Redis进阶:深度长文解析(耐心阅读)
发表时间: 2020-12-16 20:11
基础部分在本文就不做详细讲解。
官方回答:
Redis是基于内存操作,CPU不是Redis的性能瓶颈,Redis的性能瓶颈是机器的内存大小、以及网络的带宽,既然单线程容易实现,那就直接使用单线程来实现了
此外:
使用单线程实现,那所有的命令就会排队执行,不需要考虑各种同步问题和加锁带来的性能消耗问题。
既然CPU不是Redis的瓶颈,那么如果不想让服务器的其他CPU闲置,可以考虑起多个Redis进程,因为Redis不是关系型数据库,数据之间也没有约束。这样还能搭建集群,分压分流。
select、poll、eopll是操作系统处理网络上传输过来的数据的不同实现,数据从经过网线流入网卡,网卡中的驱动程序会向CPU发出中断信号,在交互系统中,中断信号的优先级是很高的,CPU立刻去处理这个中断信息,CPU通过终端表找到相应的处理函数:
1、禁用网卡的中断信号,告诉网卡下次有数据过来直接写内存就ok
2、通过驱动程序申请、初始化一块内存,将网卡中的数据写进内存中
3、然后解析处理数据:操作系统先校验数据是否符合os structure、数据往上层传递,Ehthernet校验数据是否符合预期的格式,继续向上层传递到ip层,再往上到tcp/udp层并按照指定的协议去解析
4、应用层想使用这部分数据就有一个拆包+格式校验的过程
内存指的socket文件的接受缓冲区。
作为一个网络服务器同一时刻可能有多个socket和他建立连接与他进行数据的交互,这里的select、poll、epoll说的其实就是在众多的socket中如何快速高效的找到接受缓冲区存在数据的socket文件,然后交给应用层的代码去处理它
Select模型

操作系统为每一个Tcp连接都会相应的创建sock文件,这些sock文件隶属于操作系统的文件列表。
当sock收到了数据,会调用中断程序唤醒进程A,将进程A从所有的Sock的等来队列中移除,加入到内核空间的工作队列中进程A只知道至少有一个sock的接受缓冲区已经有数据了,但是它不知道到底是哪个sock,所以它得通过遍历sock列表的方式找到这个sock。
select的缺点和不足:
下图截自《UNIX环境高级编程》第二版

上图可以看到,使用select系统调用上有三个核心参数:分别是 readfds、writefds、exceptfds指向文件描述符号指针,每个描述符都被放在fd_set中, 也就是说针对read、write、和except分别对应着一个独立的fd_set , (并没有网上流传的数组哦,至少《UNIX环境高级编程》是这样讲的)
下图是截取自《UNIX环境高级编程》的关于fd_set的相关信息,fd_set 是一个bit mask,不是数组。

Poll模型
网上一直流传着这样一句话:poll本质上和select没有区别,都会进行好几次无谓的遍历才能找到到底是那个sock文件的接受缓冲区中接受到了数据。
下图是我截自《UNIX环境高级编程》关于poll部分的内容

书中关于poll的描述,poll模型中定义了一个pollfd,对fd进行了封装,也就是说,poll是使用数组来保存fd的,就是上图中的pollfd数组
网上流传的另一个版本就是说:poll使用链表维护着fd,所以poll没有最大连接数的限制,这一点有待证实,至少《UNIX环境高级编程》中对链表的事只字未提
从书中的描述看,poll确实是用数组来维护fd的,并且还自己封装了个pollfd,维护的是pollfd数组,那为什么poll没有连接数的限制呢?
我是这样理解的:select之所以受到能仅仅能打开1024的限制,是因为操作系统层面上默认就有对单个进程能打开fd的作出的限制,比如32位的OS默认就是1024。那我用poll同也会受到这个1024的限制,但是我能修改这个限制,让他变得比1024大。比如改成10万(只要你的服务器性能够好就行,数组中就能存更多的fd,遍历处理起来就更快)。所以这才会说,poll理论上可以没有限制。
当然我上面说的不一定就对,如果你有更好的解析,欢迎留言。
Epoll模型

