后端接口与日志请求存储的数据埋点解析
发表时间: 2021-02-18 17:12
编辑导读:数据埋点作为数据分析、数据仓储等的基础,在设计数据埋点的时候我们不光要依据前端特性去设计前端的数据埋点,还需要了解后端特性结合业务进行埋点设计。本文作者对此五个维度的分析,希望对你有帮助。

一般只要说到数据埋点通常情况下都是指前端的数据埋点,而并非后端数据埋点。所以往往会忽视后端埋点在整个数据埋点的作用。数据埋点作为数据分析、数据仓储等的基础,在设计数据埋点的时候我们不光要依据前端特性去设计前端的数据埋点,还需要了解后端特性结合业务进行埋点设计。
可能对于我们来说,只有前端内容是我们最直观感受,从而花费大量功夫去处理前端的埋点设计,而对于看不见的后端埋点我们往往忽视。这样使我们产品设计师(产品经理)对于数据埋点的设计理解局限在了前端交互上,把同样重要的后端埋点设计直接交给研发leader或是架构师自主设计不管不顾,这是不对的。至此本次我们聊一下后端埋点,以便配合研发leader和架构师开展工作。
数据埋点的最终归宿地都会是数据库,不管它是前端埋点还是后端埋点他们都会存入MySql或MongoDB的数据库中(数据库类型)。
相比较前端埋点在可视化页面上交互和触发,后端埋点更多是在对业务数据的请求和记录上。前后端进行比较,后端埋点在存储用户操作数据上会比前端晚一步 ,但在业务流程上又会比前端快一步。是因为当用户进入页面操作时,都是在页面上先进行操作,所有前端埋点的触发永远会比后端埋点快一步。但是在业务流程上(例如登录,订购等),后端埋点会比前端埋点更快一步,因为业务需要后端会和数据库进行实时“互动”,在互动结束后才会将结果反馈给前端,再由前端和用户进行交互。
后端数据埋点不像前端那么多花样,要去思考用户路径和用户交互,后端埋点更加注重业务沉淀和业务逻辑。后端埋点和前端埋点一样,也分全量、模块化和代码埋点三种。除此之外,后端埋点还有个特殊方式就是日志。全量和模块化埋点我就不在过多阐述,因为他俩对于产品设计师(产品经理)来说没有太多的要求,直接沟通研发将对应的SDK或API装载即可,我们重点说代码和日志两种方式。
代码埋点:我们请了一个施工队,这个施工队听你的指挥,并根据你在高速路上指定的位置建造收费站,这种都是一砖一瓦的施工。
可视化(模块化)埋点:我们将需要建造的收费站进行模具化,只需要到指定位置放置模具,对模具直接浇灌水泥,收费站就直接成型。
全量埋点:直接组装卫星发射到天上,实时监控高速路上的用户行为。
和前端埋点相似,代码方式的埋点可控性高,成本也高。在理解后端埋点设计上,我们可以从前端埋点设计需要考虑的4大生命周期(页面的创建、加载、更新、销毁)进行过度理解。
因为后端的操作都在于代码的请求和运算(请求中),那么我们假设将整个后端埋点按照前端埋点设计的逻辑进行拆分,分别是请求前、请求中、请求后三个部分。
用户点击支付商品,用户触发前段埋点,这时前端向后端请求支付(请求前),后端根据前端请求过来的数据包内容「支付信息、商品信息、用户信息等」去验证这些正确性(请求中),随后将验证结果打包处理给到前端(请求后),让前端给用户继续交互(流程图经过缩减主要用于认知,只显示主要环节所以不必太过于较真)。
