深度解析:Golang性能优化神器PProf
发表时间: 2019-07-17 16:41
Go语言中文网,致力于每日分享编码、开源等知识,欢迎关注我,会有意想不到的收获!

写了几吨代码,实现了几百个接口。功能测试也通过了,终于成功的部署上线了
结果,性能不佳,什么鬼?
想做性能分析?
想要进行性能优化,首先瞩目在 Go 自身提供的工具链来作为分析依据,本文将带你学习、使用 Go 后花园,涉及如下:
pprof 是用于可视化和分析性能分析数据的工具
pprof 以 profile.proto 读取分析样本的集合,并生成报告以可视化并帮助分析数据(支持文本和图形报告)
profile.proto 是一个 Protocol Buffer v3 的描述文件,它描述了一组 callstack 和 symbolization 信息, 作用是表示统计分析的一组采样的调用栈,是很常见的 stacktrace 配置文件格式
我们将编写一个简单且有点问题的例子,用于基本的程序初步分析
(1)demo.go,文件内容:

(2)data/d.go,文件内容:

运行这个文件,你的 HTTP 服务会多出 /debug/pprof 的 endpoint 可用于观察应用程序的情况
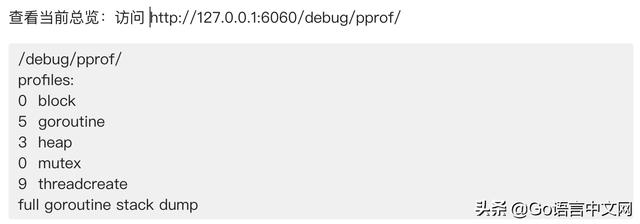
这个页面中有许多子页面,咱们继续深究下去,看看可以得到什么?

执行该命令后,需等待 60 秒(可调整 seconds 的值),pprof 会进行 CPU Profiling。结束后将默认进入 pprof 的交互式命令模式,可以对分析的结果进行查看或导出。具体可执行 pprof help 查看命令说明
(pprof) top10Showing nodes accounting for 25.92s, 97.63% of 26.55s totalDropped 85 nodes (cum <= 0.13s)Showing top 10 nodes out of 21 flat flat% sum% cum cum% 23.28s 87.68% 87.68% 23.29s 87.72% syscall.Syscall 0.77s 2.90% 90.58% 0.77s 2.90% runtime.memmove 0.58s 2.18% 92.77% 0.58s 2.18% runtime.freedefer 0.53s 2.00% 94.76% 1.42s 5.35% runtime.scanobject 0.36s 1.36% 96.12% 0.39s 1.47% runtime.heapBitsForObject 0.35s 1.32% 97.44% 0.45s 1.69% runtime.greyobject 0.02s 0.075% 97.51% 24.96s 94.01% main.main.func1 0.01s 0.038% 97.55% 23.91s 90.06% os.(*File).Write 0.01s 0.038% 97.59% 0.19s 0.72% runtime.mallocgc 0.01s 0.038% 97.63% 23.30s 87.76% syscall.Write
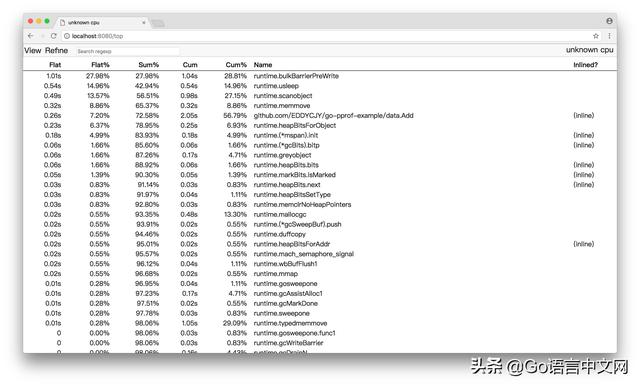
最后一列为函数名称,在大多数的情况下,我们可以通过这五列得出一个应用程序的运行情况,加以优化


这是令人期待的一小节。在这之前,我们需要简单的编写好测试用例来跑一下
(1)新建 data/d_test.go,文件内容:
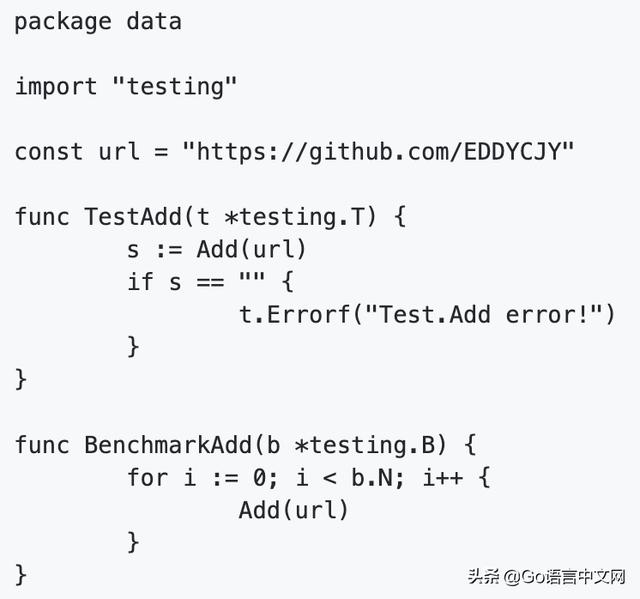
(2)执行测试用例