Epoll的设计目标就是优化掉Select 和 Poll模型中查找接收到数据的sock文件时进行的无谓的遍历操作。
看上图:在select模型中,需要将进程添加进每一个sock的等待队列,然后阻塞,假如10万TCP连接对应着10万个sock文件,那这个添加+阻塞的操作就得重复10万次
对于epoll来说可以看到,这个添加的过程只进行了一次...见下图

int s = socket(AF_INET, SOCK_STREAM, 0); bind(s, ...)listen(s, ...) int epfd = epoll_create(...);epoll_ctl(epfd, ...); //将所有需要监听的socket添加到epfd中 while(1){ int n = epoll_wait(...) for(接收到数据的socket){ //处理 }当执行系统调用 epoll_create(...) 内核会创建上图中的eventpoll对象,eventpoll对象也隶属于操作系统的文件系统,此外所有的sock都注册在eventpoll中。
进程不再注册在每一个sock的等待队列中,而是注册在eventpoll的等待队列中,此外,接受缓冲区存在数据的sock会被注册进eventpoll的rdlist中。这样当进程再次被唤醒添加到操作系统的工作队列中时,从eventpoll的rdlist中就能确切的获取到哪些sock是需要处理的sock,免去了遍历之苦。
eventpoll中的数据结构
rdlist: 里面存放就绪列的socket,为了满足快速方便删除、添加。它被设计成了双向链表
epoll中也是需要保存受监视的sock,为了方便添加、搜索、检索。被设计成红黑树。因为它的搜索、插入、删除的时间复杂度都是O(logN)
Epoll的连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的机器可以打开20万左右的连接。
参考:《UNIX环境高级编程》
内容包括C/C++,Linux,Nginx,ZeroMQ,MySQL,Redis,MongoDB,ZK,流媒体,P2P,K8S,Docker,TCP/IP,协程,DPDK多个高级知识点。

