半年数据库大盘点:20+国内外重大更新与技术精华
发表时间: 2024-01-10 11:14

2023年下半年,数据库行业有了一些新的发展特点,特别是国产厂商成为了发展主力。经过多年发展,国产数据库推广进入“深水区”,并取得不俗成绩。
从技术角度上看,国内数据库产品在多模向量、智能运维、云与云原生、数据库兼容等技术上取得了不少突破,并开始在用户落地上取得一定成果。在分布式数据库领域,一方面产品规模化落地并开始输出行业经验,加速实践过程;一方面以HTAP、多模等特性为代表,极大丰富了分布式数据库场景。同时我们也看到,国内集中式数据库领域取得了一定突破,这一架构产品逐步成熟可实现更为平滑的替代,成为部分国内用户的首选。以图、时序、向量等为代表的异构模型数据库产品开始受到更多关注,传统数据库中也开始更多支持如JSON等类型,场景化落地成为此类技术发展要点。
上半年大火的ChatGPT,也开始以自主SQL生成、智能优化等功能形式在更多国内数据库产品中落地。在数据分析领域,湖仓一体、融合型数仓发展快速,也成为资本方关注热点。此外,数据安全、软硬结合、数据治理等方面也有不小的进步。
从市场角度上看,国内数据库厂商竞争加剧,头部厂商你追我赶、并驾齐驱,一些新兴厂商崭露头角、快速提高。这也从侧面印证了国内数据库行业呈现加速洗牌态势,相信未来会有一批厂商及产品经过大浪淘沙,站稳脚跟获得用户认可。从近期国内第一次推出自己的象限分析来看,头部厂商聚集现象明显,这些已成为企业支撑业务的首选。在云与云原生领域,国内云数据库产品竞争呈现白热化。今年部分厂商产品大打价格战,希望以此在国内云市场领域占据更大份额。但从国际市场来看,国内企业还处于相对滞后状态,在今年国际权威的云数据库象限分析中,多家企业已退出报告主体,仅在荣誉榜单中被提及。在这方面国内产品还需要奋起直追,从低层次的价格战尽快回归到产品能力本身,同时加速在海外布局,充分参与到全球竞争之中。

dbaplus社群携手一众数据库行业专家,汇总、梳理并提炼出主流数据库近半年的版本更迭、性能优化、功能提升等关键信息,希望对大家了解数据库发展趋势,以及数据库选型工作有所帮助和启发。
本期要点
DB-Engines数据库排行榜
一、RDBMS
二、大数据生态圈
三、国产数据库
四、云数据库
推出dbaplus Newsletter的想法
感谢名单
为方便阅读、重点呈现,本文对各板块内容进行了精简,阅读完整版:
pan.baidu.com/s/1urJi4hjH_Ae4_5WMQwSaPw?pwd=2023
DB-Engines数据库排行榜
以下取自2023年12月的数据,具体信息可以参考
http://db-engines.com/en/ranking/,数据仅供参考。
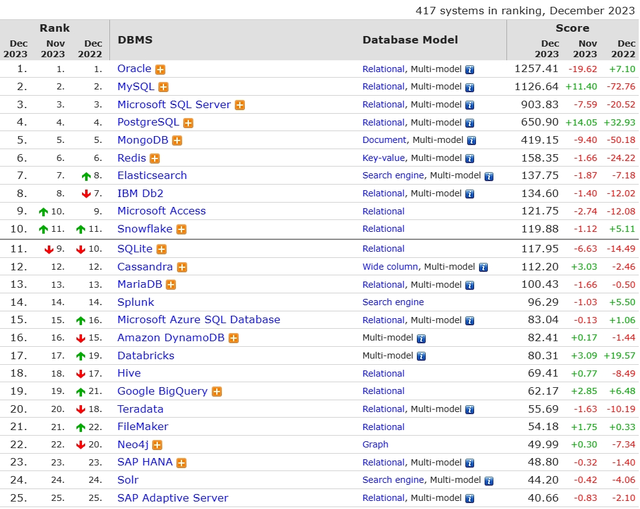
DB-Engines排名的数据依据5个不同的因素:
RDBMS
Oracle 2023下半年重大事件及技术更新
MySQL开启稳定版和创新版同时发行新阶段
2023年下半年,MySQL版本发行迎来了重要的变化,开启了稳定版和创新版同时发行的新阶段。8.0发布了两个版本,8.0.34和8.0.35,还发布了8.1和8.2的创新版。而OCI的MySQL HeatWave服务,这是一个可以同时处理事务处理、实时分析和机器学习负载的云服务,也发布了不少新特性。以下是对这些更新的简要介绍:
一、MySQL稳定版更新
1、新的密码验证系统变量:
2、复制变更:
3、`mysql_native_password` 身份验证插件弃用:
4、新增默认值功能:
5、组复制重要变更:
6、通配符授权功能弃用:
7、
INFORMATION_SCHEMA.PROCESSLIST弃用:
二、MySQL创新版更新
1、EXPLAIN FORMAT=JSON输出增强,增加了 `INTO` 选项,允许将输出保存在用户变量中。
2、加强了关闭服务器过程的日志:
3、增加组复制插件的状态变量:引入了特定于组复制的新状态变量,以改善网络不稳定情况下的诊断和故障排除。
4、MySQL Shell 8.2新版本提供了便利的实例、模式和表复制功能。与以往通过文件进行的导出、导入方法相比,无需中间存储,大大提高了便利性。
5、` expire_logs_days `系统变量删除:弃用并替换为`
binlog_expire_logs_seconds`。
6、MySQL企业版防火墙更新:
7、MySQL Router 8.2.0更新
读写分离功能:
MariaDB Server 10.11发布
