数据库三大范式详解:概念、应用与优化
发表时间: 2024-06-13 13:48
我们一个小伙伴是今年6月份毕业,今天在和他沟通最近面试的情况,面试官主要问他什么的问题,他说面试官看他是24届的学生,主要问他了学校学习的技术比如操作系统、数据库结构,数据库原理等知识,在数据库原理这里面试官问到了数据库的范式,针对这个问题,小伙伴没有回答的很清楚,所以我就准备写一篇文章来复习一下数据库的范式
设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。但是有些时候一昧的追求范式减少冗余,反而会降低数据读写的效率,这个时候就要反范式,利用空间来换时间。
第一范式(1NF)是数据库设计的基础准则。它的核心要求是,一个符合第一范式的关系模式R应确保其所有字段均由不可分割的最小数据单元组成,即字段中的数据必须为原子值。换句话说,R中的每一列都只包含不可再分的信息,确保了数据的原子性。
第二范式(2NF)是在第一范式的基础上,对数据库表的设计提出了更严格的要求。它要求表中的每个非主属性必须完全函数依赖于整个主键。换句话说,如果一个表采用复合主键,那么该表中的所有非主属性都必须依赖于这个复合主键的所有组成部分,而不仅仅是其中的某一部分。这样的设计避免了部分依赖,确保了数据的一致性和完整性。
第三范式要求非主属性之间没有传递依赖。简单来说,非主属性不应该依赖于其他非主属性。这有助于消除冗余和更新异常。
SELECT * FROM student;+----------------------+--------+-------+| student | course | score |+----------------------+--------+-------+| 竹子,男,185cm | 语文 | 95 || 竹子,男,185cm | 数学 | 100 || 竹子,男,185cm | 英语 | 88 || 熊猫,女,170cm | 语文 | 99 || 熊猫,女,170cm | 数学 | 90 || 熊猫,女,170cm | 英语 | 95 |+----------------------+--------+-------+ +--------------+-------------+----------------+--------+-------+| name | sex | height | course | score |+--------------+-------------+----------------+--------+-------+| 竹子 | 男 | 185cm | 语文 | 95 || 竹子 | 男 | 185cm | 数学 | 100 || 竹子 | 男 | 185cm | 英语 | 88 || 熊猫 | 女 | 170cm | 语文 | 99 || 熊猫 | 女 | 1 70cm | 数学 | 90 || 熊猫 | 女 | 170cm | 英语 | 95 |+--------------+-------------+----------------+--------+-------+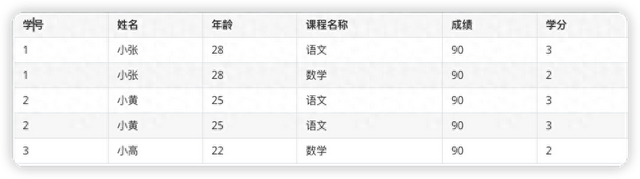
(1)假设学号是表中的唯一主键,那由学号就可以确定姓名和年龄了,但是却不能确定课程名称和成绩。
(2)假设课程名称是表中的唯一主键,那由课程名称就可以确定学分了,但是却不能确定姓名、年龄和成绩。
(3)虽然通过学号和课程名称的联合主键,可以确定除联合主键外的所有的非主键值,但是基于上述两个假设,也不符合第二范式的要求。
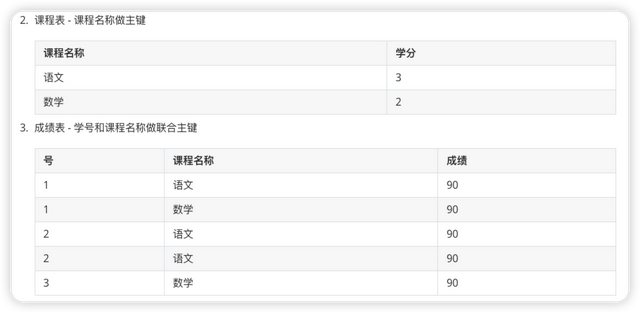
(4)那我们应该如何调整表结构,让它能复合第二范式的要求呢?




声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号