揭秘OLTP、OLAP与HTAP三大数据库类型的核心差异
发表时间: 2024-06-11 23:09
导读:在大数据和AI时代,数据库成为各类应用不可或缺的重要组成部分。而数据库中的数据依赖存储引擎进行管理,包括数据的存储、查询、更新和删除等。因此,在设计系统时,选择正确的数据库存储引擎方案变得尤为重要。这篇文章将以关系型、NoSQL和NewSQL数据库,以及OLTP、OLAP和HTAP处理方式为切入点,深入探讨不同类型的数据库背后的存储引擎方案选型取舍。
01关系型数据库&NoSQL数据库&NewSQL数据库
下图展示了关系型数据库、NoSQL数据库、NewSQL数据库的发展过程。
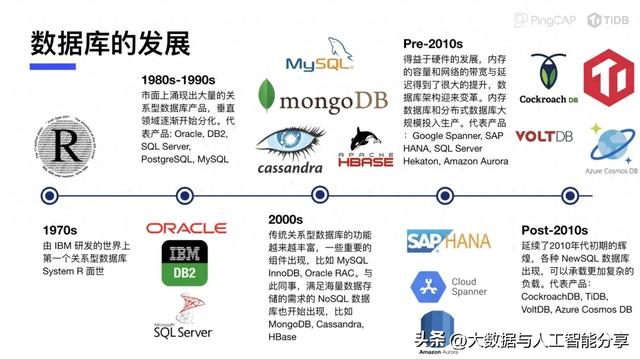
1. 关系型数据库
关系型数据库也称为SQL数据库,最早的数据库发展可以追溯至1970年IBM研发的第一个SQL数据库System R,这也是最早的SQL数据库,再后来1980~1990年这段时间涌现出来了一些SQL数据库产品,例如Oracle、DB2、SQL Server、PostgreSQL、MySQL等。
到2000年左右,关系型数据库越来越丰富,出现了很多迄今一直在发挥重要的组件,例如MySQL、Oracle等。
SQL数据库按照以“行”为单位的二维表格存储数据,这种方式最符合现实世界中的实体,同时通过事务的支持为数据的一致性提供了非常强的保证。因此SQL数据库主要适合的场景是读多写少的场景。
关系型数据库中为了适配不同的应用场景,通常会将存储引擎设计为插件式的接口。然而主流的存储引擎,仍然是读多写少的特点。以MySQL为例,InnoDB存储引擎被广泛运用,它通过B+树来存储索引和数据。B+树这种数据结构,由于其独特的特性使得查询的性能非常高。
B+树存储引擎适用于需要高效的数据查找、范围查询和顺序访问的场景。它在关系型数据库中被广泛应用,如MySQL的InnoDB存储引擎和Oracle的B+树索引。然而,B+树存储引擎对于频繁的数据插入和删除操作可能会有一定的开销,因为这会触发节点的分裂和合并操作。
2. NoSQL数据库
在面对海量数据存储、高并发访问的场景下,关系型数据库的扩展性和性能会受到限制。随着互联网的飞速发展,到2000年左右,存储海量数据、高并发处理读写的需求变得非常明显。这对SQL数据库提出了巨大挑战。为了解决这个问题,出现了支持数据可扩展性、最终一致性的NoSQL数据库。因此,NoSQL数据库可以看作是基于SQL数据库的缺陷而诞生的一种新产品。
NoSQL组件普遍选择牺牲复杂SQL的支持及ACID事务功能,以换取弹性扩展能力和更高的读写性能。这类系统主要存储半结构化或非结构化数据。根据存储的数据种类,NoSQL数据库主要分为基于文档存储的文档数据库(Document-based Database)、基于键-值存储的键值数据库(Key-Value Database)、图数据库(Graph-based Database)、时序数据库(Time Series Datebase)、宽列式存储(Wide Column-based Store)以及多模数据库(Multi-Model Database)。
