Golang标准库深度解析 - 锁与信号量(sync)
发表时间: 2023-09-14 19:23
sync包提供了基本的同步基元,如互斥锁。除了Once和WaitGroup类型,大部分都是适用于低水平程序线程,高水平的同步使用channel通信更好一些。
本包的类型的值不应被拷贝。
虽然文档解释可能不够深入,或者浅显易懂,但是我觉得还是贴出来,对比了解可能会更好。
Go语言中实现并发或者是创建一个goroutine很简单,只需要在函数前面加上"go",就可以了,那么并发中,如何实现多个goroutine之间的同步和通信?答: channel 我是第一个想到的, sync, 原子操作atomic等都可以。
首先我们先来介绍一下sync包下的各种类型。那么我们先来罗列一下sync包下所有的类型吧。

type Cond struct { // L is held while observing or changing the condition L Locker // contains filtered or unexported fields}
Cond实现了一个条件变量,一个线程集合地,供线程等待或者宣布某事件的发生。
每个Cond实例都有一个相关的锁(一般是*Mutex或*RWMutex类型的值),它必须在改变条件时或者调用Wait方法时保持锁定。Cond可以创建为其他结构体的字段,Cond在开始使用后不能被拷贝。
条件等待通过Wait让例程等待,通过Signal让一个等待的例程继续,通过Broadcase让所有等待的继续。
在Wait之前需要手动为c.L上锁, Wait结束了手动解锁。为避免虚假唤醒, 需要将Wait放到一个条件判断的循环中,官方要求写法:

c.L.Lock()for !condition() { c.Wait()}// 执行条件满足之后的动作...c.L.Unlock() 

type Cond struct { L Locker // 在“检查条件”或“更改条件”时 L 应该锁定。} // 创建一个条件等待func NewCond(l Locker) *Cond// Broadcast 唤醒所有等待的 Wait,建议在“更改条件”时锁定 c.L,更改完毕再解锁。func (c *Cond) Broadcast()// Signal 唤醒一个等待的 Wait,建议在“更改条件”时锁定 c.L,更改完毕再解锁。func (c *Cond) Signal()// Wait 会解锁 c.L 并进入等待状态,在被唤醒时,会重新锁定 c.Lfunc (c *Cond) Wait()

package mainimport ( "fmt" "sync" "time")func main() { condition := false // 条件不满足 var mu sync.Mutex cond := sync.NewCond(&mu) // 创建一个Cond //让协程去创造条件 go func() { mu.Lock() condition = true // 改写条件 time.Sleep(3 * time.Second) cond.Signal() // 发送通知:条件ok mu.Unlock() }() mu.Lock() // 检查条件是否满足,避免虚假通知,同时避免 Signal 提前于 Wait 执行。 for !condition { // 如果Signal提前执行了,那么此处就是false了 // 等待条件满足的通知,如果虚假通知,则继续循环等待 cond.Wait() // 等待时 mu 处于解锁状态,唤醒时重新锁定。 (阻塞当前线程) } fmt.Println("条件满足,开始后续动作...") mu.Unlock()} 
type Locker interface { Lock() Unlock()}Locker接口代表一个可以加锁和解锁的对象。 是一个接口。
type Mutex struct { // contains filtered or unexported fields}Mutex 是互斥锁。Mutex 的零值是一个解锁的互斥锁。 第一次使用后不得复制 Mutex 。
互斥锁是用来保证在任一时刻, 只能有一个例程访问某个对象。 Mutex的初始值为解锁的状态。 通常作为其他结构体的你名字段使用, 并且可以安全的在多个例程中并行使用。
// Lock 用于锁住 m,如果 m 已经被加锁,则 Lock 将被阻塞,直到 m 被解锁。func (m *Mutex) Lock()// Unlock 用于解锁 m,如果 m 未加锁,则该操作会引发 panic。func (m *Mutex) Unlock()
package mainimport ( "fmt" "sync")type SafeInt struct { sync.Mutex Num int}func main() { waitNum := 10 // 设置等待的个数(继续往下看) count := SafeInt{} done := make(chan bool) for i := 0; i < waitNum; i++ { go func(i int) { count.Lock() // 加锁,防止其它例程修改 count count.Num = count.Num + i fmt.Print(count.Num, " ") count.Unlock() done <- true }(i) } for i := 0; i < waitNum; i++ { <-done }}[ `go run sync_mutex.go` | done: 216.47974ms ] 1 4 8 8 10 15 21 30 37 45
注意:多次输出结果不一致, 试想为什么会出现10个结果中有0值得, 为什么10个结果中都大于0呢?或者都大于1呢? 那么会不会出现10个结果中最小值是9 呢?
type Once struct { // contains filtered or unexported fields}Once是只执行一次动作的对象。
Once 的作用是多次调用但只执行一次,Once 只有一个方法,Once.Do(),向 Do 传入一个函数,这个函数在第一次执行 Once.Do() 的时候会被调用,以后再执行 Once.Do() 将没有任何动作,即使传入了其它的函数,也不会被执行,如果要执行其它函数,需要重新创建一个 Once 对象。
// 多次调用仅执行一次指定的函数 ffunc (o *Once) Do(f func())
package main// 官方案例import ( "fmt" "sync")func main() { var once sync.Once var num int onceBody := func() { fmt.Println("Only once") } done := make(chan bool) for i := 0; i < 10; i++ { go func() { once.Do(onceBody) // 多次调用 done <- true }() } for i := 0; i < 10; i++ { <-done }}
type RWMutex struct { // 包含隐藏或非导出字段}RWMutex是读写互斥锁。该锁可以被同时多个读取者持有或唯一个写入者持有。RWMutex可以创建为其他结构体的字段;零值为解锁状态。RWMutex类型的锁也和线程无关,可以由不同的线程加读取锁/写入和解读取锁/写入锁。
Mutex 可以安全的在多个例程中并行使用。

