Redis全面解析系列《一》:简介、安装与架构演变
发表时间: 2023-09-26 21:32
一、前言二、概述三、Redis简介 1、是什么 2、为什么用它 3、优点四、如何安装 1、windows安装 1)获取安装包 2)启动服务端 3)客户端连接 2、linux安装 1) 获取源码 2)编译 3)安装 4)启动服务端 5)客户端连接五、基础知识-架构 1、单机架构 2、主从架构 3、哨兵架构 4、集群架构相关知识点均基于Redis最新版本7.2.1
本文作为小郭为复习Redis知识而总结的第一篇文章,主要介绍Redis出现的背景、如何安装和访问Redis、Redis架构演变过程。
后续小郭会围绕并不限于下面几个部分继续学习Redis并输出相关笔记(有兴趣的小伙伴可以关注我,一起彻底搞懂Redis):
1)缓存读写请求执行流程2)配置文件详解3)数据类型4)事务管理5)缓存淘汰策略6)数据持久化机制7)发布与订阅机制8)常用命令9)常见问题10)其它目前计算机世界中的数据库共有2种类型:关系型数据库、非关系型数据库。
常见的关系型数据库解决方案(SQL)
MySQL、MariaDB(MySQL的代替品)、Percona Server(MySQL的代替品·)、Oracle、PostgreSQL、Microsoft Access、Google Fusion Tables、SQLite、DB2、FileMaker、SQL Server、INFORMIX、Sybase、dBASE、Clipper、FoxPro、foshub。
几乎所有的数据库管理系统都配备了一个开放式数据库连接(ODBC)驱动程序,令各个数据库之间得以互相集成。
常见的非关系型数据库解决方案(NoSQL)
NoSQL 即 Not Only SQL
Redis、MongoDB、Memcache、HBase、BigTable、Cassandra、CouchDB、Neo4J。
目前小郭的工作经历里使用最多的就是Redis了。
关系型数据库和非关系型数据库的区别
区别就是一个叫关系型,一个叫非关系型~ 这么解释网友们会不会打残我? 哈哈哈 下面来个正经一点的解释。
关系型数据库最典型的数据结构是表,由二维表及其之间的联系所组成的一个数据组织,有如下优缺点。
优点:
缺点:
非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合,可以是文档或者键值对等。有如下优缺点。
优点:
缺点:
再来说说为什么需要非关系型数据库技术。
小郭结合自己的工作经验来总结一下(不喜轻点喷~),目前的软件产品从用户角度主要分为几个方向:
这个方向的软件产品是目前市面上最多的,面向的主要是个人用户,遵循比较规范的产品流程。 通常这类软件的用户量基数巨大且增长快,比如美团的年度交易用户数已从2015年的2亿人,增长到2022年的6.87亿人(2022年Q3财报),平均每2个中国人就有一个在美团上花过钱。用户量大,对性能的要求也会比较高,有可能一瞬间成千上万的请求到来(抢购、促销活动场景不可控),需要系统在极短的时间内完成成千上万次的读/写操作,这个时候往往不是关系型数据库能够承受的,极其容易造成数据库系统瘫痪,最终导致服务宕机的严重生产问题, 因此需要引入缓存解决方案,减少对关系型数据库的影响。 Redis就是一个不二选择。
随着近年来不断倡导互联网+,政府也纷纷进行转型,寻求更好的商业模式。To G是从 To B衍生出来的一种特殊划分,面向的企业为政府或相关事业单位,主要是根据每年政府投入的财政预算,然后去做的一系列信息化项目,可以说是“指标驱动,为做项目而做项目”。这类项目有两个极端场景,一类是用户量极低,提供给内部使用的,本地化部署; 还有一类是面向老百姓的,用户量也大,但是对并发要求并不高,比如政务类软件。
举个栗子:智能考车系统,是典型的公安部主导的一款To G产品,使用对象是考官和公安部相关管理等内部人员,用户量不多;而“交管12123”是直接提供给老百姓使用的APP,可以自行预约考试,处理违章等,面向的是全国十几亿人,用户基数大,海量数据,完全依赖传统的关系型数据库肯定会降低应用访问性能,因此也需要引入新的非关系型数据库解决方案来开发程序功能。