原子性:一组命令要么同时成功,要么同时失败
但是redis中的每一条单独的命令是有原子性的,但是Redis中的事务不能保证原子性
redis中的事务没有隔离级别的概念,不可能出现脏读、幻读、不可重复读
在redis中,事务的本质是一组命令的集合,一个事务中的所有命令都会有被序列化,在事务执行的过程中:顺序、排他、一次性执行。
Redis事务的过程:
# 开启事务127.0.0.1:16379> MULTIOK# 添加命令127.0.0.1:16379> SET k1 v1QUEUED127.0.0.1:16379> SET k2 v2QUEUED# 执行事务127.0.0.1:16379> EXEC1) OK2) OK127.0.0.1:16379># 开启事务127.0.0.1:16379> MULTIOK# 添加命令127.0.0.1:16379> set k3 v3QUEUED127.0.0.1:16379> SET k4 v4QUEUED# 取消事务127.0.0.1:16379> DISCARDOK# 检查结果,确实没有执行刚刚添加的命令127.0.0.1:16379> keys *1) "k1"2) "k2"127.0.0.1:16379>假设开启时候后,多条命令中有一个命令出现运行时异常有什么影响?
出现异常的命令不会被执行,但是这个异常的命令不会影响它后面的命令执行,因为这个原因我们说redis的事务不支持原子性
# k1的值为字符串127.0.0.1:16379> set k1 "v1"OK# 开启事务127.0.0.1:16379> MULTIOK# 设置事务的值127.0.0.1:16379> set k2 v2QUEUED# 对字符串类型的值+1,会抛出运行时异常127.0.0.1:16379> INCR k1QUEUED# 继续添加两个值127.0.0.1:16379> set k3 v3QUEUED127.0.0.1:16379> set k4 v4QUEUED# 执行事务,看到,运行时异常的命令不会影响后续的命令执行127.0.0.1:16379> exec1) OK2) (error) ERR value is not an integer or out of range3) OK4) OK127.0.0.1:16379>假设开启时候后,多条命令中有一个命令出现编译异常有什么影响?
出现编译型异常,所有的命令都不会被执行
# 开启事务127.0.0.1:16379> MULTIOK# 往命令队列中添加命令127.0.0.1:16379> set k1 v1QUEUED127.0.0.1:16379> set k2 v2QUEUED# 故意添加一个语法错误的命令,导致编译异常127.0.0.1:16379> GETSET k3(error) ERR wrong number of arguments for 'getset' command127.0.0.1:16379> set k4 v4QUEUED# 执行事务127.0.0.1:16379> exec(error) EXECABORT Transaction discarded because of previous errors.# 检查结果,发现所有的命令都没有被执行127.0.0.1:16379> keys *(empty list or set)127.0.0.1:16379>CAP理论
nosql同样也有一套属于自己的CAP
CAP 的理论核心是: 一个分布式的系统,不可能很好的满足一致性,可用性,分区容错性这三个需求,最多同时只能满足两个.因此CAP原理将nosql分成了三大原则:
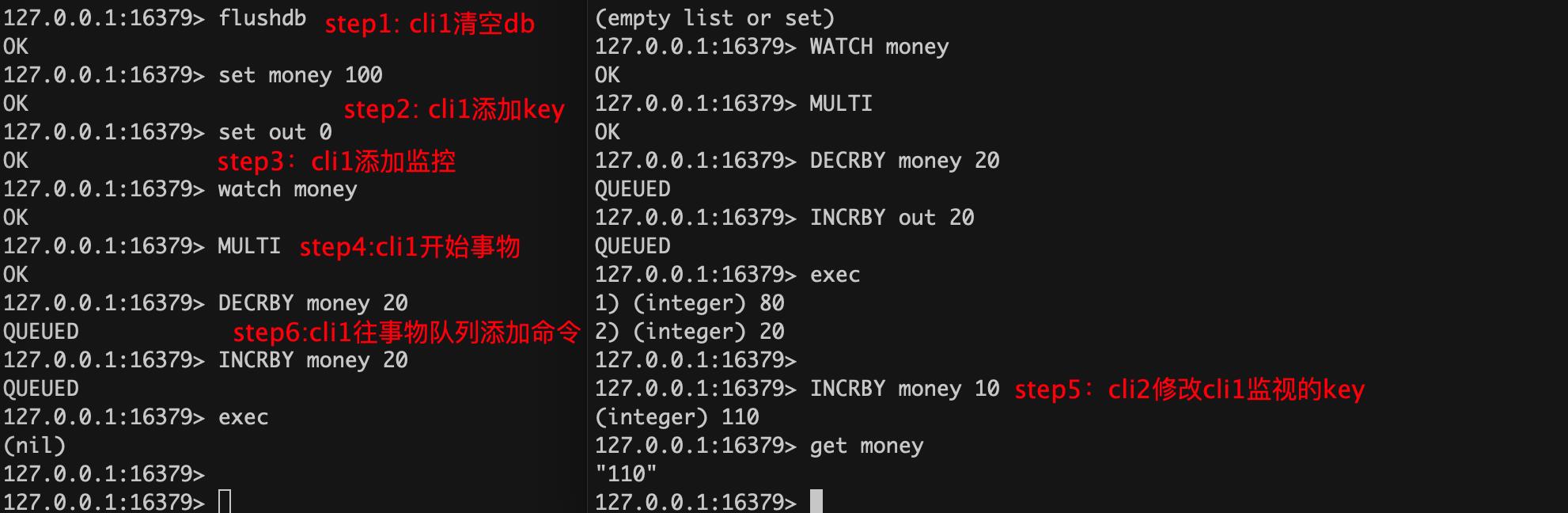
redis可使用watch监视某一个key,然后开启事务操作某一个key,当key没有发生异常变动时,事务正常结束
一旦事务成功执行后,watch就会自动取消掉
127.0.0.1:16379> set money 100OK127.0.0.1:16379> set out 0OK# 监视key127.0.0.1:16379> WATCH moneyOK127.0.0.1:16379> MULTIOK127.0.0.1:16379> DECRBY money 20QUEUED127.0.0.1:16379> INCRBY out 20QUEUED127.0.0.1:16379> exec1) (integer) 802) (integer) 20下面演示一个出现异常的例子:
事务中,添加watch的key被修改后,执行事务返回nil,表示失败
验证了watch机制使用的是乐观锁机制
当遇到上面这种返回nil的情况下,可以像下面这样处理
# 取消监视(解锁)127.0.0.1:16379> UNWATCHOK# 重新监视127.0.0.1:16379> watch moneyOK# 重新开启事务127.0.0.1:16379> MULTIOK127.0.0.1:16379>## 启动redis的方式./redis-server /path/to/redis.conf# 可以像下面这样让在当前配置文件包含引用其他配置文件include /path/to/local.confinclude /path/to/other.conf# 指定哪些客户端可以连接使用redisExamples:bind 192.168.1.100 10.0.0.1 # 指定ipbind 127.0.0.1 ::1 # 仅限于本机可访问# 是否处于受保护的模式,默认开启protected-mode yes# 对外暴露的端口port 16379# TCP的通用配置tcp-backlog 511timeout 0tcp-keepalive 300# 是否以守护进程的方式运行,默认为nodaemonize yes# 如果进程在后台运行,需要指定这个pid文件pidfile /var/run/redis_6379.pid# 日志级别# debug 测试开发节点# verbose (和dubug很像,会产生大量日志)# notice (生产环境使用)# warning (only very important / critical messages are logged)loglevel notice# 日志文件名logfile ""# 数据库的数量,默认16个databases 16# 是否总是显示logoalways-show-logo yes# 设置redis的登陆密码(默认没有密码)# 设置完密码后,使用redis-cli登陆时,使用auth password 认证登陆requirepass foobared# 设置能连接上redis的客户端的最大数量maxclients 10000# 给redis设置最大的内存容量maxmemory <bytes># 内存达到上限后的处理策略# volatile-lru -> 只针对设置了过期时间的key进行LRU移除# allkeys-lru -> 删除LRU算法的Key# volatile-lfu -> 使用具有过期集的密钥在近似的LFU中进行驱逐。# allkeys-lfu -> 使用近似的LFU退出任何密钥。# volatile-random -> 随机删除即将过期的key# allkeys-random -> 随机删除# volatile-ttl -> 删除即将过期的# noeviction -> 永不过期,返回错误maxmemory-policy noeviction这里很突兀的来个fork()系统调用原因是应为:Redis的单线程的,那如果主线程去做这种耗时的IO同步操作时,Redis整体的性能会被拖垮的。
fork()它是一个系统调用,一般用它来创建一个和当前进程一模一样的子进程。当在程序中调用它时,系统为新的进程分配存储、资源,将原程序中的值也复制给他。
fork()函数调用一次会返回两次,在父进程得到的返回值是子进程的pid,在子进程中得到的是0,出错则返回负数。
Redis的实现是通过fork()系统调用创建一个子进程。 由这个子进程去负责执行这些耗时的IO操作,父子进程会共享内存,然后被共享的这块内存不可写,新的数据写入到新的内存文件中
写RDB文件是Redis的一种持久化方式。在指定的时间间隔内将内存中的数据写入到磁盘,RDB文件是一个紧凑的二进制文件,每一个文件都代表了某一个时刻(执行fork的时刻)Redis完整的数据快照,恢复数据时,将快照文件读入内存即可。
RDB持久化的详细过程:
Redis会通过系统调用fork()出一个子进程,父子进程是会共享内存的,父进程和子进程共享的这块内存就是在执行fork操作那个时刻的内存快照。由linux的copy on write机制将父子进程共享的这块内存标记为只读状态。
