如何通过Bencher工具将SQLite页面加载速度提升1200倍?
发表时间: 2024-04-19 08:29
在实例学习中,系统性能调优的案例是最值得学习的。之前虫虫给大家介绍过语言方面性能的调优、算法方面调优的,今天给大家介绍一个有关数据库查询方面性能优化的实例。
这是一个开源连续基准测试工具Bencher遇到的真实场景,我们一起来学习一下吧。
Bencher接到用户反馈,其Bencher Perf页面需要长时间才能加载出来。这对一个做基准测试业务的工具来说是不可接受的。为了复现问题,其工程师选择通过Rustls Perf页面来作为测试,其测试范围最广,设置也最齐全,包括112个基准测试和最完整整齐的连续基准测试设置。
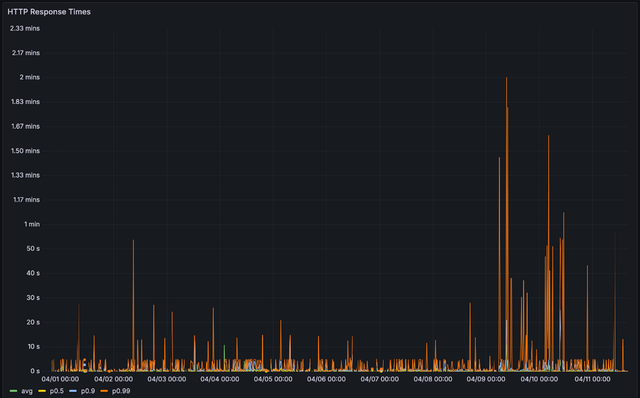
该项目Perf页面过去加载大约需要5秒。现在测试中为38.8秒,确实是延迟的逆天了。
Bencher Perf API是目前对性能要求最高的端点之一。面对基准要求越来越严苛,尤其是需要连续基准测试对比的项目,现有的基准测试工具工具无法处理所需的高维度。所谓的“高维度”是指可以跨多个维度跟踪一段时间内的表现:分支、 测试平台、基准和措施。这种在五个不同维度上进行切片和切块的能力导致了一个非常复杂的模型。由于这种固有的复杂性和数据的性质, Bencher业务需要使用时间序列数据库,并选择使用简单方便的SQLite。
随着时间的推移Bencher Perf API的需求越来越多。最初,必须选择要手动渲染整个页面,这让给用户获得有用的绘图带来了很大的障碍。为了解决这个问题,Perf页面添加了最新报告的列表,默认情况下,选择并绘制最新的报告。这样如果最近的报告中有112个基准,那么所有112个基准都会被绘制出来。由于能够跟踪和可视化阈值边界,该模型也变得更加复杂。
考虑到这一点,Bencher进行了做了一些与性能相关的改进。由于Perf Plot需要最新的报告才能开始绘制,为此改进中重构了报告API,以便通过对数据库的单次调用来获取报告的结果数据,而不是进行迭代。默认报告查询的时间窗口设置为四个星期,而不是无限制。另外极大地限制了所有数据库句柄的范围,减少了锁争用。为了帮助与用户沟通添加了状态栏微调器“性能图” 和 “维度”选项卡 。
