系统与硬件故障导致的Redis慢查询深度解析
发表时间: 2024-06-05 15:47
年后回来各种事情比较多,好久没有更新公众号了,也有人催更了,我准备把最近碰到的三次奇怪的Redis慢查询(很小的命令,耗时超出预期)集中整理下。
声明:本文涉级的硬件知识和系统知识,我都是临时学的,如有错误欢迎板砖我们和业务排查问题时候发现:
实例角色耗时(微秒)命令value大小10.xx.xx.xx:yymaster41,432get rta_12345xxxx15字节10.xx.xx.xx:yymaster41,613get rta_6789yyyyy15字节
快速定位为服务器问题,因为同机器的其他Redis集群均出现上述情况。
机器问题几板斧:
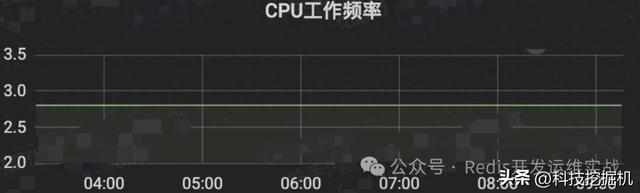
因为之前定位过类似问题,单路供电能会导致CPU降频,但是查询监控未发现有降频:
img
中间又辗转怀疑了很多点,最后排查同学还是怀疑和电源故障有关

img
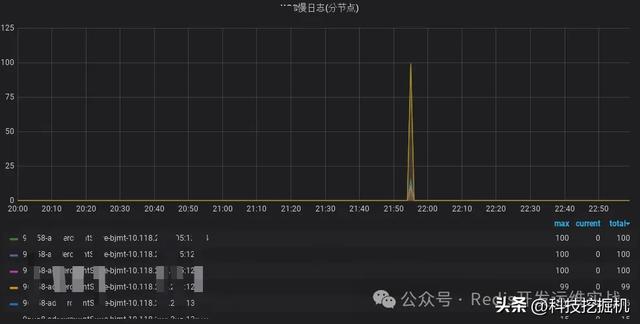
某周末晚上,某业务在21:55可用性突然报警,从100%->98%,经排查该分钟该集群的全部实例出现慢日志(均为小命令),并且集中在一台机器。
实例角色耗时(微秒)命令value大小10.xx.xx.xx:yymaster20,421incr small_key110字节10.xx.xx.xx:yymaster21,324get small_key210字节
img
快速定位为服务器问题,因为同机器的其他Redis集群均出现上述情况。
机器问题几板斧:
May 18 21:55:04 机器名 kernel: 异常处理[Hardware Error]: Hardware error from APEI Generic Hardware Error Source: 4May 18 21:55:04 机器名 kernel: 异常处理[Hardware Error]: It has been corrected by h/w and requires no further actionMay 18 21:55:04 机器名 kernel: 异常处理[Hardware Error]: event severity: correctedMay 18 21:55:04 机器名 kernel: 异常处理[Hardware Error]: Error 0, type: correctedMay 18 21:55:04 机器名 kernel: 异常处理[Hardware Error]: fru_text: A2May 18 21:55:04 机器名 kernel: 异常处理[Hardware Error]: section_type: memory errorMay 18 21:55:04 机器名 kernel: 异常处理[Hardware Error]: error_status: 0x0000000000000400May 18 21:55:04 机器名 kernel: 异常处理[Hardware Error]: physical_address: 0x00000009f7466ac0May 18 21:55:04 机器名 kernel: 异常处理[Hardware Error]: node: 0 card: 1 module: 0 rank: 0 bank: 0 row: 18297 column: 936May 18 21:55:04 机器名 kernel: 异常处理[Hardware Error]: error_type: 2, single-bit ECCMay 18 21:55:04 机器名 kernel: core: [Hardware Error]: Machine check events loggedMay 18 21:55:04 机器名 kernel: EDAC MC0: 0 CE memory read error on CPU_SrcID#0_Ha#0_Chan#1_DIMM#0 (channel:1 slot:0 page:0x9f7466 offset:0xac0 grain:32 syndrome:0x0 - area:DRAM err_code:0000:009f socket:0 ha:0 channel_mask:2 rank:0)May 18 21:55:04 机器名 kernel: EDAC MC0: 0 CE memory read error on CPU_SrcID#0_Ha#0_Chan#1_DIMM#0 (channel:1 slot:0 page:0x9f7467 offset:0x5c0 grain:32 syndrome:0x0 - area:DRAM err_code:0000:009f socket:0 ha:0 channel_mask:2 rank:0)May 18 21:55:04 机器名 kernel: EDAC MC0: 0 CE memory read error on CPU_SrcID#0_Ha#0_Chan#1_DIMM#0 (channel:1 slot:0 page:0x9f7441 offset:0xa40 grain:32 syndrome:0x0 - area:DRAM err_code:0000:009f socket:0 ha:0 channel_mask:2 rank:0)May 18 21:55:04 机器名 kernel: EDAC MC0: 0 CE memory read error on CPU_SrcID#0_Ha#0_Chan#1_DIMM#0 (channel:1 slot:0 page:0x9f7447 offset:0x140 grain:32 syndrome:0x0 - area:DRAM err_code:0000:009f socket:0 ha:0 channel_mask:2 rank:0)May 18 21:55:05 机器名 kernel: EDAC MC0: 0 CE memory read error on CPU_SrcID#0_Ha#0_Chan#1_DIMM#0 (channel:1 slot:0 page:0x9f7443 offset:0x640 grain:32 syndrome:0x0 - area:DRAM err_code:0000:009f socket:0 ha:0 channel_mask:2 rank:0)May 18 21:55:05 机器名 kernel: EDAC MC0: 0 CE memory read error on CPU_SrcID#0_Ha#0_Chan#1_DIMM#0 (channel:1 slot:0 page:0x9f7444 offset:0x240 grain:32 syndrome:0x0 - area:DRAM err_code:0000:009f socket:0 ha:0 channel_mask:2 