不同类型的NoSQL数据库特性如下图所示。
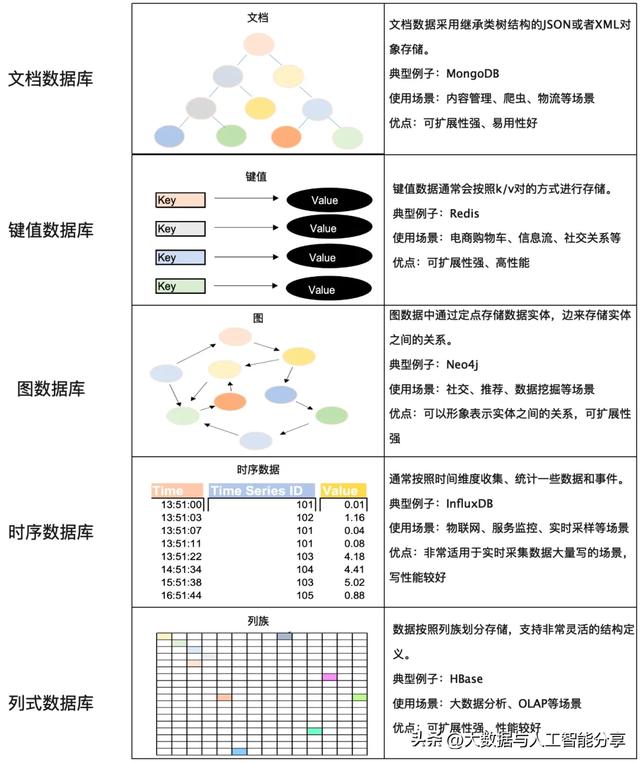
NoSQL数据库典型的特点是具备很高的读写性能,但数据一致性保证较弱。绝大多数的NoSQL数据库适合写多读少、写多读多的场景。以列式数据库、时序数据库而言,它们通过LSM的思想,提供了非常高的写入性能。这类系统的存储引擎广泛意义上也称为LSM Tree存储引擎,这些系统单机的存储引擎有RocksDB、LevelDB等。此外再以键值数据库为例,它们绝大部分通过利用哈希表这种数据结构,外加内存介质存储数据。实现非常高的读写性能。Redis就是这类系统的典型代表。
3. NewSQL数据库
虽然NoSQL数据库解决了关系型数据库存储的缺陷,但它也没法完全替代掉关系型数据库。在NoSQL数据库出现后的一段时间内,互联网软件的构建基本上都是结合二者来提供服务。在不同的场景下选择不同的数据库进行存储数据。虽然这样的合作方式很好,但是在这样的模式下,一个用户可能会因为场景的不同而存储多份相同的数据到不同的数据库中,当用户量级和存储数据量很小的情况下没什么问题。一旦量级发生变化就会引发出新的问题。
随着存储数据量的不断增加,造成资源的浪费和成本的上升不容忽略。于是工业界和学术界都在寻找更好的解决方案,直到2010年左右,诞生了NewSQL数据库(也称为分布式数据库)。它的出发点是结合关系型数据库事务一致性,又具备NoSQL数据库的扩展性及访问性能。这无疑给系统的设计及实现带来了更大的挑战,NewSQL数据库不仅要考虑单机环境下高效存储的问题,还需要考虑多机情况下数据复制、一致性、容灾、分布式事务等问题。目前NewSQL数据库典型的代表作有TiDB、OceanBase、CockroachDB等。NewSQL数据库中绝大部分的系统还是采用LSM 树存储引擎,来实现系统高性能的写入。
02OLTP&OLAP&HTAP对比
在现代数据管理领域,OLTP、OLAP和HTAP是常见的数据库类型,它们各自针对不同的数据处理场景和需求。本文将对这三种数据库进行对比,以帮助读者更好地理解它们的特点和适用性。
1. OLTP数据库
OLTP数据库(联机事务处理)是专门设计用于处理事务性工作负载的数据库系统。它们被广泛应用于业务应用程序,如在线购物、银行交易和订单处理等。OLTP数据库的主要特点是高并发、低延迟和高事务吞吐量。它们通过支持ACID(原子性、一致性、隔离性和持久性)特性来确保数据的一致性和可靠性。OLTP数据库通常采用规范化的数据模型,以支持高效的事务处理和即时的数据更新。
OLTP数据库主要的功能是处理用户在线实时的请求,直接为用户提供服务,因此这类数据库通常对处理请求的时延要求比较高,绝大部分的请求正常情况下会在毫秒级完成。OLTP数据库很多,除了大家最熟悉的关系型数据库(如MySQL、Oracle)外,还有Redis、MongoDB等这些非关系型数据库。绝大部分的OLTP数据库则是采用B树、B+树甚至哈希表来构建存储引擎。
2. OLAP数据库