// Lock 将 rw 设置为写锁定状态,禁止其他例程读取或写入。func (rw *RWMutex) Lock()// Unlock 解除 rw 的写锁定状态,如果 rw 未被写锁定,则该操作会引发 panic。func (rw *RWMutex) Unlock()// RLock 将 rw 设置为读锁定状态,禁止其他例程写入,但可以读取。func (rw *RWMutex) RLock()// Runlock 解除 rw 的读锁定状态,如果 rw 未被读锁顶,则该操作会引发 panic。func (rw *RWMutex) RUnlock()// RLocker 返回一个互斥锁,将 rw.RLock 和 rw.RUnlock 封装成了一个 Locker 接口。func (rw *RWMutex) RLocker() Locker
注意,Lock() 锁定时,其他例程是无法读写的。
1. 可以读时, 多个goroutine可以同时读。
2. 写的时候, 其他goroutine不可读也不可写。
代码实例:

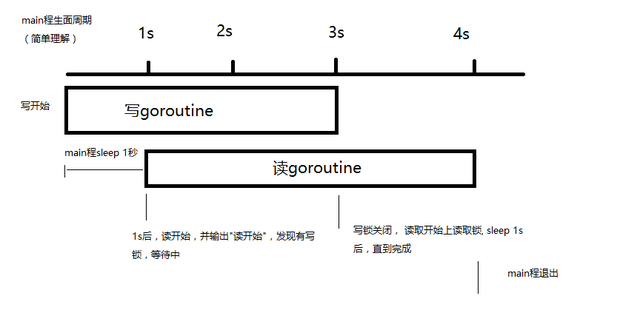
package mainimport ( "fmt" "sync" "time")var m *sync.RWMutexvar wg sync.WaitGroupfunc main() { m = new(sync.RWMutex) wg.Add(2) go write(1) time.Sleep(1 * time.Second) go read(2) wg.Wait()}func write(i int) { fmt.Println(i, "写开始.") m.Lock() fmt.Println(i, "正在写入中......") time.Sleep(3 * time.Second) m.Unlock() fmt.Println(i, "写入结束.") wg.Done()}func read(i int) { fmt.Println(i, "读开始.") m.RLock() fmt.Println(i, "正在读取中......") time.Sleep(1 * time.Second) m.RUnlock() fmt.Println(i, "读取结束.") wg.Done()}> Output:command-line-arguments1 写开始.1 正在写入中......2 读开始.1 写入结束.2 正在读取中......2 读取结束.> Elapsed: 4.747s> Result: Success
当写入开始时,加写锁开始写入, 一秒后, 读取goroutine开始读取, 发现有写入锁,只能等待。 2秒后写入完成, 解除写锁, 读取开始加锁,直到读取完成。
type WaitGroup struct { // contains filtered or unexported fields}WaitGroup用于等待一组线程的结束。父线程调用Add方法来设定应等待的线程的数量。每个被等待的线程在结束时应调用Done方法。同时,主线程里可以调用Wait方法阻塞至所有线程结束(计数器归零)。