这个方向的产品一般是面向商业企业用户的,一般不向大众用户公开。用户量相对较少,通常情况对性能的要求比To C类产品要低一些,一般大部分场景都是直接使用关系型数据库进行数据存储,少部分场景也会额外依赖非关系型数据库。
一句话总结:To C使用场地是随时对地;ToB更多是内网;To G是内外网相结合(互联网+政务)
软件研发产品大体是包括这三大类(当然还有To VC , To P 的一些分法,也没错,只是立足点不同)
目前业界的技术选型原则基本是:核心数据存储选择关系型数据库,次要数据存储选择非关系型数据库。
本文接下来主要总结非关系型数据库中的Redis技术的相关知识。
redis的官网地址,是redis.io。(域名后缀io属于国家域名,是british Indian Ocean territory,即英属印度洋领地),Vmware在资助着redis项目的开发和维护。
从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助。
据说有一名意大利程序员,在 2004 年到 2006 年间主要做嵌入式工作,之后接触了 Web,2007 年和朋友共同创建了一个网站,并为了解决这个网站的负载问题(为了避免 MySQL 的低性能),于是亲自定做一个数据库,并于 2009 年开发完成,这个就是 Redis。这个意大利程序员就是 Salvatore Sanfilippo 江湖人称 Redis 之父,大家更习惯称呼他 Antirez。
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。Redis属于非关系型数据库中的一种解决方案,目前也是业界主流的缓存解决方案组件。
数百万开发人员在使用Redis用作数据库、缓存、流式处理引擎和消息代理。
Redis是当前互联网世界最为流行的 NoSQL(Not Only SQL)数据库,它的性能十分优越,其性能远超关系型数据库,可以支持每秒十几万此的读/写操作,并且还支持集群、分布式、主从同步等配置,理论上可以无限扩展节点,它还支持一定的事务能力,这也保证了高并发的场景下数据的安全和一致性。
最重要的一点是:Redis的社区活跃,这个很重要。
Redis 已经成为 IT 互联网大型系统的标配,熟练掌握 Redis 成为开发、运维人员的必备技能。
官方的 Benchmark 数据:测试完成了 50 个并发执行 10W 个请求。设置和获取的值是一个 256 字节字符串。
测试结果:Redis读的速度是110000次/s,写的速度是81000次/s 。
支持 Strings, Lists, Hashes, Sets 及 Ordered Sets 数 据类型操作。
所有的操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
提供了缓存淘汰策略、发布定义、lua脚本、简单事务控制、管道技术等功能特性支持
Redis在Windows上不受官方支持。但是,有开源爱好者提供了window的免安装方式,因此我们还是可以按照下面的说明在Windows上安装Redis进行开发。
操作非常简单,下面进行步骤说明。
直接下载开源的redis-window版本安装包:
https://github.com/tporadowski/redis/releases
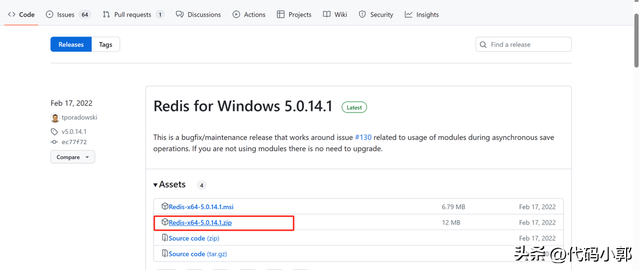
下载好后解压到本地磁盘某个目录(小郭这里是D:\Redis-x64-5.0.14.1),目录结构如下:
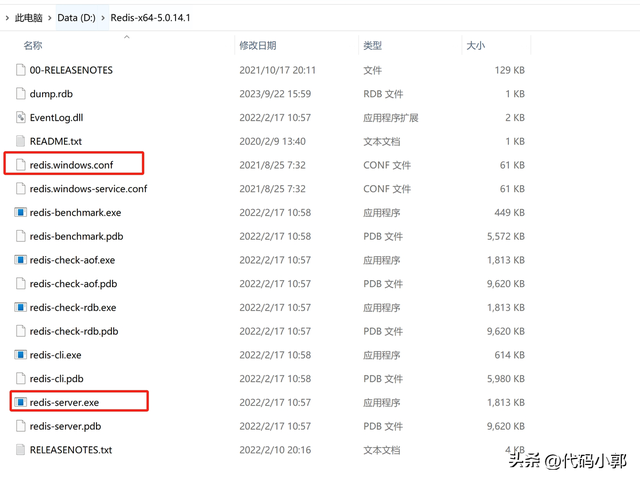
redis-server.exe和redis.windows.conf就是我们接下来要用到的重要文件了。
打开一个 cmd 窗口, 使用 cd 命令切换目录到 D:\Redis-x64-5.0.14.1 运行如下命令:
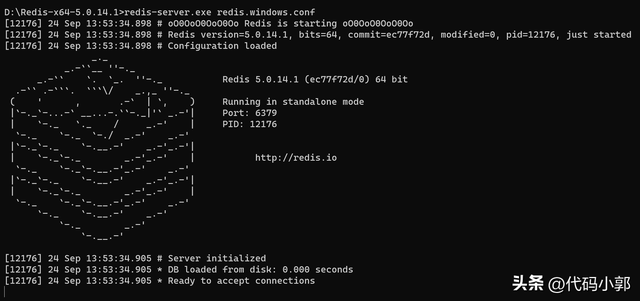
redis-server.exe redis.windows.conf如果想方便的话,可以把 redis 的路径加到系统的环境变量里,这样就省得再输路径了,后面的那个 redis.windows.conf 可以省略,如果省略,会启用默认的。输入之后,会显示如下界面:
接下来保持这个cmd界面不要关闭,我们启动一个客户端去连接服务端。
服务端程序启动好之后,我们就可以用客户端去连接使用了,目前已经有很多开源的图形化客户端比如Redis-Desktop-Manager,redis本身也提供了命令行客户端连接工具,接下来我们直接用命令行工具去连接测试。
另启一个 cmd 窗口,原来的不要关闭,不然就无法访问服务端了。切换到目录D:\Redis-x64-5.0.14.1,执行如下命令:
redis-cli.exe -h 127.0.0.1 -p 6379设置一个key名为"hello",value是"world"的键值对:
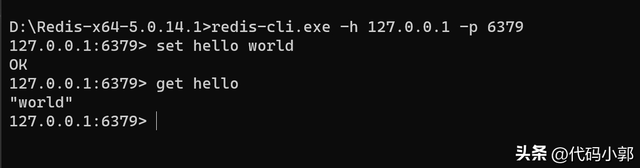
上面的日志显示成功连接到了redis服务,并且设置了一个key名为"hello",value是"world"的键值对数据。
linux安装redis的方式也有多种,小郭这里仅演示源码安装的方式。
使用wget命令从官网下载最新的源码包
root@xxx guoyd]# wget https://download.redis.io/redis-stable.tar.gz
root@xxx guoyd]# tar -xvf redis-stable.tar.gz root@xxx guoyd]# cd redis-stableroot@xxx guoyd]# ll[root@xxx redis-stable]# lltotal 244-rw-rw-r-- 1 guoyd guoyd 18320 Sep 7 01:56 00-RELEASENOTES-rw-rw-r-- 1 guoyd guoyd 51 Sep 7 01:56 BUGS-rw-rw-r-- 1 guoyd guoyd 5027 Sep 7 01:56 CODE_OF_CONDUCT.md-rw-rw-r-- 1 guoyd guoyd 2634 Sep 7 01:56 CONTRIBUTING.md-rw-rw-r-- 1 guoyd guoyd 1487 Sep 7 01:56 COPYINGdrwxrwxr-x 8 guoyd guoyd 4096 Sep 7 01:56 deps-rw-rw-r-- 1 guoyd guoyd 11 Sep 7 01:56 INSTALL-rw-rw-r-- 1 guoyd guoyd 151 Sep 7 01:56 Makefile-rw-rw-r-- 1 guoyd guoyd 6888 Sep 7 01:56 MANIFESTO-rw-rw-r-- 1 guoyd guoyd 22607 Sep 7 01:56 README.md-rw-rw-r-- 1 guoyd guoyd 107512 Sep 7 01:56 redis.conf-rwxrwxr-x 1 guoyd guoyd 279 Sep 7 01:56 runtest-rwxrwxr-x 1 guoyd guoyd 283 Sep 7 01:56 runtest-cluster-rwxrwxr-x 1 guoyd guoyd 1772 Sep 7 01:56 runtest-moduleapi-rwxrwxr-x 1 guoyd guoyd 285 Sep 7 01:56 runtest-sentinel-rw-rw-r-- 1 guoyd guoyd 1695 Sep 7 01:56 SECURITY.md-rw-rw-r-- 1 guoyd guoyd 14700 Sep 7 01:56 sentinel.confdrwxrwxr-x 4 guoyd guoyd 4096 Sep 7 01:56 srcdrwxrwxr-x 11 guoyd guoyd 4096 Sep 7 01:56 tests-rw-rw-r-- 1 guoyd guoyd 3628 Sep 7 01:56 TLS.mddrwxrwxr-x 9 guoyd guoyd 4096 Sep 7 01:56 utilsroot@xxx redis-stable]# make编译时间大概需要几分钟,如果编译成功,将看到如下输出日志:
.....日志太多,略......Hint: It's a good idea to run 'make test' ;)make[1]: Leaving directory `/home/guoyd/redis-stable/src'同时,在src目录中会生成几个 新的Redis 二进制文件:
redis-server: 代表redis服务本身的可执行程序redis-cli:redis提供的命令行工具,用于和redis服务端进行交互编译成功后,我们继续在源码根目录下使用make install将redis服务安装到默认目录usr/local/bin中:
[root@iZbp128dczen7roibd3xciZ redis-stable]# make installcd src && make installwhich: no python3 in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/usr/java/jdk1.8.0_201/bin:/root/bin)make[1]: Entering directory `/home/guoyd/redis-stable/src'CC Makefile.depmake[1]: Leaving directory `/home/guoyd/redis-stable/src'which: no python3 in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/usr/java/jdk1.8.0_201/bin:/root/bin)make[1]: Entering directory `/home/guoyd/redis-stable/src'Hint: It's a good idea to run 'make test' ;)INSTALL redis-serverINSTALL redis-benchmarkINSTALL redis-climake[1]: Leaving directory `/home/guoyd/redis-stable/src'[root@iZbp128dczen7roibd3xciZ redis-stable]#redis安装好了,我们可以在任意目录下执行redis-server命令启动服务端:
因为redis-server在安装环节已经被默认配置到了环境变量中,所以可以在任意目录执行
[root@xxx ~]# redis-server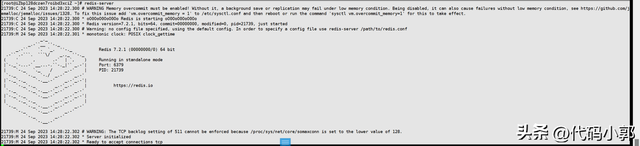
上面演示的是使用默认配置启动redis服务,如果我们想自定义配置,可以使用如下方式:
redis-server /xxx/xxx/redis.confredis.conf是redis的核心配置文件,我们可以按需进行配置修改。
在源码redis-stable的根目录中也提供了配置文件的模板redis.conf, 小郭会在本文后续章节中对这个配置文件做详细说明。
和window版本一样,有很多开源图形化客户端,我们这里还是使用redis自带的命令行工具去连接。
另启一个 linux终端,原来的不要关闭,不然就无法访问服务端了。重新打开一个linux终端,执行如下命令:
当然这里也有办法直接让redis在后台运行,重新打开一个终端的操作不是必要的。