此时对子进程来说,它的任务就是将这块只读内存中的数据保存成RDB文件。
对父进程来说它是有可能收到写命令的,当父进程尝试往这个加了只读状态的内存地址写入数据时,就会触发保护异常,执行linux的 copy on write,也就是将原来内存对应的数据页复制出来一份后,然后对这个副本进行修改。
这里就会出现一个丢数据的概念:你想,fork出来的子进程将要保存的数据是执行fork系统调用那个时刻的内存中的数据,很快这个内存就被标记为只读了,后续的增量数据没有写入到这个只读内存中,那就算是RDB成功生成了,然后好巧,Redis挂了,这些增量的数据就会丢(所以得使用AOF辅助)
第二种RDB出现数据的丢失的情况是:RDB过程中,直接失败了,文件都没生成,不光是增量数据,原来的数据都丢了。
RDB相关配置如下
# 把下面的注释打开就会禁用掉RDB的持久化策略# save ""# 快照相关,指的是在规定的时间内执行了多少次操作才会持久化到文件save 900 1 # 900秒内1次save 300 10 # 300秒内10次save 60 10000 # 60秒内1万次# 持久化出错了,是否让redis继续工作stop-writes-on-bgsave-error yes# 是否压缩RBD文件(redis会采用LZF压缩算法进行压缩)需要消耗CPU资源rdbcompression yes# 保存rbc文件时是否检验rbd文件格式# 使用CRC64算法进行数据校验,但是这样会增加大约 10%的性能消耗rdbchecksum yes# dump DB的文件名dbfilename dump.rdb# rdb文件的持久化目录(当前目录)dir ./触发保存RDB文件4种情况
如何让redis加载rdb文件?
只需要将rdb文件放在redis的启动目录下,redis其中时会自动加载它
RDB模式的优缺点:
优点:RDB过程中,由子进程代替主进程进行备份的IO操作。保证了主进程仍然提供高性能的服务。适合大规模的数据备份恢复过程。
缺点:
AOF是什么?
Append Only File,他也是Redis的持久化策略。即将所有的写命令都以日志的方式追加记录下来(只追加,不修改),恢复的时候将这个文件中的命令读出来回放。
当我们执行 flushall 命令,清空了redis在内存中的数据,appendonly.aof 同样会记录下这条命令,所以,我们想恢复数据的话,需要去除 appendonly.aof 里面的 flushall 命令
AOF相关的配置
# 默认不开启aofappendonly no# aof文件名appendfilename "appendonly.aof"# redis通过fsync()调用告诉操作系统实际在磁盘上写入数据# aof文件落盘的策略# appendfsync always 每次发生数据变更,立刻记录到磁盘,但是导致redis吞吐量降低# appendfsync everysec 可能会丢失1秒的数据# appendfsync noappendfsync everysec# 当时用bfwriteaof时,fork一个子进程写aof文件,就算aof文件很大,也不会阻塞主进程# 意外情况:但是当主进程、子进程同时写aof文件时,可能会出现由于子进程大量的IO操作阻塞主进程# 当出现这种意外情况时:设置这个参数为no,可以保证数据不会丢失,但是得容忍主进程被阻塞# 当出现这种意外情况时:设置这个参数为yes,主进程不会被阻塞主,但是不保证数据安全性# 综上:如果应用无法忍受延迟:设置为yes。无法忍受数据丢失:设置为nono-appendfsync-on-rewrite no# 在当前aof文件的体积超过上次aof文件的体积的100%时,写新文件auto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mb # 最开始的aof文件体积至少达到60M时才重写# 回放aof文件时,如果最后一条命令存在问题,是否允许忽略aof-load-truncated yes# 是否允许AOF和RDB这两种持久化方式并存aof-use-rdb-preamble yes当aof文件出错怎么办?
redis为我们提供了修复aof文件的工具