也曾尝试使用复合查询将所有Perf结果放入单个查询中,但失败了,而不是使用四重嵌套for循环。导致达到了Rust类型系统递归限制, 反复溢出堆栈, 经历疯狂的(远超过38秒)编译时间,最后导致SQLite复合select语句中的最大术语数超出导致问题。
分许出来,问题来源,需要对其进行挖掘,然后进行调优。
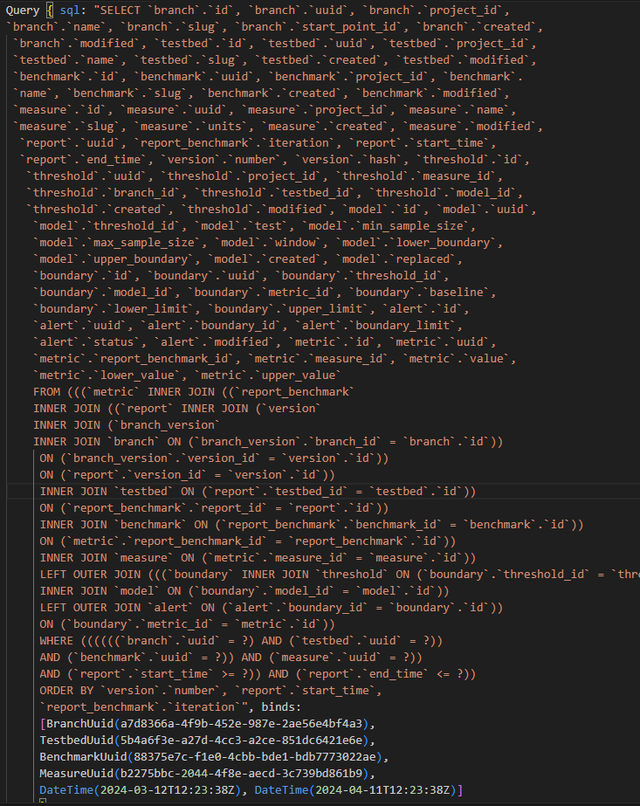
第一个障碍是从Rust代码中获取SQL查询。由于Bencher使用Diesel作为访问数据库的对象关系模型(ORM)。Diesel创建参数化查询。它将SQL查询及其绑定参数分别发送到数据库。也就是说,替换是由数据库完成的。因此,Diesel无法向用户提供完整的查询。
解决这个问题最好的方法是使用输出参数化查询的diesel::debug_query函数:
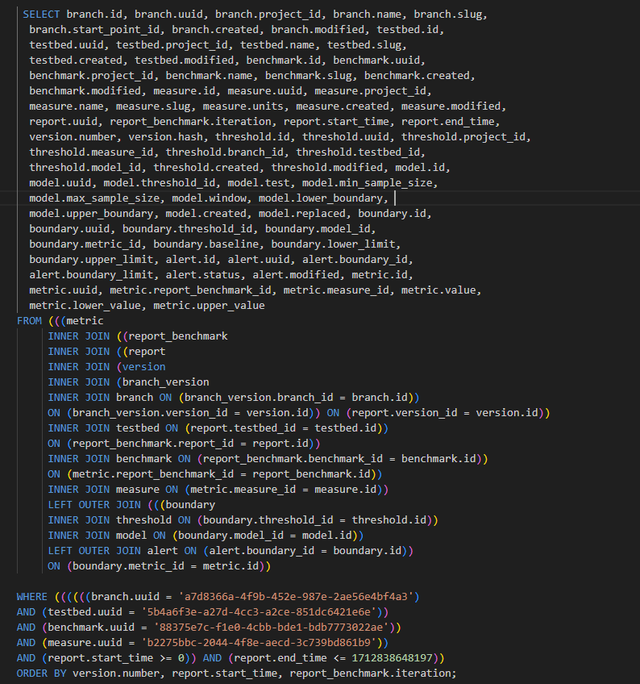
手动清理并将查询参数化为有效的SQL:
关于SQLite数据的性能调优,可以使用其查询规划器(Query Planner)。准确地解释SQLite如何执行SQL查询,它会告诉哪些索引有用以及需要注意哪些操作,例如全表扫描。
为了查看查询规划器如何执行Perf查询,需要在工具带中添加一个新工具:EXPLAIN QUERY PLAN可以为SQL查询添加前缀EXPLAIN QUERY PLAN或运行.eqp on查询之前的点命令。

接种有很多过程,但是影响性能的,可能是一下三点:
SQLite动态创建一个物化视图来扫描整个boundary表;
SQLite扫描整个metric表;
SQLite创建两个动态索引;
而metric和boundary是系统中最大的两个表,字段多、数据量最大,这可能是问题所在。
SQLite有一个实验性质的“专家”模式,可以通过.expert on命令启动。它会自动对查询进行给出建议,对上述查询建议:
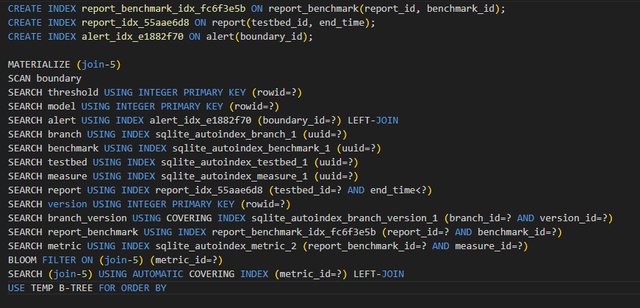
三个问题中,除了动态物化视图,其他两个问题已经被有优化解决了。