[root@xxx ~]# redis-cli.exe -h 127.0.0.1 -p 6379-bash: redis-cli.exe: command not found[root@iZbp128dczen7roibd3xciZ ~]# redis-cli -h 127.0.0.1 -p 6379127.0.0.1:6379> set hello worldOK127.0.0.1:6379> get hello"world"127.0.0.1:6379>上面的操作成功连接到了redis服务,并且使用set命令设置了一个key名为"hello",value是"world"的键值对数据。
此时,我们的linux服务器上就同时存在一个redis服务端进程和一个redis客户端连接进程:
[root@xxx ~]# ps -ef|grep redisroot 21739 1 0 14:28 ? 00:00:00 redis-server *:6379 # redis服务端进程root 22007 21982 0 14:33 pts/0 00:00:00 redis-cli -h 127.0.0.1 -p 6379 # redis客户端进程root 22143 22121 0 14:35 pts/2 00:00:00 grep --color=auto redis[root@xxx ~]#redis支持许多客户端同时建立连接,接下来我们就可以在业务系统中同时开启多个客户端去访问redis了。
注意:小郭在接下来的Redis系列笔记都基于Redis的版本7.2.1
Redis 支持单机、主从、哨兵、集群多种架构模式,本节来总结一下其中的区别。
部分图片来源于网络
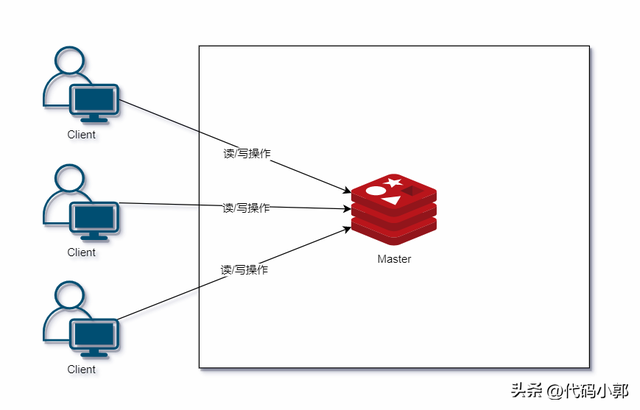
单机模式是最原始的模式,非常简单,就是安装运行一个Redis实例,然后业务项目调用即可。一些非常简单的应用,并非必须保证高可用的情况下完全可以使用该模式。
优点
缺点
单机 Redis 能够承载的 QPS(每秒查询速率)取决于业务操作的复杂性,Lua 脚本复杂性就极高。假如是简单的 key value 查询那性能就会很高,单机支持10W+的QPS。
但是在单机架构下,系统的最大瓶颈就出现在 Redis 单机问题上,此时我们可以通过将架构演化为主从架构解决该问题。
我们可以部署多个 Redis 实例,单机架构模型就演变成了下面这样:
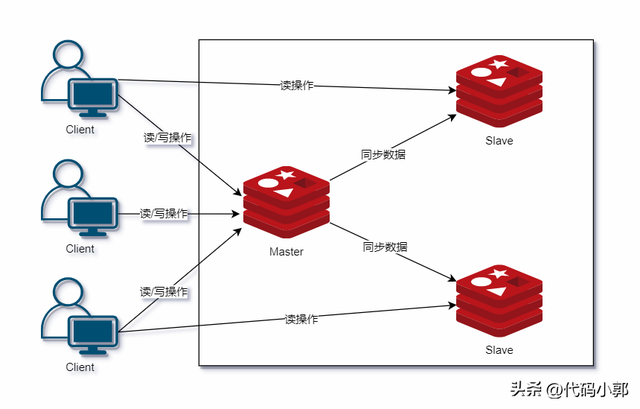
我们把同时接收读/写操作的节点称为Master(主节点), 接收读操作和数据同步的节点称为Slave(从节点)。
只要主从节点之间的网络连接正常,主节点就会将写入自己的数据同步更新给从节点,从而保证主从节点的数据一致性。
主从架构比较适合读高并发场景。
主从架构存在的问题是:当主节点宕机,需要在众多从节点中选一个作为新的主节点,同时需要修改客户端保存的主节点信息并重启客户端,还需要通知所有的从节点去复制新的主节点数据,从而保证服务的高可用性。整个切换过程需要人工干预,而这个过程很明显会造成服务的短暂不可用。
优点
当QPS 增加时,增加 从节点 即可
缺点
一旦主节点挂掉,在人工做主从切换过程中,对外失去了写的能力
每个从节点都有一份完整数据
哨兵架构主要解决了主从架构中存在的高可用性问题,在主从架构的基础上,哨兵架构实现了自动化故障检测和恢复机制,全过程无需人工干预。
Redis 2.8 版本开始,引入哨兵(Sentinel)这个概念
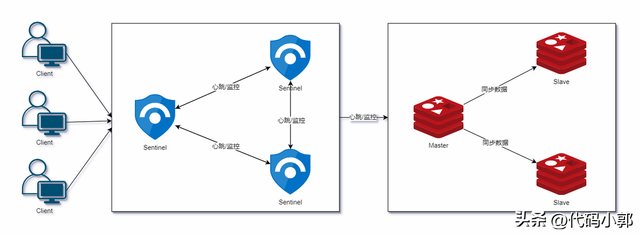
如上图所示,哨兵架构由两部分集群组成,哨兵节点集群和数据节点集群:
该集群中的节点不存储数据,是特殊的redis节点,主要完成监控、提醒、自动故障转移这三大功能。
1)监控(Monitoring):哨兵节点会不断地发送ping消息检测数据节点是否正常;
2)提醒(Notification):当监控到某个数据节点有问题时, 哨兵可以通过 API 向管理员或者其他应用程序发送通知
3)自动故障迁移(Automatic failover):当一个主数据节点不能正常工作时, 哨兵会开始一次自动故障迁移操作,将该主节点下线,选举一个从数据节点升级为主节点(这里也就是将主从架构中的人工干预过程自动化)