MariaDB Server 10.11是一个长期稳定的版本,维持到2028年2月。
一、新特性 - OLTP产品线
1、【王炸功能】Alter修改表结构实现从库无延迟并行复制:通常,ALTER TABLE首先在主库上执行完毕后,才被复制并开始在从库上执行。有了这个特性,当ALTER TABLE在主库上开始执行时,它会立刻被复制并开始在从库上执行。这样可以完全消除从库的复制滞后,即可实现从库无延迟并行复制。
使用:
MariaDB> set global binlog_alter_two_phase=1;MariaDB> set binlog_alter_two_phase=1;MariaDB> alter table sbtest1 add index IX_pad(pad);ALTER TABLE回车后,你可以立即用mysqlbinlog工具去查看binlog,可以看到ALTER TABLE语句已经记录在binlog文件里。
2、为SQL线程添加了
global.slave_max_statement_time系统变量:以限制每次SQL thread线程长时间执行,当超过此值(以秒为单位)SQL thread线程执行的SQL将被中止。
3、MariaDB多源复制添加FOR CHANNEL关键字兼容了MySQL多源复制的语法。
4、基于GTID模式建立同步复制时,change master to语法弃用了MASTER_USE_GTID = Current_Pos选项,以支持新的MASTER_DEMOTE_TO_SLAVE选项。
5、支持在线动态调整innodb_log_file_size重置事务日志文件大小。
二、新特性 - OLAP产品线
MariaDB ColumnStore利用分布式列式存储和大规模并行处理(MPP)共享无架构扩展了MariaDB企业服务器,将其转变为独立或分布式数据仓库,用于复杂SQL查询和高级分析,而无需创建任何索引。
1、MariaDB Columnstore 10.6支持一键部署:为了简化安装过程,让用户享受更好的产品体验,MariaDB提供yum源方式部署,用户只需几条命令,即可轻松部署OLAP MPP数据仓库环境。
mysqld服务启动后,手工安装存储引擎插件即可完整部署。
MariaDB> INSTALL PLUGIN Columnstore SONAME 'ha_columnstore.so';SQL语法使用起来跟InnoDB无任何差异。
参见官方文档:
mariadb.com/docs/columnstore/deploy/topologies/single-node/community-columnstore-cs10-6/#Install_ColumnStore_via_YUM_(RHEL,_CentOS)
2、MariaDB Columnstore引擎使用注意事项:【重大改变】支持与InnoDB同步复制
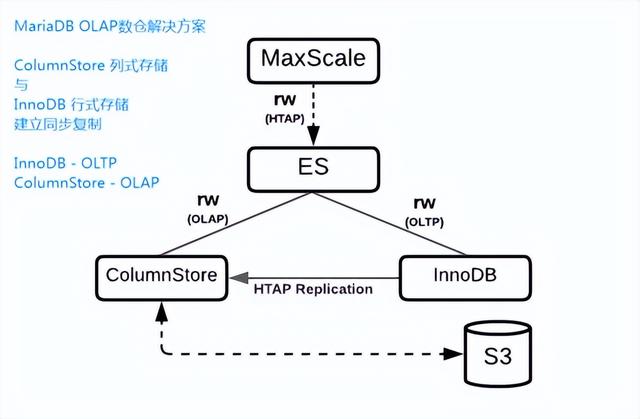
现在,可以使用 "CHANGE MASTER TO" 命令与业务库中的InnoDB引擎建立同步复制,而无需依赖于ETL工具。通过这种方式,可以实现增量数据的同步。
PostgreSQL发布16.1新版本/更新15、14、13、12、11版本
2023年下半年,PostgreSQL主要发布了11、12、13、14、15版本系列的修正版本11.22(最终版本,不再提供更新)、12.17、13.13、14.10、15.5及16.1正式版本,其中值得关注的新特性有:
1、性能:
2、开发:
3、安全特性:
4、监控与管理:
5、BUG修复和改进:
OceanBase发布4.2.1 LTS版本
2023年,OceanBase企业版及社区版共计迭代27个版本,新增超过450项功能。11月16日,OceanBase发布一体化数据库的首个长期支持版本4.2.1 LTS。作为4.x的首个LTS版本,该版本的定位是支撑客户关键业务稳定长久运行,可在关键业务负载中放心地规模化使用。经过十余个版本的迭代打磨,新的一体化版本已经在生产环境支撑了上百个业务系统稳定运行。
1、兼容性:
OceanBase 4.2.1 LTS是面向OLTP核心场景的全功能里程碑版本。Oracle兼容性层面在复杂查询、存储过程、JSON、Database Link进一步提升,MySQL兼容模式在之前的版本已经对MySQL 5.7有很好兼容能力的基础上,4.2.1 LTS版本引入了大量MySQL 8.0的新功能兼容。
2、性能:
OLTP性能在各种规格下相比之前的版本均有较多提升。在96 Core机器上,sysbench压测的性能相比3.2.4版本提升9%到100%。新版本对于小规格有更大幅度的优化,提升比例从51%到152%不等,在read only、insert、update三种场景的性能都达到了3.2.4版本的2倍以上。OLTP分析查询场景性能有大幅度提升,新版本TPC-DS 100G性能是3.2.4版本的2.7倍,性能优化效果显著。
3、业务连续性:
新增仲裁无损容灾能力,提供创新的仲裁无损容灾,通过两副本实现RPO=0,帮助用户实现更具性价比的异地容灾。同时,面向更多场景的RTO<8s,提供更加完善故障恢复能力,当机器故障、网络中断、IO异常甚至是数据库进程被中断等异常情况发生时,数据库的服务都能在8秒内恢复,给业务提供更强的持续可用能力。此外,新版本提供租户级别物理备库功能,让备库功能做到租户粒度,允许同一个集群中同时存在主库角色的租户和备库角色的租户,便于用户安排更符合实际业务的容灾部署方案。
4、易用性:
支持Auto DOP,新版本查询优化器可在生成查询计划时评估查询需要执行的时间,自动确定是否开启并行和开启适量的并行度。以避免由于手动指定并行度而导致的性能下降。最新的4.2.1 LTS版本对DDL进行进一步优化,Create Table语句与Truncate Table允许并行执行,在通常的生产环境中,批量并发操作新版本性能相比3.2.4 LTS版本有10倍以上的性能提升。支持旁路导入,帮助用户在大量数据迁移的过程中进行表级别的并发控制并保证数据的一致性,不仅可以用在新业务加载数据的场景,也可以在日常的数据操作和运维管理使用。
此外,OB Cloud已上线4.2.1版本,支持客户在云上体验最新的OceanBase产品能力。在完善从1C / 2C / 4C / 8C / 14C / 24C / 30C / 62C / 104C全系列规格的同时,推出ARM系列产品规格。目前OB Cloud已支持阿里云、腾讯云、华为云、AWS等多个云基础设施,这意味着用户可以在不同的云基础设施使用一致的数据库和技术栈。
TiDB发布7.5 LTS版本和7.3、7.4两个DMR版本
一、2023年下半年重大更新总结
TiDB发布7.5 LTS版本和7.3、7.4两个DMR版本,着眼于提升规模化场景下关键应用的稳定性,累计新增和优化特性150+,其中值得关注的新特性有:
1、TiDB v7.1引入资源管控(Resource Control)特性,提供基于资源管控的数据库整合方案,多个业务可共享同一个TiDB集群,DBA可为不同的工作负载设置资源配额和优先级,极大降低用户对于多套MySQL集群的运维复杂度和运维成本。自TiDB v7.4开始,资源管控支持DDL、analyze、import等后端任务管理,可自动识别后端任务,降低其资源消耗。
2、TiDB v7.4版本发布了对MySQL 8.0常用功能和语法的支持,这使得平滑迁移MySQL 8.0的应用变得轻而易举。TiDB完整支持MySQL 8.0的公共表表达式(CTE)、窗口函数(window function)、基于角色的权限管理、增强uft8mb4字符集、JSON多值索引 (Multi-valued Index)、修改会话变量的hint ( SET_VAR())、CHECK约束等重要特性。
3、重要场景的性能获得显著提升:推出DDL并行执行框架,在线DDL性能获得指数级提升;TiDB 7系列版本的OOM较之前的版本下降了99%;目前,TiDB已经能做到单表50TB数据的小时级别导入,数据同步输出的延时降低至了秒级,满足用户对极致的RPO和RTO的述求。
7月,TiDB Cloud Serverless正式商用,是一款AI Ready的完全托管的DBaaS服务,可根据需求自动扩展。
二、明年展望
2024年,TiDB将迎来8.0时代。TiDB V8系列将聚焦于高扩展性、在多租户背景下的应用稳定性、高可用性,以及围绕云平台与Serverless的体验提升等方向的功能升级。
大数据生态圈
Elasticsearch发布8.9.x、8.10.x、8.11.x三个大版本
Elasticsearch在2023年下半年发布了三个大版本,8.9.x、8.10.x、8.11.x,带来了诸多的新功能特性,在每个大版本之间也包括几个小版本,解决一些问题修复。除了发布主流新版本之外,Elasticsearch依然发布了多个7.17.x持续更新版本,主要侧重对已知问题的修复,也包括支持与8.x版本兼容性过渡。

Elasticsearch 2023年下半年版本发布
以下是8.9.x~8.11.x版本值得关注的新功能特性:
1、并发查询与写入性能提升:
2、ELSER语义搜索:
3、KNN并行查询:
4、ES|QL:
5、JDK 21.x:
Flink发布1.18.0版本
ClickHouse发布23.7、23.8、23.9、23.10、23.11等版本
一、2023年下半年重大更新总结
2023年下半年,ClickHouse主要发布了23.7、23.8、23.9、23.10、23.11五个新版本,其中23.8是LTS版本,值得关注的新功能特性:
1、关于JSON的类型推断:
在23.9中,这个功能专门针对那些可预测JSON结构的用户。它允许从结构化数据中推断出嵌套模式,从而节省用户手动定义的时间。虽然这带来了一些约束,但加快了入门体验。
2、工作负载调度:
ClickHouse最受期待的功能之一是能够隔离查询工作负载。具体而言,用户经常需要为一组查询定义资源限制,以最小化其影响。这里的目标通常是确保这些查询不会影响其他关键业务查询。尽管在ClickHouse早起晚睡版本中部分实现了内存配额和CPU限制,但这还远不满足要求。例如,不能限制共享资源(如磁盘I/O)的使用。因此,ClickHouse在23.9中实现了工作负载调度。用户在创建工作负载后,可以通过设置工作负载来调度查询。
3、GCD编解码器:
在23.9中,添加了一个新的编解码器GCD。该编解码器基于最大公约数算法,可以显著提高对存储在列中的小数(decimal)的压缩效果,其中配置的精度远远高于所需。此编解码器还有助于处理大数(例如1201000000),并且增加幅度大,例如从1201000000到1203000000。具有类似大小和分布的整数也可以从GCD中受益,例如时间戳(UInt64)具有纳秒精度,以及频繁的日志消息,例如每100毫秒一次。
4、直接从归档中导入:
ClickHouse已经支持如zstd、lz4、snappy、gz、xz和bz2等格式的压缩文件。在23.8版本之前,这些压缩文件只能包含一个文件。在23.8版本中,增加了对zip、tar和7zip的支持,这些格式都可能包含多个文件。
5、默认启用的稀疏列:
稀疏列在23.7之前需要明确启用。这个优化旨在减少某列写入的总数据,当检测到大量的默认值时,动态地改变编码格式。除了提高压缩率,这还有助于提高查询性能和内存效率。在23.7中,此功能默认启用。当可以应用这种编码时,用户应该立即看到压缩和性能的提升。
6、Parallel窗口函数:
窗口函数自21.5版起在ClickHouse中可用。那么并行化是通过利用窗口函数固有的分桶能力也就是‘分区’来实现的。当用户指定一个窗口函数应该按列进行分区时,实际上为每个分区创建了一个单独的逻辑窗口,即如果该列包含N个不同的值,就需要创建N个窗口。在23.11版本中,这些分区可以有效地并行构建和评估。
7、Prewhere列统计:
列统计是ClickHouse中一项新的实验性功能,它能够在查询优化方面发挥更好的作用。有了这个功能,用户可以让ClickHouse为MergeTree系列引擎的表的列创建(并自动更新)统计信息。这些统计信息存储在表的各个部分内,以一个小型的单一文件statistics_(column_name).stat的形式存在,这是一个通用的容器文件,用于存储启用了统计功能的每个列的不同类型的统计信息。这确保了对列统计的轻量级访问。截至目前,唯一支持的列统计类型是t-digests。
二、明年展望
2023年是ClickHouse正式进入中国市场的一年。ClickHouse Cloud作为SaaS版的云数仓产品已经落地在AWS和谷歌云,在国内与阿里云合作,于2023年10月正式开启了企业版公测。企业版与全球的ClickHouse Cloud服务能力同步,计划明年在阿里云上正式GA。
Doris发布2.0版本以及2.0.1、2.0.2、2.0.3版本
2023年8月11日,Apache Doris正式发布具有里程碑意义的2.0.0版本,超过275位贡献者为2.0.0版本提交了超过4100个优化项,同时在该版本基础上发布了2.0.1、2.0.2、2.0.3等多个迭代版本。其中重点关注的特性包括:
1、全新查询优化器:
采取更先进的Cascades框架、使用更丰富的统计信息、实现更智能化的自适应调优,在绝大多数场景无需任何调优和SQL改写即可实现极致的查询性能,同时对复杂SQL支持得更加完备、可完整支持TPC-DS全部99个SQL。
2、自适应的并行执行模型:
引入Pipeline执行模型作为查询执行引擎。在Pipeline执行引擎中,查询的执行是由数据来驱动控制流变化的,各个查询执行过程之中的阻塞算子被拆分成不同Pipeline,各个Pipeline能否获取执行线程调度执行取决于前置数据是否就绪,实现阻塞操作的异步化、可更加灵活地管理系统资源,同时减少线程频繁创建和销毁带来的开销,并提升 Apache Doris对于CPU的利用效率。
3、日志分析能力全面增强:
提供了原生的半结构化数据支持,在已有的JSON、Array基础之上增加了复杂类型Map,并基于Light Schema Change功能实现了Schema Evolution。与此同时,新引入的倒排索引和高性能文本分析算法全面加强了Apache Doris在日志检索分析场景的能力,可以支持更高效的任意维度分析和全文检索。与基于Elasticsearch的日志存储分析方案相比,写入吞吐提升5倍、存储成本降低超过70%、查询性能比Elasticsearch提升2-4倍。
4、数据湖联邦分析:
在数据源方面,支持了Hudi Copy-on-Write表的Snapshot Query以及Merge-on-Read表的Read Optimized Query,截止目前已经支持了Hive、Hudi、Iceberg、Paimon、MaxCompute、Elasticsearch、Trino、ClickHouse等数十种数据源,几乎支持了所有开放湖仓格式和Metastore。同时还支持通过Apache Range对Hive Catalog进行鉴权,可以无缝对接用户现有的权限系统。同时还支持可扩展的鉴权插件,为任意Catalog实现自定义的鉴权方式。在性能方面,利用Apache Doris自身高效的分布式执行框架、向量化执行引擎以及查询优化器,结合2.0版本中对于小文件和宽表的读取优化、本地文件Cache、ORC/Parquet文件读取效率优化、弹性计算节点以及外表的统计信息收集,Apaceh Doris在TPC-H场景下查询Hive外部表相较于Presto/Trino性能提升3-5倍。
5、行列混存、单节点3w+ QPS:
引入全新的行列混合存储以及行级Cache,使得单次读取整行数据时效率更高、大大减少磁盘访问次数,同时引入了点查询短路径优化、跳过执行引擎并直接使用快速高效的读路径来检索所需的数据,并引入了预处理语句复用执行SQL解析来减少FE开销。通过以上一系列优化,2.0.0版本在并发能力上实现了数量级的提升,实现了单节点30000 QPS的并发表现,较过去版本点查询并发能力提升超20倍。
6、主键模型写时更新优化和完备的数据更新能力:
在实时分析场景中,数据更新是非常普遍的需求,而可变数据集上的高效分析往往是一大挑战。在2.0.0版本中,对Unique Key主键模型的Merge-on-Write写时更新模式进行了优化,高并发upsert的稳定性显著提升。同时增加了Unique Key主键模型的部分列更新,在多张上游源表同时写入一张宽表时,无需由Flink进行多流Join打宽,直接写入宽表即可,减少了计算资源的消耗并大幅降低了数据处理链路的复杂性。基于以上优化,Apache Doris对于各类数据更新需求,包括整行更新、部分列更新、按条件进行批量更新或删除以及整表或者整个分区的重写(inser overwrite)都有完备的支持。
7、数据高频写入更稳定:
在高频数据写入过程中,小文件合并和写放大问题以及随之而来的磁盘I/O和CPU资源开销是制约系统稳定性的关键,因此在2.0版本中我们引入了Vertical Compaction以及Segment Compaction,用以彻底解决Compaction内存问题以及写入过程中的Segment文件过多问题,资源消耗降低90%,速度提升50%,内存占用仅为原先的10%。
8、更加完善的多租户资源隔离:
增加了Workload Group资源软限制的方案,通过对Workload进行分组管理,以保证内存和CPU资源的灵活调配和管控。当集群资源紧张时,将自动Kill组内占用内存最大的若干个查询任务以减缓集群压力。当集群资源空闲时,一旦某一Workload Group使用资源超过预设值时,多个Workload将共享集群可用空闲资源并自动突破阙值,继续使用系统内存以保证查询任务的稳定执行。Workload Group还支持设置优先级,通过预先设置的优先级进行资源分配管理,来确定哪些任务可正常获得资源,哪些任务只能获取少量或没有资源。与此同时,在Workload Group中还引入了查询排队的功能,在创建Workload Group时可以设置最大查询数,超出最大并发的查询将会进行队列中等待执行,以此来缓解高负载下系统的压力。
9、冷热数据分层:
冷热数据往往面临不同频次的查询和响应速度要求,因此通常可以将冷数据存储在成本更低的存储介质中。在2.0 版本中推出了冷热数据分层功能,冷热数据分层功能使Apache Doris可以将冷数据下沉到存储成本更加低廉的对象存储中,同时冷数据在对象存储上的保存方式也从多副本变为单副本,存储成本进一步降至原先的三分之一,同时也减少了因存储附加的计算资源成本和网络开销成本。通过实际测算,存储成本最高可以降低超过70%。
StarRocks发布3.1和3.2版本
一、2023年下半年重大更新总结
2023年下半年,StarRocks主要发布了3.1.0-3.1.6、3.2多个版本,其中值得关注的新功能特性有:
1、存算分离架构:
2、数据湖分析:
3、物化视图:
4、易用性的持续提升:
5、优化查询性能和稳定性:
6、行列混存:
二、明年展望
国产数据库
ActionDB及TensorDB 2023下半年重大更新总结
一、ActionDB
1、2023年下半年重大更新总结
2023年下半年,ActionDB发布了1.0、1.5、2.0多个版本,其中值得关注的新特性有:
1)ActionDB TDE:可实现数据的透明存储加密,提高数据安全性。
2)基于Binlog的双向复制:
2、明年展望
2024年上半年,ActionDB将进一步完善工具生态,推出数据传输工具:ActionDB-OMS,数据管理平台:ActionDB-DMP,SQL质量管理平台:ActionDB-SQLE等,并将继续提高ActionDB在安全可信方面的能力。
二、TensorDB
1、2023年下半年重大更新总结
1)支持英伟达GPU和国产GPU的单机多卡以及多机多卡的向量计算加速。
2)完成信创化改造,支持国产ARM架构、操作系统、芯片、存储、中间件等。
3)支持稠密向量和稀疏向量的混合检索。
2、明年展望
基于TensorDB与开源大模型实现RAG流程的快速构建、评估与优化。
SequoiaDB发布3.4.11及5.6.1版本
2023年下半年,巨杉数据库发布了SequoiaDB V3.4.11及V5.6.1两个版本,主要在性能等方面进行了优化提升:
1、主要特性
优化内存管理,提供内存回收的能力。
2、性能优化
存储引擎:
3、解决重要Bug
存储引擎:
达梦数据库更新DM8.1.3版本
2023年下半年,达梦数据库主要更新了DM8.1.3版本,其中值得关注的新变化有:
1、新特性
2、功能改进
3、性能优化
ByConity发布0.3.0版本
一、2023下半年重大更新总结
字节跳动开源数仓ByConity 0.3.0版本于12月18日正式发布,该版本提供倒排索引、基于共享存储的选主方式等多项新特性,对冷读性能进一步优化,对ELT能力进一步迭代,同时修复了若干已知问题,进一步提升系统的性能和稳定性。
1、倒排索引:
在ByConity使用过程中,很多业务对文本检索相关能力(如StringLike)提出了非常高的需求,希望社区能够优化相关查询性能,同时兼容ClickHouse在今年支持的倒排索引的能力。为满足业务诉求,保持生态兼容,同时提升ByConity的文本检索能力,ByConity在0.3.0版本加入了对文本检索的支持,为日志数据分析等场景提供高性能查询。
2、基于共享存储的选主方案:
在ByConity架构中存在多种控制节点,它们需要各自通过多副本+选主来提供高可用的服务能力,例如Resource Manager,TSO等。实际中的多个计算server,也需要选出一个单节点来执行特定的读写任务。之前ByConity使用了clickhouse-keeper组件来进行选主,该组件基于Raft实现,提供兼容zookeeper的选主接口。但在实际的使用中遇到了很多运维问题,例如需要部署3个以上节点才能提供容灾,增加运维负担;节点增删和服务发现流程复杂;容器重启后如果服务变换ip和服务端口,keeper组件难以快速恢复,等等。考虑ByConity作为一个新的云原生服务,并不需要兼容ClickHouse对zookeeper的访问,我们选择了基于存算分离的云原生架构实现一种新的选主方式来优化以上问题。
3、冷读性能的进一步提升:
在ByConity 0.2.0中,通过引入IOScheduler等方式提高了冷读查询的性能,尤其是在S3上的冷读性能。0.3.0版本通过引入ReadBuffer的Preload等优化,进一步提高了冷读性能。
4、ELT能力增强:
在0.3.0中,引入新的BSP模式,通过stage by stage的执行以及增强disk based shuffle,满足有限条件下的计算,提高吞吐。在ByConity中复杂查询对query plan的stage进行了切分并进行了stage by stage的调度,但在语义上仍然是all at once的调度。ELT在执行时需要对查询进行分阶段运行,需要进一步达到stage by stage执行的效果。
二、明年展望
后续版本将会对异步处理模式和调度器的实现做进一步的增强。
AntDB发布8.0超融合数据库
2023年下半年,亚信安慧AntDB数据库发布了8.0超融合数据库,其中值得关注的新变化有:
1、一切皆可SQL的超融合数据库:超融合架构从实验室环境正式走向生产,以六大执行引擎共存为基础,为上层的交易、分析、高频处理、实时计算、物联网连接、AI向量计算提供底层数据服务。用户可在包括标准SQL在内的ODBC、JDBC、Python以及各种开发框架下,使用AntDB数据库里的数据。
2、数据库内核里的流式计算:从内核层面引入流式计算“事件+推送”的消息模式,更注重实时性和并发处理能力。
3、集中式分布式一体化:一套代码同时支持集中式、分布式、云原生部署模式。
4、数据库迁移同步工具更新升级,实现面向新型多模态多引擎数据库的一键式评估、迁移、稽核与数据效验。
QianBase™发布QianBaseTP-15.0正式版及QianBaseMPP-7.0.0正式版
一、QianBaseTP
2023年下半年,QianBaseTP单机版主要发布了15.0的正式版本,在产品的功能性、兼容性和性能方面进行了提升,主要内容如下:
1、新增DATE,TIMESTAMP的格式化类型,增强decimal,numeric,number等数据类型,以及提升函数兼容性等。
2、新增connect by层次查询功能。
3、新增listagg列转行函数功能。
4、新增透明加密功能。
5、预写式日志无锁化,在TPCC场景下,Arm环境性能提升了约17%,x86环境性能提升了12%。
二、QianBaseMPP
2023年下半年,QianBaseMPP主要发布了7.0.0的正式版本,在产品的功能性、兼容性和性能方面进行了提升,主要内容如下:
1、新增同义词功能。
2、新增UPSERT功能。
3、进一步提升Oracle的兼容性,包含但不局限于binary_double,binary_float,to_nchar,sysdate,systimestamp等。
4、新增磁盘配额管理功能,可支持用户,模式,表级别的磁盘配额管理。
5、新增AO表唯一索引功能。
6、AO列存表,智能索引,支持block级别的Min,Max,BloomFilter过滤,在精准查询和小范围扫描的场景下,大幅提升查询性能。
ArkDB 2023下半年技术更新要点
云数据库
PolarDB新增NL2SQL、列存索引多机并行、一站式HTAP、全加密等功能
2023年下半年,PolarDB发布了一系列新版本和功能,其中值得关注的版本、功能有:
一、PolarDB MySQL版
1、全方位降本,推出全新经济版,支持压缩功能、热温冷分层管理功能。
2、发布CRAC多写能力,推出基于共享存储的多机集群形态。
3、IMCI列存索引发布多节点全内存并行分析,在线事务处理和计算分析一体化。
4、发布DB4AI能力,一站式MLOps,内置NL2SQL、通义千问等大模型。
5、发布PolarDB+AnalyticDB、PolarDB+Tair DBCache一站式服务。
二、PolarDB PostgreSQL版
1、推出标准版,性价比相较企业版更具吸引力。
2、推出一站式HTAP服务,复杂查询性能最高可提升百倍。
3、发布全加密功能,支持对数据库表中的敏感数据列进行加密。
三、PolarDB分布式版
1、发布5.4.17和5.4.18两个大版本。
2、新增生成列的创建方法,以及在生成列上创建索引的方法。
3、新增支持affected rows行为。
腾讯云2023下半年数据库产品更新汇总
一、TDSQL MySQL版
二、TDSQL PostgreSQL版
三、TDSQL-C推出Serverless 2.0版
云原生数据库TDSQL-C主要推出了Serverless 2.0版,发布了新内核特性以及全新功能,其中值得关注的动态如下:
四、DTS-DBBridge异构迁移能力升级
数据传输服务DTS-DBBridge异构迁移能力升级,支持Oracle、DB2等迁移能力,提升传输性能,增强稳定性、易用性,适配国产化信创环境。
1、新增10条链路:
2、功能增强:
3、适配国产化信创环境。
五、DBbrain持续提升数据库自运维能力
数据智能管家DBbrain值得关注的动态如下:
六、腾讯云向量数据库(Tencent Cloud VectorDB)正式上线
Tencent Cloud VectorDB是一款全托管的自研企业级分布式数据库服务,专用于存储、检索、分析多维向量数据,于2023年8月首次上线,主要特性包括:
注:关于腾讯云云数据库MySQL、PostgreSQL、Redis、MongoDB、SQL Server、KeeWiDB、CTSDB、DTS、TDSQL TDStore等产品更新信息,可阅读本期Newsletter完整版
青云2023下半年数据库产品更新汇总
2023年7月5日,RadonDB DMP 1.3.0正式上线。该版本适用于KubeSphere Enterprise 3.4.1。
2023年10月25日,RadonDB DMP 1.4.0正式上线。该版本适用于KubeSphere Enterprise 3.5.0。
2023年11月24日,RadonDB DMP 2.0.0正式上线。该版本适用于KubeSphere Enterprise 4.X订阅版。
2023年9月7日,MySQL Plus 1.3.0正式上线。其中包含三个版本:基础版、高可用版、金融版。
2023年9月27日,PostgreSQL PG V2.3.0正式上线。其中包含了两个版本:基础版、高可用版。
2023年8月26日,Kafka 3.1.0 - v3.0.1正式上线。该版本基于Apache Kafka版本3.1.0构建。
2023年9月24日,HBase 2.4.4 - v3.0.0正式上线。该版本基于Apache HBase 2.4.4、Apache Hadoop 3.2.1、Apache Phoenix 5.1.2构建。
2023年12月25日,ClickHouse 1.2.0正式上线。该版本基于ClickHouse 22.3.20构建,其中包含了两个版本:基础版、企业版。
拓数派发布大模型数据计算系统πDataCS,更新PieCloudDB多个版本
一、πDataCS
2023年10月24日,拓数派发布大模型数据计算系统(简称πDataCS),以云原⽣技术重构数据存储和计算,做到「⼀份数据,多引擎数据计算」。πDataCS主要解决海量数据的存储和实时计算问题,具备湖仓⼀体化的能力,用户可根据实际情况选择合适的数据计算引擎:云原生虚拟数仓PieCloudDB、向量计算引擎PieCloudVecotor和 (大模型)机器学习PieCloudML。目前,πDataCS面向国内市场提供公有云版、社区版、企业版及一体机多个版本。
二、PieCloudDB
云原生虚拟数仓PieCloudDB在2023年下半年,不管是内核还是云原生平台都进行了多个版本的更新:
1、内核模块更新:
PieCloudDB的内核版本从2.5.0升级至2.10版本。在近半年的版本更新中,PieCloudDB在功能、性能、稳定性、安全性上都有了大幅提升,新增众多重要更新:
2、云原生平台:
PieCloudDB云原生平台不断迭代,截至12月中旬共完成10个版本的更新,其中包括但不限于:
SelectDB Cloud 3.0发布,增加全新产品形态
2023年9月25日,飞轮科技全面开放SelectDB Cloud云原生数据仓库,增加全新的私有仓库(BYOC)产品形态,同时发布了更自主可控的SelectDB Enterprise企业版。
1、云原生内核更新:
目前SelectDB最新内核版本为3.0.4。近半年来,SelectDB内核发布了3个两位版本共20个三位版本,从性能到稳定性都有大幅提升,新增众多重要更新:
2、云原生管控平台更新:
近半年来,SelectDB Cloud云原生管控平台持续迭代,新增重要更新如下:
近期Newsletter回顾&下载
推出dbaplus Newsletter的想法
dbaplus Newsletter旨在向广大技术爱好者提供数据库行业的最新技术发展趋势,为社区的技术发展提供一个统一的发声平台。为此,我们策划了RDBMS、NoSQL、NewSQL、图数据库、时序数据库、大数据生态圈、国产数据库、云数据库等几个版块。
我们不以商业宣传为目的,不接受商业广告宣传,严格审查信息源的可信度和准确性,力争为大家提供一个纯净的技术学习环境,欢迎监督指正。
下期Newsletter计划时间是2024年6月11日~6月21日,如果有相关的信息提供请发送至邮箱:newsletter@dbaplus.cn
感谢名单
最后要感谢那些提供宝贵信息和建议的专家朋友,排名不分先后。

声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号