// 计数器增加 delta,delta 可以是负数。func (wg *WaitGroup) Add(delta int)// 计数器减少 1func (wg *WaitGroup) Done()// 等待直到计数器归零。如果计数器小于 0,则该操作会引发 panic。func (wg *WaitGroup) Wait() 

func main() { wg := sync.WaitGroup{} wg.Add(10) for i := 0; i < 10; i++ { go func(i int) { defer wg.Done() fmt.Print(i, " ") }(i) } wg.Wait()}
输出是无序的。
注意此处有一个小坑,看代码:

func main() { wg := sync.WaitGroup{} for i := 0; i < 10; i++ { go func(i int) { wg.Add(1) defer wg.Done() fmt.Print(i, " ") }(i) } wg.Wait()}
看输出,发现会小于10个,甚至一个也没有。问题就在于goroutine执行时间和main程的退出时间问题,导致Add()是否执行。
再有就是复制和引用了,如果将wg复制给goroutine作为参数,一定要使用引用,否则就是两个对象了。
那么介绍完上面所有的类型后, 我把Pool留到了最后,这也是要重点将的地方。

type Pool struct { noCopy noCopy local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal localSize uintptr // size of the local array // New optionally specifies a function to generate // a value when Get would otherwise return nil. // It may not be changed concurrently with calls to Get. New func() interface{}}
Pool 用于存储临时对象,它将使用完毕的对象存入对象池中,在需要的时候取出来重复使用,目的是为了避免重复创建相同的对象造成 GC 负担过重。其中存放的临时对象随时可能被 GC 回收掉(如果该对象不再被其它变量引用)。
从 Pool 中取出对象时,如果 Pool 中没有对象,将返回 nil,但是如果给 Pool.New 字段指定了一个函数的话,Pool 将使用该函数创建一个新对象返回。
Pool 可以安全的在多个例程中并行使用,但 Pool 并不适用于所有空闲对象,Pool 应该用来管理并发的例程共享的临时对象,而不应该管理短寿命对象中的临时对象,因为这种情况下内存不能很好的分配,这些短寿命对象应该自己实现空闲列表。
Pool 在开始使用之后,不能再被复制。
1.定时清理
文档上说,保存在Pool中的对象会在没有任何通知的情况下被自动移除掉。实际上,这个清理过程是在每次垃圾回收之前做的。垃圾回收是固定两分钟触发一次。而且每次清理会将Pool中的所有对象都清理掉!
2.如何管理数据
先看看这几个数据结构

type Pool struct { noCopy noCopy local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal localSize uintptr // size of the local array // New optionally specifies a function to generate // a value when Get would otherwise return nil. // It may not be changed concurrently with calls to Get. New func() interface{}} // Local per-P Pool appendix.type poolLocalInternal struct { private interface{} // Can be used only by the respective P. shared []interface{} // Can be used by any P. Mutex // Protects shared.}type poolLocal struct { poolLocalInternal // Prevents false sharing on widespread platforms with // 128 mod (cache line size) = 0 . pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte}
Pool是提供给外部使用的对象。其中的local成员的真实类型是一个poolLocal数组,localSize是数组长度。poolLocal是真正保存数据的地方。priveate保存了一个临时对象,shared是保存临时对象的数组。
为什么Pool中需要这么多poolLocal对象呢?实际上,Pool是给每个线程分配了一个poolLocal对象。也就是说local数组的长度,就是工作线程的数量(size := runtime.GOMAXPROCS(0))。当多线程在并发读写的时候,通常情况下都是在自己线程的poolLocal中存取数据。当自己线程的poolLocal中没有数据时,才会尝试加锁去其他线程的poolLocal中“偷”数据。

func (p *Pool) Get() interface{} { if race.Enabled { race.Disable() } l := p.pin() //获取当前线程的poolLocal对象,也就是p.local[pid]。 x := l.private l.private = nil runtime_procUnpin() if x == nil { l.Lock() last := len(l.shared) - 1 if last >= 0 { x = l.shared[last] l.shared = l.shared[:last] } l.Unlock() if x == nil { x = p.getSlow() } } if race.Enabled { race.Enable() if x != nil { race.Acquire(poolRaceAddr(x)) } } if x == nil && p.New != nil { x = p.New() } return x}
为什么这里要锁住。答案在getSlow中。因为当shared中没有数据的时候,会尝试去其他的poolLocal的shared中偷数据。Pool.Get的时候,首先会在local数组中获取当前线程对应的poolLocal对象。如果private中有数据,则取出来直接返回。如果没有则先锁住shared,有数据则直接返回。
Go语言的goroutine虽然可以创建很多,但是真正能物理上并发运行的goroutine数量是有限的,是由runtime.GOMAXPROCS(0)设置的。所以这个Pool高效的设计的地方就在于将数据分散在了各个真正并发的线程中,每个线程优先从自己的poolLocal中获取数据,很大程度上降低了锁竞争。
来源:
https://my.oschina.net/90design/blog/1814499
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号