rank:0)May 18 21:55:06 机器名 kernel: EDAC MC0: 0 CE memory read error on CPU_SrcID#0_Ha#0_Chan#1_DIMM#0 (channel:1 slot:0 page:0x9f74e5 offset:0x3c0 grain:32 syndrome:0x0 - area:DRAM err_code:0000:009f socket:0 ha:0 channel_mask:2 rank:0)May 18 21:55:06 机器名 kernel: EDAC MC0: 0 CE memory read error on CPU_SrcID#0_Ha#0_Chan#1_DIMM#0 (channel:1 slot:0 page:0x9f7461 offset:0xac0 grain:32 syndrome:0x0 - area:DRAM err_code:0000:009f socket:0 ha:0 channel_mask:2 rank:0)May 18 21:55:06 机器名 kernel: EDAC MC0: 0 CE memory read error on CPU_SrcID#0_Ha#0_Chan#1_DIMM#0 (channel:1 slot:0 page:0x9f7460 offset:0x3c0 grain:32 syndrome:0x0 - area:DRAM err_code:0000:009f socket:0 ha:0 channel_mask:2 rank:0)May 18 21:55:06 机器名 kernel: EDAC MC0: 0 CE memory read error on CPU_SrcID#0_Ha#0_Chan#1_DIMM#0 (channel:1 slot:0 page:0x9f7464 offset:0x2c0 grain:32 syndrome:0x0 - area:DRAM err_code:0000:009f socket:0 ha:0 channel_mask:2 rank:0)May 18 21:55:07 机器名 kernel: EDAC MC0: 0 CE memory read error on CPU_SrcID#0_Ha#0_Chan#1_DIMM#0 (channel:1 slot:0 page:0x9f7440 offset:0x340 grain:32 syndrome:0x0 - area:DRAM err_code:0000:009f socket:0 ha:0 channel_mask:2 rank:0)MCE全称Machine check exception,英文解释如下(论文:https://www.halobates.de/mce.pdf),简单说有硬件错误,需要中断当前的进程,调用一个专用的硬件异常处理handler进行处理。
A machine check exception happens when there is an error that the hardware cannot correct. It will cause the CPU to interrupt the current program and call a special exception handler.With a silent machine check the hardware was abl通过修改/sys/devices/system/machinecheck/machinecheck0/check_interval 的值,可以调整错误修复的初始和最大轮询间隔。
从可用性角度看,似乎最应该关注的是2,3类错误,但实际上1类错误更具有欺骗性,在分布式系统中,确定性要好过不确定性。
这里重点是SMI中断(SMI中断使CPU进入SMM),它是Linux无法感知的,如果BIOS/firmware 处理错误耗费了太长时间,可能导致延迟抖动,没有统一的方法从Linux测度量。而其它中断是Linux处理的,其耗时Linux总是有办法度量
May 18 21:55:04 机器名 kernel: EDAC MC0: 0 CE memory read error on CPU_SrcID#0_Ha#0_Chan#1_DIMM#0 (channel:1 slot:0 page:0x9f7466 offset:0xac0 grain:32 syndrome:0x0 - area:DRAM err_code:0000:009f socket:0 ha:0 channel_mask:2 rank:0) Machine check events loggedMay 18 21:55:04 机器名 kernel: 异常处理[Hardware Error]: fru_text: A2May 18 21:55:04 机器名 kernel: 异常处理[Hardware Error]: section_type: memory errorMay 18 21:55:04 机器名 kernel: 异常处理[Hardware Error]: error_status: 0x0000000000000400May 18 21:55:04 机器名 kernel: 异常处理[Hardware Error]: physical_address: 0x00000009f7466ac0May 18 21:55:04 机器名 kernel: 异常处理[Hardware Error]: node: 0 card: 1 module: 0 rank: 0 bank: 0 row: 18297 column: 936May 18 21:55:04 机器名 kernel: 异常处理[Hardware Error]: error_type: 2, single-bit ECC系统发生硬件错误会导致机器进入 MCE中断,可能会将大部份内核时间用于处理 MCE中断(例如本例子CE Memory)
这个就是一个凑数的,很早之前遇到的,在《Redis开发与运维》一书也提过,原文如下:

img
Uncorrected hardware memory error ,导致Redis直接core
