月的消费总额统计一次,生成用户月度账单;国家统计局每季度对经济数据做一次统计,公布季度GDP增速。可见,批量任务一般是对一段时间的数据聚合后进行处理。对于数据量庞大的应用,如微信运动、银行信用卡等情景,一段时间内积累的数据总量非常大,计算非常耗时。
批量计算的历史可以追溯的计算机刚刚起步的上世纪60年代,当前应用最为广泛的当属数据仓库的ETL(Extract Transform Load)数据转化工作,如以Oracle为代表的商业数据仓库和以Hadoop/Spark为代表的开源数据仓库。
流处理
如前文所说,数据其实是以流(Stream)的方式持续不断地产生着,流处理(Stream Processing)就是对数据流进行处理。时间就是金钱,对数据流进行分析和处理,获取实时数据价值越发重要。个人用户每晚看一次微信运动排名觉得是一个比较舒适的节奏,但是对于金融界来说,时间是以百万、千万甚至上亿为单位的金钱!双十一电商大促销,管理者要以秒级的响应时间查看实时销售业绩、库存信息以及与竞品的对比结果,以争取更多的决策时间;股票交易要以毫秒级的速度来对新信息做出响应;风险控制要对每一份欺诈交易迅速做出处理,以减少不必要的损失;网络运营商要以极快速度发现网络和数据中心的故障等等。以上这些场景,一旦出现故障,造成了服务的延迟,损失都难以估量,因此,响应速度越快,越能减少损失,增加收入。而IoT物联网和5G通信的兴起将为数据生成提供更完美的底层技术基础,海量的数据在IoT设备上采集生成,并通过更高速的5G通道传输到服务器,更庞大的实时数据流将汹涌而至,流式处理的需求肯定会爆炸式增长。
代表性大数据技术
如前文所述,MapReduce编程模型的提出为大数据分析和处理开创了一条先河,之后陆续涌现出了Hadoop、Spark和Flink等大数据框架。
Hadoop
2004年,Hadoop的创始人受MapReduce编程模型等一系列论文的启发,对论文中提及的思想进行了编程实现。Hadoop的名字来源于创始人Doug Cutting儿子的玩具大象。由于创始人Doug Cutting当时加入了雅虎,并在此期间支持了大量Hadoop的研发工作,因此Hadoop也经常被认为是雅虎开源的一款大数据框架。时至今日,Hadoop不仅仅是整个大数据领域的先行者和领导者,更形成了一套围绕Hadoop的生态系统,Hadoop和它的生态是绝大多数企业首选的大数据解决方案。
零基础班大数据工程师培训,数据分析、数据挖掘,大数据开发,加米谷大数据培训机构
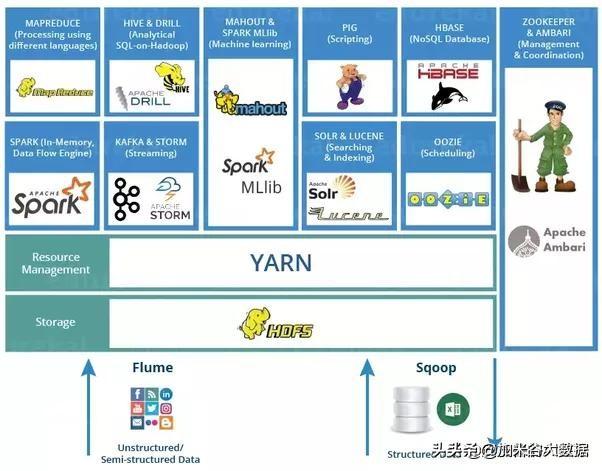
Hadoop生态
尽管Hadoop生态中的组件众多,其核心组件主要有三个:
这三大组件中,数据存储在HDFS上,由MapReduce负责计算,YARN负责集群的资源管理。除了三大核心组件,Hadoop生态圈还有很多其他著名的组件:
Spark
Spark于2009年诞生于加州大学伯克利分校,2013年被捐献给Apache基金会。Spark是一款大数据计算框架,其初衷是改良Hadoop MapReduce的编程模型和执行速度。与Hadoop相比,Spark的改进主要有两点:
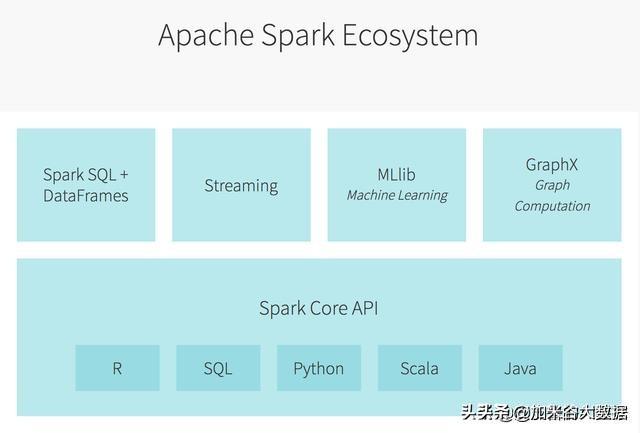
Spark生态
Spark的核心在于计算,主要目的在于优化Hadoop MapReduce计算部分,在计算层面提供更细致的服务,比如提供了常用几种数据科学语言的API,提供了SQL、机器学习和图计算支持,这些服务都是最终面向计算的。Spark并不能完全取代Hadoop,实际上,Spark融入到了Hadoop生态圈,成为其中的重要一元。一个Spark任务很可能依赖HDFS上的数据,向YARN来申请计算资源,将HBase作为输出结果的目的地。当然,Spark也可以不用依赖这些Hadoop组件,独立地完成计算。