该集群中的节点分为主从模式,都存储业务数据,这块其实就是之前的主从架构模式部分
哨兵模式工作原理
优点
缺点
集群架构可以说是Redis的王炸方案了!一经推出,便深得广大开发者喜爱。
Redis 3.0 版本正式推出 Redis Cluster 集群模式,有效地解决了 Redis 分布式方面的需求。Redis Cluster 集群模式具有高可用、可扩展性、分布式、容错等特性。
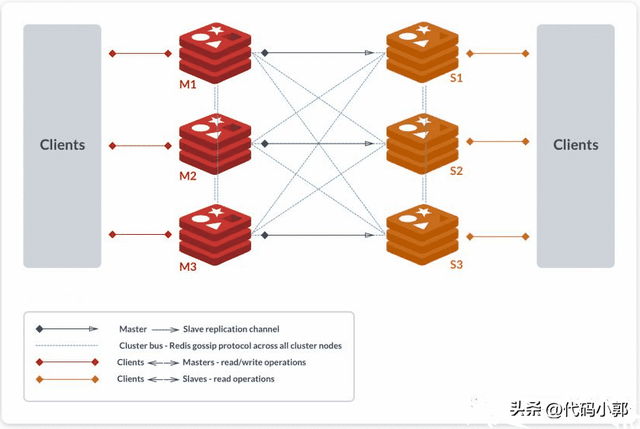
如上图所示,该集群架构中包含 6 个 Redis 节点,3 主 3 从,分别为 M1,M2,M3,S1,S2,S3。除了主从 Redis 节点之间进行数据复制外,所有 Redis 节点之间采用 Gossip 协议进行通信,交换维护节点元数据信息。
客户端读请求分配给 Slave 节点,写请求分配给 Master,数据同步从 Master 到 Slave 节点。读写能力都可以快速进行横向扩展!!!
Redis的集群模式采用的是无中心结构,每个节点都可以保存部分数据和整个集群状态,每个节点都和其他所有节点连接。集群一般由多个节点组成,节点数量至少为 6 个才能保证组成完整高可用的集群,其中三个为主节点,三个为从节点。三个主节点会分配槽,处理客户端的命令请求,而从节点可用在主节点故障后,顶替主节点。
分片
单机、主从、哨兵的架构中每个数据节点都存储了全量的数据,从节点进行数据的复制。然而单个节点存储能力受限于机器资源,是存在上限的,集群模式就是把数据进行分片存储,当一个分片数据达到上限的时候,还可以分成多个分片。
Redis Cluster 采用虚拟哈希槽分区,所有的键根据哈希函数映射到 0 ~ 16383 整数槽内,计算公式:HASH_SLOT = CRC16(key) % 16384。每一个节点负责维护一部分槽以及槽所映射的键值数据。

槽是 Redis Cluster 管理数据的基本单位,集群扩缩容其实就是槽和数据在节点之间的移动。
假如,这里有 3 个节点的集群环境如下:
此时,我们如果要存储数据,按照 Redis Cluster 哈希槽的算法,假设结果是: CRC16(key) % 16384 = 3200。 那么就会把这个 key 的存储分配到 A节点。此时连接 A、B、C 任何一个节点获取 key,都会这样计算,最终是通过 B 节点获取数据。
假如这时我们新增一个节点 D,Redis Cluster 会从各个节点中拿取一部分 Slot 到 D 上,比如会变成这样:
这种特性允许在集群中轻松地添加和删除节点。同样的如果我想删除节点 D,只需要将节点 D 的哈希槽移动到其他节点,当节点是空时,便可完全将它从集群中移除。
主从切换
Redis Cluster 为了保证数据的高可用性,加入了主从模式,一个主节点对应一个或多个从节点,主节点提供数据存取,从节点复制主节点数据备份,当这个主节点挂掉后,就会通过这个主节点的从节点选取一个来充当主节点,从而保证集群的高可用。
回到前面分片的例子中,集群有 A、B、C 三个主节点,如果这 3 个节点都没有对应的从节点,如果 B 挂掉了,则集群将无法继续,因为我们不再有办法为 5501 ~ 11000 范围内的哈希槽提供服务。
所以我们在创建集群的时候,一定要为每个主节点都添加对应的从节点。比如,集群包含主节点 A、B、C,以及从节点 A1、B1、C1,那么即使 B 挂掉系统也可以继续正确工作。
因为 B1 节点属于 B 节点的子节点,所以 Redis 集群将会选择 B1 节点作为新的主节点,集群将会继续正确地提供服务。当 B 重新开启后,它就会变成 B1 的从节点。但是请注意,如果节点 B 和 B1 同时挂掉,Redis Cluster 就无法继续正确地提供服务了。
以上几种架构模式,每种都有各自的优缺点,在实际场景中要根据业务特点去选择合适的模式使用。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号