May 27 15:48:58 机器名 kernel: core: Uncorrected hardware memory error in user-access at 1a1f914a80May 27 15:48:58 机器名 kernel: core: [Hardware Error]: Machine check events loggedMay 27 15:48:58 机器名 mcelog: Hardware event. This is not a software error.May 27 15:48:58 机器名 mcelog: MCE 0May 27 15:48:58 机器名 mcelog: CPU 15 BANK 1 TSC e7a1f64e03e47aMay 27 15:48:58 机器名 mcelog: RIP 33:465af1May 27 15:48:58 机器名 mcelog: MISC 86 ADDR 1a1f914a80May 27 15:48:58 机器名 mcelog: TIME 1716796138 Mon May 27 15:48:58 2024May 27 15:48:58 机器名 mcelog: MCG status:RIPV EIPV MCIP LMCEMay 27 15:48:58 机器名 mcelog: MCi status:May 27 15:48:58 机器名 mcelog: Uncorrected errorMay 27 15:48:58 机器名 mcelog: Error enabledMay 27 15:48:58 机器名 mcelog: MCi_MISC register validMay 27 15:48:58 机器名 mcelog: MCi_ADDR register validMay 27 15:48:58 机器名 mcelog: SRARMay 27 15:48:58 机器名 mcelog: MCA: Data CACHE Level-0 Data-Read ErrorMay 27 15:48:58 机器名 mcelog: STATUS bd80000000100134 MCGSTATUS fMay 27 15:48:58 机器名 mcelog: MCGCAP f000c14 APICID 1e SOCKETID 0May 27 15:48:58 机器名 mcelog: PPIN 2c6b0193f6fb1bb7May 27 15:48:58 机器名 mcelog: CPUID Vendor Intel Family 6 Model 85May 27 15:48:58 机器名 mcelog: warning: 8 bytes ignored in each recordMay 27 15:48:58 机器名 mcelog: consider an updateMay 27 15:48:58 机器名 kernel: Memory failure: 0x1a1f914: Killing redis-server:44454 due to hardware memory corruptionMay 27 15:48:58 机器名 kernel: Memory failure: 0x1a1f914: recovery action for dirty LRU page: RecoveredMay 27 15:48:58 机器名 kernel: MCE: Killing redis-server:44454 due to hardware memory corruption fault at 7f392cb4a9c0Jun 2 20:13:29 机器名 kernel: CPU20: Core temperature above threshold, cpu clock throttled (total events = 176720)Jun 2 20:13:30 机器名 kernel: CPU48: Core temperature above threshold, cpu clock throttled (total events = 176498)Jun 2 20:17:30 机器名 kernel: CPU50: Core temperature above threshold, cpu clock throttled (total events = 177150)Jun 2 20:17:30 机器名 kernel: CPU22: Core temperature above threshold, cpu clock throttled (total events = 177136)Jun 2 20:20:57 机器名 kernel: CPU44: Core temperature above threshold, cpu clock throttled (total events = 269866)Jun 2 20:20:58 机器名 kernel: CPU16: Core temperature above threshold, cpu clock throttled (total events = 269730)Jun 2 20:37:29 机器名 kernel: CPU54: Core temperature above threshold, cpu clock throttled (total events = 33630)Jun 2 20:37:30 机器名 kernel: CPU26: Core temperature above threshold, cpu clock throttled (total events = 33635)Jun 2 20:45:29 机器名 kernel: CPU17: Core temperature above threshold, cpu clock throttled (total events = 214231)Jun 2 20:45:30 机器名 kernel: CPU45: Core temperature above threshold, cpu clock throttled (total events = 214140)关于CPU功耗管理,有以下几种模式:
performance 运行于最大频率 powersave 运行于最小频率 userspace 运行于用户指定的频率 ondemand 按需快速动态调整CPU频率, 一有cpu计算量的任务,就会立即达到最 大频率运行,空闲时间增加就降低频率 conservative 按需快速动态调整CPU频率, 比 ondemand 的调整更保守 schedutil 基于调度程序调整 CPU 频率查看当前支持模式:
$ cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_available_governorsperformance powersave查看当前使用模式:
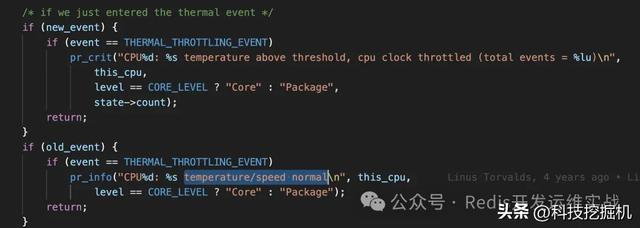
$ cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governorperformance内核代码:cpu温度超过阈值会打印系统日志,但是是否降频还和 /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor模式有关。
img
本文粗浅分析了在Redis使用过程中遇到的诡异慢查询问题,其中包含了硬件故障相关,系统参数错误优化等问题,当然实际在使用和运维过程中可能还有其他诡异情况,需要具体问题具体分析。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号