[root@instance-lynj0v9k-19 bin]# redis-check-aof --fix appendonly.aofaof模式的优缺点 优点:
缺点:使用aof一直追加写,导致aof的体积远大于RDB文件的体积,恢复数据、修复的速度要比rdb慢很多。
aof的重写
AOF采取的是文件追加的方式,文件的体积越来越大,为了优化这种现象,增加了重写机制,当aof文件的体积到达我们在上面的配置文件上的阕值时,就会触发重写策略,只保留和数据恢复相关的命令
手动触发重写
# redis会fork出一条新的进程# 同样是先复制到一份新的临时文件,最后再rename,遍历每一条语句,记录下有set的语句bgrewriteaof推荐:
Redis的发布订阅模型是一种:消息通信方式,发布者发送到redis到队列中,消息的订阅者可以接收到消息,Redis的客户端可以订阅任意数量的消息
应用场景:关注订阅、消息推送、实时广播、网络聊天室

有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端

测试发布、订阅

概念:和MySQL的主从复制的概念大同小异,分成leader节点和follower节点,主节点承接线上的写流量,从节点承接线上的读流量为主库分流减压,从库的数据从主库中同步过来
主从复制的作用:
redis默认自己就是一个主库,所以我们搭建主从架构的redis,只需要配置Redis从库。

下面搭建这样的一主两从的redis集群
roleipport主库xxx16379从库xxx16378从库xxx16377
如果是在一台服务器上启动多台Redis,需要修改一下配置文件中的端口、pid文件名、日志名、dump.db名
启动三台redis

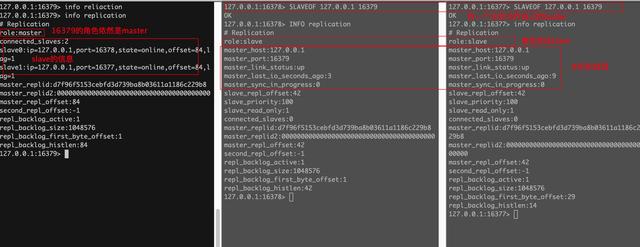
让16378、16377认16379为leader,执行如下命令:
搭建完主从环境之后,查看是否可以从slave中写入数据:
# 结果很明显,不能写入127.0.0.1:16378> set k1 v0(error) READONLY You can't write against a read only replica.MySQL中只要你不设置从库read only,从库也是可以写入的并产生自己的binlog的
测试:从master写入,从slave读出

测试:主机宕机,slave有什么表现
主机宕机后,从库的role依然是slave,并且显示master的状态为down

测试:主机宕机后又重启了,slave有什么表现
主机重启后,slave会重连主机,主机的状态为up,salve可以正常在主库上同步数据

测试:从机宕机,然后有新数据写到了主库,从机再重启问:重启后的从机能不能获取到她宕机期间主库的增量数据?
答案是:获取不到了,因为如果是通过命令行搭建的主从,从库一旦重启,角色会变回master
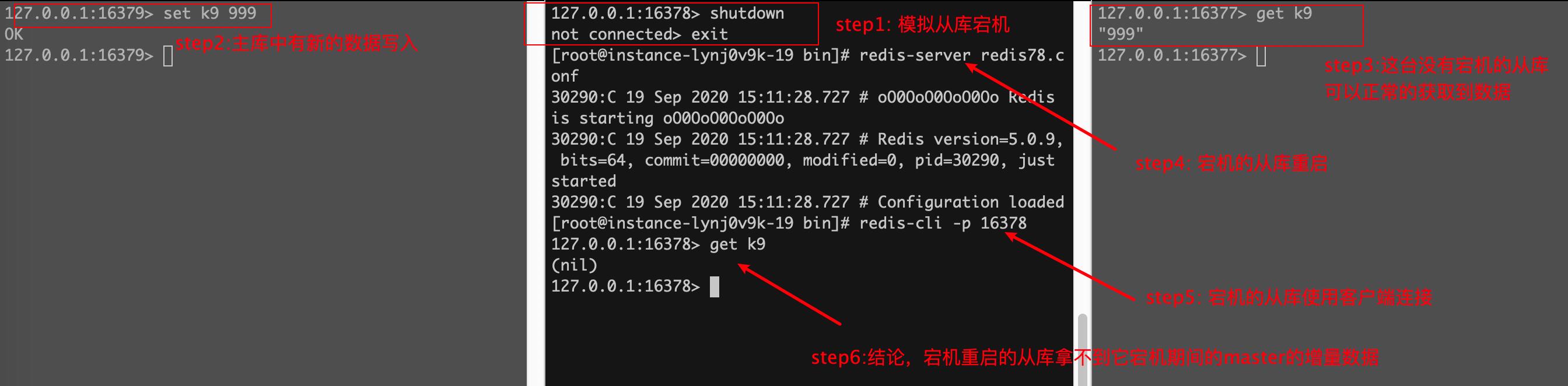
如果这时再把16378变成16379的从库,问能不能获取到增量数据呢?