Metric与其对应的Boundary之间存在1对0/1 的关系。也就是说,一个指标可以与零个或一个边界相关,而一个边界只能与一个指标相关。所以,可以考虑扩大 metric表包括所有的boundary数据与每个boundary相关字段可为空。或者可以创建一个单独的boundary表与一个UNIQUE外键到metric表。 先然使用,后一个方案更合适,修改、重建metric和boundary表:
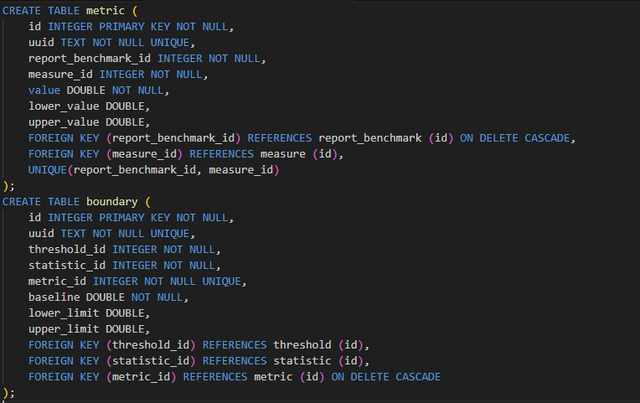
然后简单地添加一个索引boundary(metric_id),但是问题没有得到改善。这个可能是Perf查询源自etric表关系是 0/1 或者换句话说,必须扫描可为null 的关系(O(n))并且无法被搜索(O(log(n)))。
为了解决这个问题,通过手动创建一个物化视图来扁平化metric和boundary关系使SQLite不必创建动态物化视图。其SQL语句:
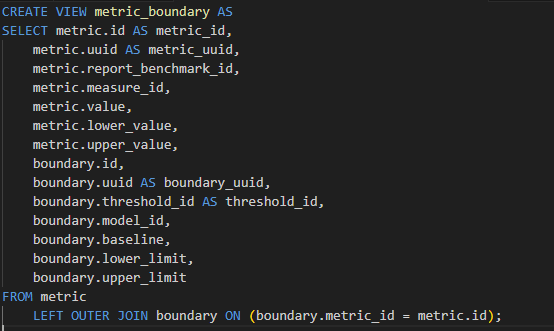
通过这个解决方案,采取用用空间来换取运行时性能的办法。实际上,尽管此视图针对的是数据库中两个最大的表,空间仅增加了不过4%而已,最重要的是,它让以在源代码中鱼与熊掌兼得。使用Diesel 创建物化视图非常简单。只需使用Diesel在生成正常模式时使用的完全相同的宏。
添加三个新索引和一个物化视图后,查询计划器:
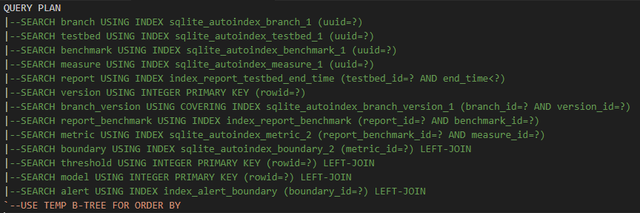
完美,所有都解决了,所有查询均走了索引。
更新部署后系统页面实际加载结果也更加完美,从两分钟到只需要
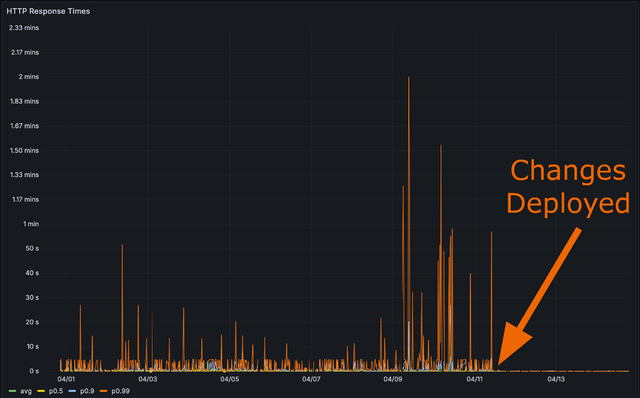
该实例中,通过问题排查,复现、查询调试、使用专家模式优化、改变表结构,到最后手动创建无话视图用空间换性能。最后将性能完美提高了1200倍,这个过程思路明确,一气呵成,可以作为此类问题解决的一个完美模板。
当然最主要该案例涉及的项目是专业做性能的持续基准测试,除了学习排障思路和方法外,这个开源工具Bencher也值得大家引入和使用,对持续跟踪项目性能问题大有裨益。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号