OLAP数据库(联机分析处理),它们专注于支持决策支持和分析工作负载。OLAP数据库用于处理大量数据的复杂分析查询和报表生成。OLAP系统的关键特点是高度可扩展、支持复杂的分析操作和提供灵活的数据聚合能力。为了实现这些特性,OLAP数据库通常采用了针对分析查询优化的特殊数据结构,如多维数据模型(如星型或雪花模型)和列存储技术。此外,OLAP数据库还提供了灵活的查询语言和数据切片、切块、钻取等功能,以支持交互式的数据分析和探索。
OLAP数据库在功能上侧重于对数据或者任务进行离线处理,它不直接对用户提供服务。OLAP系统对请求的处理通常比OLTP慢得多,一般在秒级、分钟级甚至小时级,通常在数据统计、报表分析、推荐系统数据聚合分析等场景用的比较多。这一类数据库典型的代表有HBase、Teradata、Hive、Presto、Druid、ClickHouse等。互联网企业往往都需要使用OLTP和OLAP。因此为了满足这两类需求,通常需要结合多个系统一起开发使用。这样的做法当然是可行的,而且基本也是采用这种方式进行实现。绝大部分的OLAP数据库是采用LSM树构建存储引擎。
3. HTAP数据库
随着数据处理需求的不断演变,需要存储的数据量爆炸式增长,在这种模式下直接带来的存储成本问题成为新的矛盾点,人们开始探索是否能诞生一种数据库将OLTP和OLAP这两类应用合二为一呢?于是,HTAP(混合事务/分析处理)数据库应运而生。HTAP数据库旨在将OLTP和OLAP的功能集成到同一个数据库系统中,以满足实时分析和事务处理的需求。HTAP数据库通过在同一数据库上同时支持事务处理和分析查询,消除了数据复制和数据移动的需求,提供了更高的数据一致性和实时性。HTAP数据库通常采用了内存计算、分布式架构和智能查询优化等技术,以保证高性能和灵活性。这类数据库既可以处理在线事务处理,又可以处理在线分析处理。可以认为HTAP=OLTP+OLAP。HTAP的主要代表有TiDB、OceanBase、CockroachDB等。
在选择数据库时,需要考虑具体的业务需求和性能要求。如果您需要处理大量的事务性工作负载,如在线交易,那么OLTP数据库是一个理想的选择。如果您的需求是进行复杂的数据分析和报表生成,那么OLAP数据库可能更适合。而如果您需要同时满足实时分析和事务处理的需求,那么HTAP数据库是一个值得考虑的选项。
总而言之,OLTP、OLAP和HTAP数据库各自针对不同的数据处理场景和需求。了解它们的特点和适用性,可以帮助您在选择数据库时做出明智的决策,并确保满足业务的需求和性能要求。
03总结
如果以组件的类型是关系型数据库还是非关系型数据库,并结合服务的场景是OLTP还是OLAP来对业界各种存储组件进行划分的话,可以得到如下图所示的结果。关系型数据库中既有为OLTP设计的,也有为OLAP设计的,同时还有新兴发展起来兼容二者的HTAP数据库。这些系统都有各自适用的业务场景,它们在存储引擎选型时,往往会根据适用场景来决定。如果是读多写少的场景,通常会选择B+树、哈希表来构建存储引擎。而如果是写多读少的场景,往往会选择LSM树来构建存储引擎。

本文摘编自《深入浅出存储引擎》。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号