全量复制和增量复制
从库第一次连接到主库上肯定会进行一次全量复制,即:master会启动后台的存盘进程,同时收集所有用于修改数据集的命令,在后台完成同步,然后将整个数据文件发送给slave,让slave完成一次数据的全量复制
除第一次复制数据之外的主从复制都是增量复制,即master仅仅会将收到的增量写命令发送给slave。

其中的17378既是Master又是Slave
对于16377来说,它确实认了16378为主,但是16378本身又是16379的slave,所以他们之间数据同步的走向是 : 16379 --> 16378 --> 16377 ,对于16378来说,即使有实例认它当master,它依然是不能写

如果主库16379宕机了,16378的状态依然是slave,并且它能察觉master已经挂了,执行 slave no one, 可以将自己提升为master。 在整个过程中,16377不受影响
即使旧master开机重启了,旧的master依然是master,也不能自动的加入到 16377 16378集群中

上面的两种架构模式中,主库挂了之后都需要人为的去选举一个的新的master来承接读流量
redis2.8之之后,提供了哨兵模式:哨兵监控到当主服务器挂了,发起投票选新主库,实现自动的完成选主,承接线上写流量,完成止损
哨兵作为一个独立的进程存在,原理是:哨兵通过发送命令和redis服务器交互,从而监控运行整个集群中的多个Redis实例

Redis的哨兵在Redis 的安装目录下可以找到

为了防护哨兵出现单点故障,所以通常使用多个哨兵对集群进行监控
集群中的每个哨兵彼此相互监控,每个哨兵也都监控着集群中的所有Redis实例

主观下线和客观下线
当一个哨兵发现master不可用时,系统不会马上进行failover,仅仅是这一个哨兵主观意义上认为这个master不可用,这时如果其他的哨兵也来探测master,并且大部分的哨兵都主观认为master确实不可用了,哨兵们就会投票在slave中选出一个当得票最多的slave作为新的master。进行failover操作。
通过发布订阅的模式,哨兵告诉自己监控的那些服务器将master切换为刚刚的票最多的那个实例,这个过程就叫做客观下线。
集群搭建
首先是创建一主二从的redis集群, 此处省略,参照上面架构1部分即可
编写sentinel的配置文件,配置文件的名称、配置项不能写错~
# myredis1 监控的这个redis实例啥# 127.0.0.1 监控的这个redis实例的ip# 16379 监控的这个redis实例的端口# 1 监控的这个redis实例的挂了后,自动投票选主sentinel monitor myredis1 127.0.0.1 16379 1启动sentinel

