腾讯大数据平台即将实现无人管理
发表时间: 2021-04-21 12:11
金磊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
接入消息量:55万亿
实时计算:65万亿
分析任务:1500万
……
可以想象吗?这些万亿级的数字,竟是一家企业每天都要处理的数据量。
没错,这就是腾讯大数据。
但更让人意想不到的是,它现在打算让如此海量的数据分析、处理工作,进入“无人驾驶”状态。

数据量之大暂且不提,单就安全这一块,不得拿捏到位吗?
原来,腾讯大数据的底气,来源于其最新发布的计算平台:
名曰腾讯大数据-天工,是腾讯自研的第四代数智融合计算平台。
而纵观对整个平台的介绍,可以说“打通”一词贯穿了所有。
具体而言,腾讯大数据要打通的是数据,是技术。
理想虽美好,但现实很残酷。
细思便知,数据结构等不一致带来的“孤岛”情况、数据安全等存在的隐患,以及不同技术融合背后的难度……
困难的程度,就不言而喻了。
那么此局又该如何破解?
一言蔽之,三步走:
一个“安全”,一个“统一”,最后一个“智能”。

先来谈谈安全。
目前“数据孤岛”的情况较为普遍,一来从逻辑角度来看,因不同部门、组织对数据的定义、理解的差别而形成;二来从物理角度,因各种数据的独立存储、独立维护而产生。
但欲消除“数据孤岛”,一个大前提就是要保障数据安全,而且是重中之重的那种。
自研的隐私计算技术,就是腾讯大数据解决这一难点的“锦囊”。特点如下:
或许这样的描述,在感官上并不够直接,那么接下来的一个数据便可体现隐私计算对安全要求的高度。
例如RSA密钥长度在安全性极高的金融领域,尚且是2048bit;而腾讯大数据隐私计算所采用的长度,则达到了3072bit!
除此之外,这项技术也早已有了“实践性的检验”。
在iDash 2020世界隐私计算大赛中,腾讯便凭借此技术夺得冠军,这也是中国企业在此项比赛中的第一次夺冠。

再来谈谈统一。
除了数据之外,腾讯大数据要在技术层面也要做到打通,具体而言,就是将人工智能(A)和大数据 (B)融为一体。
这也是反映出了目前业界存在的一个现状,也就是“A”和“B”的框架技术没有得到很好的复用。
虽然二者看似是“貌合神离”的样子,但其实它们的本质技术是类似的,例如:
因此,通过将人工智能和大数据技术的打通,便可以更好地适配CPU、GPU、NPU、FPGA等硬件。
最后,是智能。
腾讯大数据在这一步的目标较为清晰:
万亿级数据分析将实现“自动驾驶”。
这也是为了解决目前“大数据平台依赖人工”的问题。
为此,腾讯正在构建平台大脑,推动万亿级大数据分析逐步实现“自动化运营”。
究其本质,这也是一个从“被动”到“主动”的转变过程,即从“快速发现大数据运行问题”到“主动发现问题”,再到“主动解决问题”。
据介绍,腾讯的平台大脑预计可让数据中心研发效率提升60%,运营效率提升50%,平台服务质量提升80%。
……
但总归“第四代数智融合计算平台”是一个较大的概念,是否有更为具体的产品?
有的,Angel PowerFL,腾讯借此之际,还正式推出了这款安全联合计算平台。