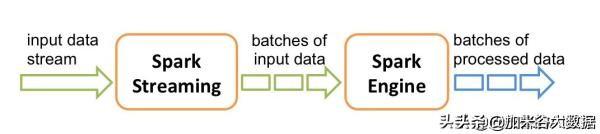
Spark Streaming数据流示意图
Spark主要面向批处理需求,因其优异的性能和易用的接口,Spark已经是批处理界绝对的王者。Spark Streaming提供了流处理的功能,它的流处理主要基于mini-batch的思想,即将输入数据流拆分成多个批次,每个批次使用批处理的方式进行计算。因此,Spark是一款批量和流式于一体的计算框架。
Flink
Flink是由德国几所大学发起的的学术项目,后来不断发展壮大,并于2014年末成为Apache顶级项目。Flink主要面向流处理,如果说Spark是批处理界的王者,那么Flink就是流处理领域的冉冉升起的新星。在Flink之前,不乏流式处理引擎,比较著名的有Storm、Spark Streaming,但某些特性远不如Flink。

流处理框架演进史
第一代被广泛采用的流处理框架是Strom。在多项基准测试中,Storm的数据吞吐量和延迟都远逊于Flink。Storm只支持"at least once"和"at most once",即数据流里的事件投递只能保证至少一次或至多一次,不能保证只有一次。对于很多对数据准确性要求较高的应用,Storm有一定劣势。第二代非常流行的流处理框架是Spark Streaming。Spark Streaming使用mini-batch的思想,每次处理一小批数据,一小批数据包含多个事件,以接近实时处理的效果。因为它每次计算一小批数据,因此总有一些延迟。但Spark Streaming的优势是拥有Spark这个靠山,用户从Spark迁移到Spark Streaming的成本较低,因此能给用户提供一个批量和流式于一体的计算框架。
Flink是与上述两代框架都不太一样的新一代计算框架,它是一个支持在有界和无界数据流上做有状态计算的大数据引擎。它以事件为单位,并且支持SQL、State、WaterMark等特性。它支持"exactly once",即事件投递保证只有一次,不多也不少,这样数据的准确性能得到提升。比起Storm,它的吞吐量更高,延迟更低,准确性能得到保障;比起Spark Streaming,它以事件为单位,达到真正意义上的实时计算,且所需计算资源相对更少。
之前提到,数据都是以流的形式产生的。数据可以分为有界(bounded)和无界(unbounded),批量处理其实就是一个有界的数据流,是流处理的一个特例。Flink基于这种思想,逐步发展成一个可支持流式和批量处理的大数据框架。
经过几年的发展,Flink的API已经非常完善,可以支持Java、Scala和Python,并且支持SQL。Flink的Scala版API与Spark非常相似,有Spark经验的程序员可以用一个小时的时间熟悉Flink API。
与Spark类似,Flink目前主要面向计算,并且可以与Hadoop生态高度集成。Spark和Flink各有所长,也在相互借鉴,一边竞争,一边学习,究竟最终谁能一统江湖,我们拭目以待。
小结
大数据一般基于分而治之的思想,分布式地进行计算。经过十几年的发展,大数据生态圈涌现出一大批优秀的组件和框架,这些组件对一些底层技术做了封装,提供给程序员简单易用的API接口。在大数据分析和处理领域,Hadoop已经发展成为一个非常成熟的生态圈,涵盖了很多大数据相关的基础服务,Spark和Flink主要针对大数据计算,分别在批处理和流处理方向建立了自己的优势。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号