-memprofile 也可以了解一下
方法一:
$ go tool pprof -http=:8080 cpu.prof
方法二:
$ go tool pprof cpu.prof $ (pprof) web
如果出现 Could not execute dot; may need to install graphviz.,就是提示你要安装 graphviz 了 (请右拐谷歌)
(1)Top
(2)Graph
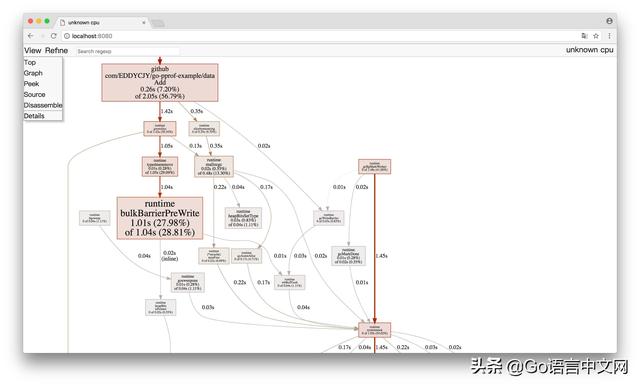
框越大,线越粗代表它占用的时间越大哦
(3)Peek

(4)Source
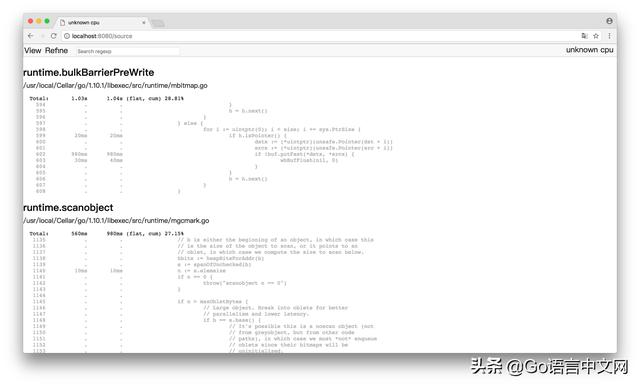
通过 PProf 的可视化界面,我们能够更方便、更直观的看到 Go 应用程序的调用链、使用情况等,并且在 View 菜单栏中,还支持如上多种方式的切换
你想想,在烦恼不知道什么问题的时候,能用这些辅助工具来检测问题,是不是瞬间效率翻倍了呢
另一种可视化数据的方法是火焰图,需手动安装原生 PProf 工具:

(3) 查看 PProf 可视化界面
打开 PProf 的可视化界面时,你会明显发现比官方工具链的 PProf 精致一些,并且多了 Flame Graph(火焰图)
它就是本次的目标之一,它的最大优点是动态的。调用顺序由上到下(A -> B -> C -> D),每一块代表一个函数,越大代表占用 CPU 的时间更长。同时它也支持点击块深入进行分析!
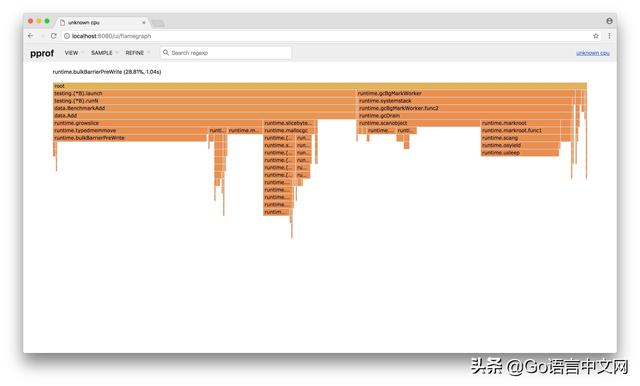
在本章节,粗略地介绍了 Go 的性能利器 PProf。在特定的场景中,PProf 给定位、剖析问题带了极大的帮助
希望本文对你有所帮助,另外建议能够自己实际操作一遍,最好是可以深入琢磨一下,内含大量的用法、知识点
你很优秀的看到了最后,那么有两道简单的思考题,希望拓展你的思路
(1)flat 一定大于 cum 吗,为什么?什么场景下 cum 会比 flat 大?
(2)本章节的 demo 代码,有什么性能问题?怎么解决它?
本文作者:煎鱼,原创授权发布
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号