据了解,Angel PowerFL拥有全栈的联邦学习和深度学习功能:
支持多方联邦逻辑回归、XGBoost、PCA、用户自定义神经网络模型,支持多方联邦模型在线serving和模型管理,支持联合数据分析。
在隐私保护方面,Angel PowerFL提供了多种机制的选择,包括同态加密、秘密分享、差分隐私、可信执行环境(如SGX)等。
在不同场景下,可以有针对性地选择不同的安全保护级别。
在迭代和部署方面,Angel PowerFL采用的是“计算层和服务层分离”的方式。
这样做的目的也为了更好地支持多种方式部署、灵活资源扩缩容。
而且所有的服务组件都是部署在K8S集群上,这样一来,就可以方便对接TensorFlow和PyTorch等常用深度学习框架,也利于进行分布式深度学习模型训练和推理。
最后,腾讯大数据联合腾讯研究院还推出了《腾讯隐私计算白皮书》,从多个方面,包括发展背景、技术体系、重点应用行业和场景、数据安全合规、未来发展前景等,对隐私计算做了深入的解读和研究。
正如刚才提到的,腾讯大数据的计算平台已经衍变到了“第四代”。
而纵观发展历程,此次的迭代并非是一蹴而就,而是step by step。
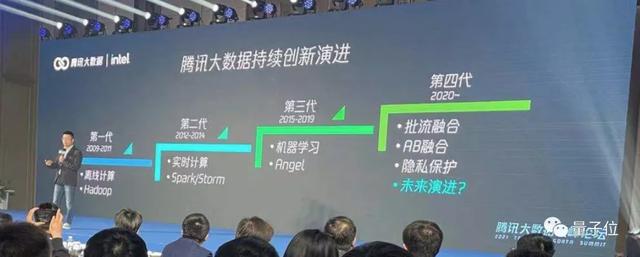
早在2009年,腾讯大数据便推出了第一代计算平台,主要模式是离线计算,主要依托Hadoop的生态,优化范围也是限于局部。
耗时较长,是第一代计算平台的劣势,处理任务的时间长达小时甚至是天的级别。
基于此,从2012年开始,腾讯大数据便着手于实时计算,并推出了第二代计算平台。
当时,基于Spark/Storm等实时计算处理框架,让腾讯大数据在处理任务上步入了“毫秒时代”。
而到了2015年左右,深度学习在全球可谓是刮起了一阵热潮,在此趋势的推动下,腾讯大数据推出了第三代计算平台。
与此同时,自研机器学习框架Angel,也成为国内第一个从Linux基金会“毕业”的AI项目。
而到了2020年,腾讯大数据有了新的思考。
一方面,是来源于数据规模的不断扩大,已经到了需要将流式计算和批量计算做融合、AI体系和大数据体系做融合的阶段。
另一方面,是来源于对数据隐私的思考:
如何在数据“足不出户”的情况下,既做到数据流、应用流和交易流的融合,又能保障数据的隐私安全。
不难看出,腾讯大数据计算平台到现在的发展,实则是基于每一阶段的“硬需求”而做出的变化。
与此同时,也完成了从依赖开源,到自主研发的华丽转身。
最后的一个问题:
该如何来看待腾讯第四代数智融合计算平台?
首先,出发点是非常的清晰了。
大数据这座矿山的价值,在数智深度融合的当下并没有发挥全部的潜能,甚至很大一部分的能量还有待开发。
并且大数据已然成为新型基础设施的重要组成部分,相关产业的发展正是迎来新阶段的关键时刻。
安全地打破“数据孤岛”,无疑会加速和提升大数据自身及产业的价值。
其次,让数据分析“自动驾驶”是否够靠谱。
众所周知,在自动驾驶领域会对车辆按照智能化来分级,一个形象的比喻就是“L3是发现问题”、“L4是分析问题”,而“L5是自动解决问题”。
腾讯大数据对自身的技术现状,则定位在了向L4迈步,并给出了对于未来“自动驾驶”的理解:
希望对平台所有软硬件指标都能完整收集,并形成知识图谱,平台里任何一个问题和异常,平台大脑能第一时间感知,根据问题图谱进行根因分析,精准定位源头,是软件引起的还是硬件引起的,并能根据异常的不同影响级别,根据决策树和现网知识库形成最适合的处理方式。
这个过程,不需要人工来干预,都是平台自身智能地在处理,极大地解放研发和运维人员的生产力。
其中之关键之一就是隐私计算,是另一个值得讨论的话题。
虽然是由谷歌率先提出,但随着理论与实践的不断碰撞,加之实际应用场景规模之大,它已然不是最初的那个“味道”。
因此不得不说,隐私计算技术目前还是处于早期阶段,需要解决和应对的问题还有很多:
开源技术是否会最终再次趋同?技术演进方向会怎样?与法律法规又该如何碰撞?
腾讯大数据给出的答案是:
让子弹再飞一会,鼓励技术有百花齐放的状态。
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号