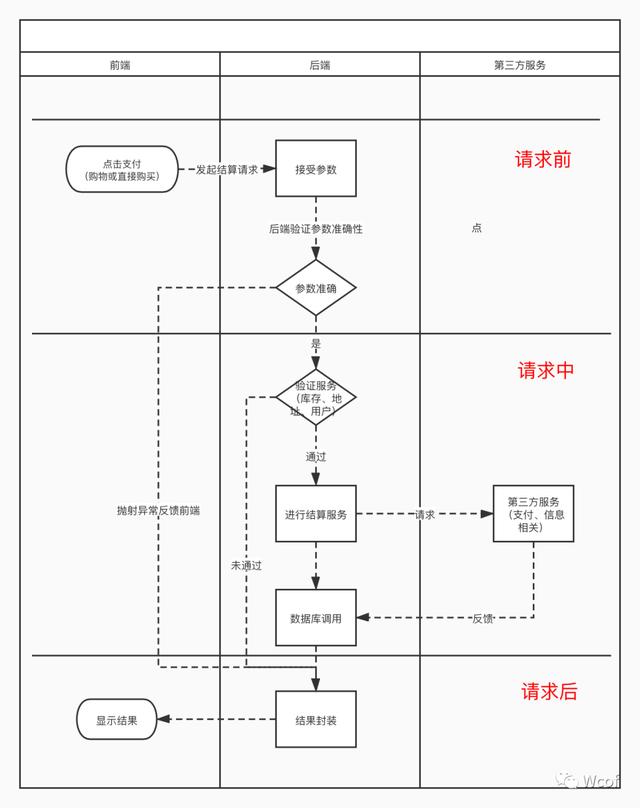
一般的验证可分为两部分,一种是数据的验证,后端对传输过来的加密参数进行头部验证,验证数据的安全性。以保证这个数据不是非法请求。另一个验证是业务验证,验证传输过来数据的准确性。用户信息对不对,库存对不对,支付密码对不对等。
文中的请求是以”前端”的视角在说。因为我们最有感知的请求中也就是我们常说的加载中。
单单关注请求是不足以支撑我们理解后端埋点。因为后端是方法函数之间的调用,所以,我们还需要关注“服务”。例如后端在接参(接收到前端页面的请求)后,需要将参数中用户信息拿着用户中心去做比对,用于验证用户的属性。与此同时将去商品中心验证商品sku的商品信息,并通过商品信息去查询正价和销售价。随后在去调用活动中心去查询活动信息,最后再由订单中心生成订单等等。
这也是为什么我说单单理解请求不足以支撑我们进行理解后端埋点。在了解这些内容后我们再去理解如何在方法函数中进行埋点,将会事半功倍。
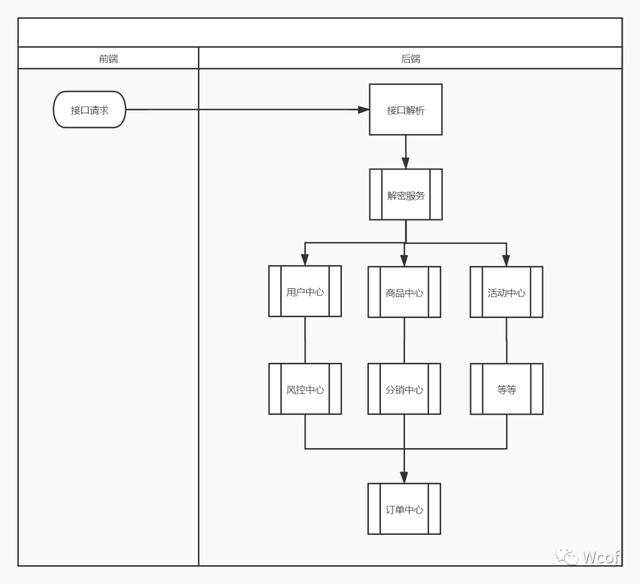
为什么我们不直接全部将埋点设计在前端,而是去做后端埋点。是因为如果设计通过前端埋点进行,首先不能放在页面创建,因为页面才创建显示出来的时候,用户还没进行操作,我们无法确定用户要办理什么业务(登录业务、支付业务、下单业务等),所以这里首先不能进行业务埋点。同时这里基本以图片加载为主,让用户更快了解主题。
其次不能放在页面加载位置,这样会多一次埋点请求,网络好,数据量小用户还感知不了。如果是淘宝、拼夕夕这种数据量大的C端应用,或是其他高并发的B端软件,可能因为要多发一次埋点请求,会大大增加用户的等待时间,造成体验不流畅。
最后还是不能放在页面销毁,用户突然将页面关了(网页:直接关闭浏览器、APP:直接清空后台运行)都会造成埋点还没请求还没发出就没了,让数据采集不够完善。
所以不采用前端对业务进行埋点,并且使用后端埋点,在对数据进行采集的时候是一个同步操作,和用户的业务是同时开展的,因此将不会影响用户在前端体验上的任何操作和业务开展。
后端埋点除了接口服务的请求进行埋点外,还有一种方法叫日志。在真实的工作环节中,后端代码埋点的可用性很差。首先,因为后端是操作数据和业务数据数据交互的地方,只要后端不出问题,前端出再多的问题也无伤大雅。这也是往往我们看见很多软件应用,前端页面垃圾(样式垃圾,交互反人类,点击按钮没反馈等),但却依然对外使用。
其次,说可用性差是因为应用总归是需要对外或对内使用,会面临大量数据请求,100个业务请求就需要触发后端埋点100次,还有可能因为业务的复杂性会调用几个或十几个服务,这时我们的数据埋点可能触发不止100次,而且这些请求都是需要额外的服务器资源去处理。当出现高并发场景时(抢购、秒杀等等),这样的数据埋点可能会暂用大量的资源,最后从而影响到业务服务让服务器“暴毙”。面对这样的情况,也就有了第二次后端埋点的方法,日志埋点。
日志本就是后端代码框架的一部分组件算是自带,一般以.log结尾的文件,几乎就是日志文件,如果不懂我们也可以将日志文件看成TXT、word文档便于理解(以liunx登录日志为例,会显示每次的登录位置(IP)、登录时间等)。