这样,当master宕机后,哨兵会自动选择一个新的slave作为新主,主库重启后,sentinel会将其作为slave自动加入到现有的redis集群中
缓存穿透
比如这种应用场景:使用redis缓存用户信息,当有新用户注册时先将用户的信息写入Mysql,然后写入Redis。有修改操作时,修改完MySQl中的数据后,同步的也会修改Redis中的数据,而且我们也没有给Redis中的key设置过期时间。(这就意味着:数据库中有指定的KV的信息的话,缓存中也会有。那当用户查询时缓存中没有的话,说明数据库中99.999%也不会有)
这时候有大量的请求去访问MySQL中都没有都数据时,请求先打向了Redis,Redis中肯定也没有存储用户查询的数据,所以大量的请求一下子打到了数据库上,瞬间击垮数据库,这种现象称为缓存穿透。
解决方案:
布隆过滤器:
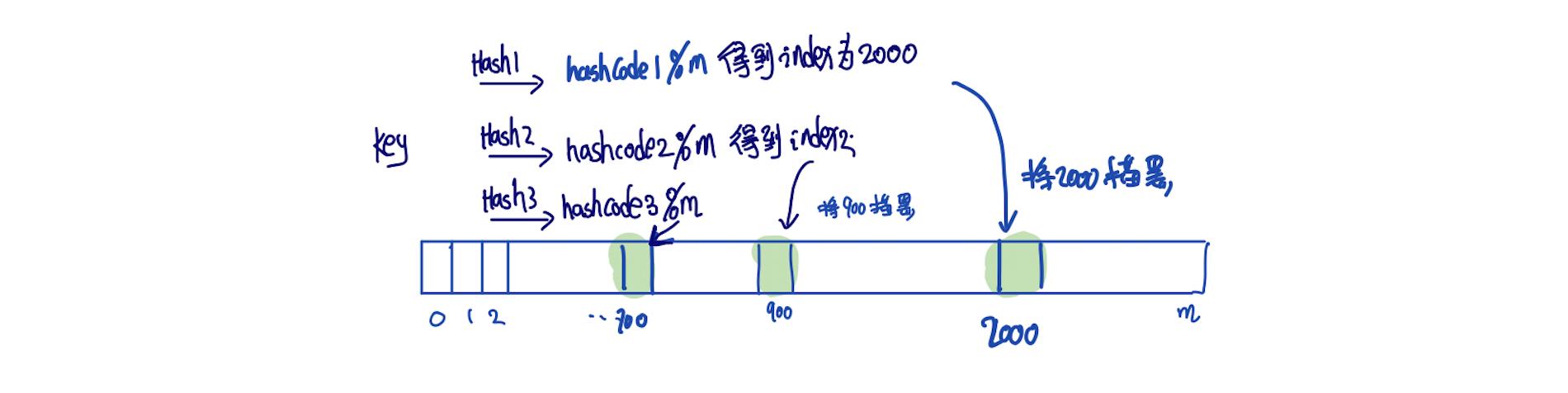
布隆过滤器可以理解成一个bit数组,数组中每一个非0即1
客户端的请求统一先打向布隆过滤器,布隆过滤器放在应用的控制层,布隆过滤器中存在多个hash函数,分别对这个key进行hash得到hashcode,然后将hashcode%数组长度,将算出来的下标标记为1。
key以此经过所有hash,再%size算出的下标对应的值,只要存在一个不为1的数,我们就认为key没在缓存中,直接丢弃用户的这次请求,符合要求把请求打向Redis。从而避免这个请求对底层存储的查询压力。
缓存空对象:
当用户查询的时候,如果发现缓存中没有,就往缓存中放置一个空的对象,然后返回给用户这个控对象,也能避免用户的请求直接打向数据库。
缓存击穿:
缓存击穿指的是Redis中确确实实存在用户查询的key,但是呢用户的访问频率太猛烈了,导致Redis扛不住挂了,导致大量的请求直接打向数据库,或者当某一个key的过期时间到了的瞬间,大量的请求打向数据库导致数据库直接挂了
解决方案:
设置key永不过期
加互斥锁:对这个查询操作添加分布式锁,将原来的大并发直接访问缓存转换成了并发获取分布式锁,只有获取到分布式锁后才能去查询缓存。
雪崩:
比我们启动redis进行一些数据预热,就是将一些数据库中的数据提前导入到redis中,然后给这些数据设置了过期时间。
抢购时间一到系统迎来了一大批并发,但是由于缓存中的数据充足,所以能扛住这波并发。一段时间后,redis中的key集中式的过期了,这时再来一大批并发请求可能就直接将redis打垮。redis挂了后,大量的请求直接打向MySQL,导致MySQL跟着雪崩式的垮掉
解决方法:
异地多活,添加redis的实例的数量
加分布式锁
在应用和缓存之间添加消息中间件做缓冲
合理为不同的key设置不同的过期时间,放置缓存中的key出现集中式过期的情况
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号