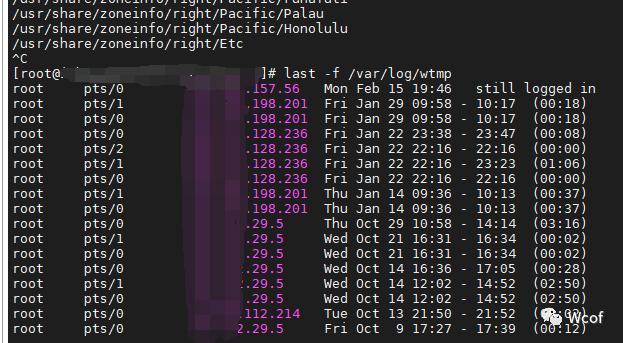
首先,我告诉大,几乎所有的软件应用的所有运行行为都会产生日志,关键在于我们需不需要使用,需不需要对相关日志进行采集保存而已。常见的系统日志会分为五个等级,分别是:
一级DEBUG:研发主要用于日常的调试,所以在调试时随处可见。
二级INFO(information):重要结果的输出,在一些函数方法结果的位置可以看见,主要是用于关键结果。
三级WARNING:普通报错级别,代表不会影响系统的运行,常见账号密码错误和一些奇奇怪怪的地方。
四级ERROR:重要错误级别,代表系统无法继续运行。
五级CRITICAL:重大错误,估计直接服务器爆炸了(几乎不见)
在以上五个日志级别中,对于三级WARNING、四级ERROR、五级CRITICAL我们不用去管,这个对于我们产品来说用处不大,主要是研发用于定位问题。而二级INFO才是我们主要日志埋点使用。
在后端设计中,日志的使用上极为便捷。因为现在大多数后端都喜欢使用Java作为研发语言,并采用spring boot作为技术栈有十分成熟的日志解决方案这里我就不过的阐述技术上的了(未使用也不急,日志是基本功能,几乎99%的后端技术栈都有各自的解决方案)。
在日志埋点的设计上尽可能提升日志数据的宽度。何为宽度?宽度是指尽可能穷举完某个需求或业务所需要日志记录的数据字段。
例如,在生成订单的时候日志是否需要,用户ID、订单ID、当前金额、商品SKU、平台ID等等。因为数据的延后行,只有你保存到日志的数据才有记录,没有保存的就没有,所有就算你当前不使用相关数据,但是你的宽度足够,在后期需要时,也可以从日志中提取出来。
如果宽度不够,在需要使用某些日志未存储的数据时,只能修改日志,从零开始。因此,在设计日志宽度的时候,除了从业务入手以外,产品设计师(产品经理)还需要沟通后端研发、后端技术leader和后端架构师进行相互研磨便于完善宽度。
日志的设计要点和上面代码埋点中讲述的场景有异曲同工之妙。唯一不同的是我们不用再去关注什么请求前、请求中和请求后。我们只需要关注的是结果封装这里。关注各个服务之间的结果,将需要的内容放入日志保存即可。
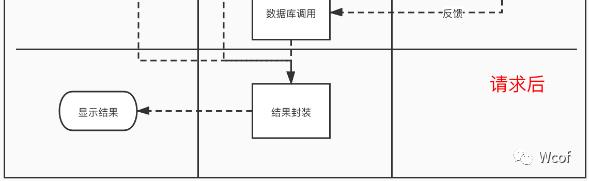
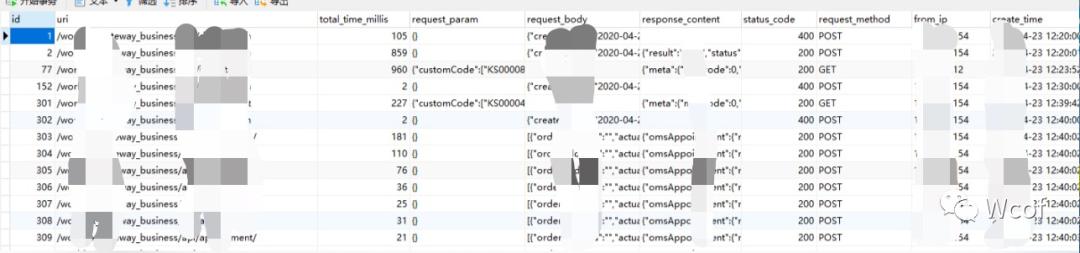
在我们采用日志作为数据埋点方式的时候会存在一个问题,日志文件里面的数据量会越来越大,这个时候我们每次再去日志中提取数据,会因为数据体量的问题,变得十分缓慢。面对这样的情况我们可以将日志中部分常用关键数据提取出来,用数据库进行存储。后期需要使用的时候直接通过数据库获取即可,不用采取查阅日志。将日志作为溯源文件即可。
作者:wcof,在努力做产品不做产品经理的人;微信公众号:Wcof(ID:wcofPM)
本文由 @Wcof 原创发布于人人都是产品经理,未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号