深度解析:云原生混部系统 Koordinator 的架构设计
发表时间: 2022-07-21 15:21
混部的概念可以从两个角度来理解,从节点维度来看,混部就是将多个容器部署在同一个节点上,这些容器内的应用既包括在线类型,也包括离线类型;从集群维度来看,混部是将多种应用在一个集群内部署,通过预测分析应用特性,实现业务在资源使用上的错峰填谷,以达到提升集群资源利用率的效果。
基于以上的理解,我们就可以明确混部需要解决的目标问题以及技术方案。本质上,我们实施混部的初衷是源自对数据中心资源利用效率的不懈追求。埃森哲报告显示,2011 年公有云数据中心的机器利用率平均不到 10%,意味着企业的资源成本极高,而另一方面随着大数据技术的发展迅速,计算作业对资源的需求越来越大。事实上,大数据通过云原生方式上云已成为了必然趋势,据 Pepperdata 在 2021 年 12 月的调查报告,相当数量的企业大数据平台已经开始向云原生技术迁移。超过 77% 的受访者反馈预计到 2021 年底,其 50% 的大数据应用将迁移到 Kubernetes 平台。于是,选择批处理类型任务与在线服务类型应用混合部署,就顺理成章的成为了业界通用的混部方案选型。公开数据显示,通过混部,相关技术领先企业的资源利用率得到了大幅提升。
面对混部技术,在具体关注的问题上,不同角色的管理人员会有各自的侧重点。
对于集群资源的管理员来说,他们期望可以简化对集群资源的管理,实现对各类应用的资源容量,分配量,使用量的清晰洞察,提升集群资源利用率,以达到降低 IT 成本的目的。
对于在线类型应用的管理员来说,他们则更关注容器混合部署时的互相干扰的,因为混部会更容易产生资源竞争,应用响应时间会出现长尾(tail latency),导致应用服务质量下降。
而离线类型应用的管理员更期望混部系统可以提供分级可靠的资源超卖,满足不同作业类型的差异化资源质量需求。
针对以上问题,Koordinator 提供了以下机制,可以充分满足不同角色对混部系统的技术需求:
下图展示了 Koordinator 系统的整体架构和各组件的角色分工,其中绿色部分描述了 K8s 原生系统的各个组件,蓝色部分是 Koordinator 在此基础上的扩展实现。从整个系统架构来看,我们可以将 Koordinator 分为中心管控和单机资源管理两个维度。在中心侧,Koordiantor 在调度器内部和外部分别都做了相应的扩展能力增强;在单机侧,Koordinator 提供了 Koordlet 和 Koord Runtime Proxy 两个组件,负责单机资源的精细化管理和 QoS 保障能力。
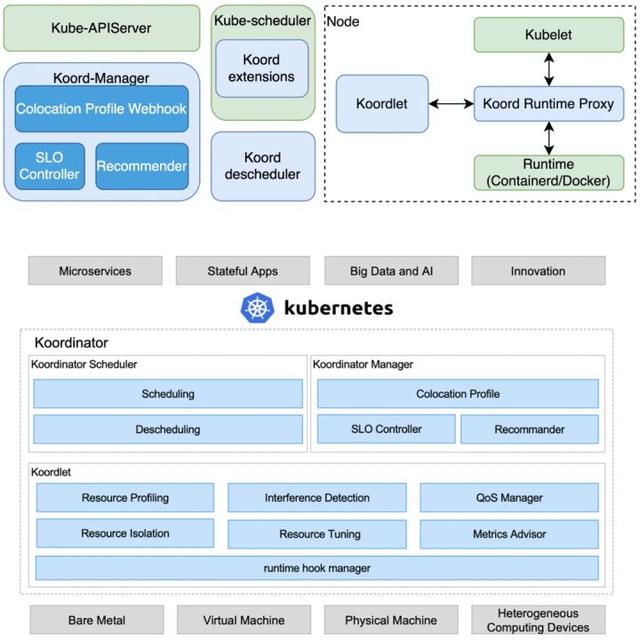
Koordinator 各组件的详细功能如下
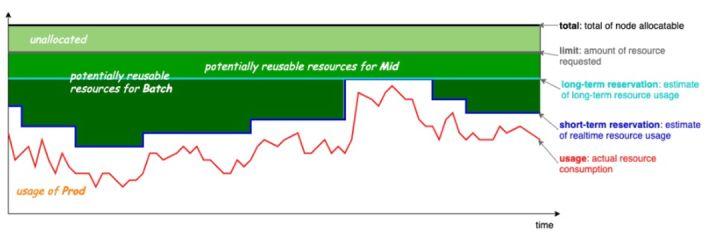
在 Koordinator 的设计模型中,一个核心的设计概念就是优先级(Priority),Koordinator 定义了四个等级,分别是 Product、Mid、Batch、Free ,Pod 需要指定申请的资源优先级,调度器会基于各资源优先级总量和分配量做调度。各优先级的资源总量会受高优先级资源的 request 和 usage 影响,例如已申请但未使用的 Product 资源会以 Batch 优先级再次分配。节点各资源优先级的具体容量,Koordinator 会以标准的 extend-resource 形式更新在 Node 信息中。
下图展示了一个节点各资源优先级的容量情况,其中黑色的直线 total 代表了节点的物理资源总量,红色折线代表了高优先级 Product 的真实使用量,蓝色折线到黑色直线之间反映了 Batch 优先级的资源超卖变化情况,可以看到当 Product 优先级处于资源消耗的低谷时,Batch 优先级可以获得更多的超卖资源。事实上,资源优先级策略的激进或保守,决定了集群资源的超卖容量,这点我们也可以从图中绿色直线对应的 Mid 资源优先级超卖情况分析看出。
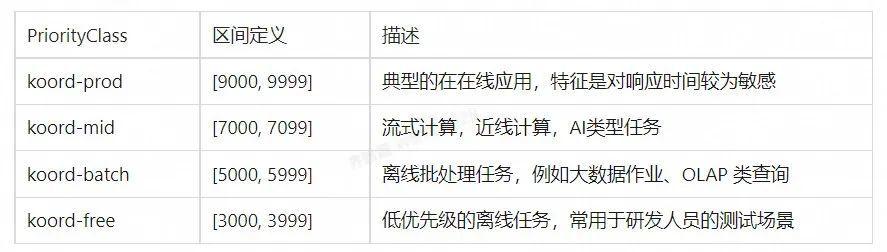
如下表所示,Koordinator 以 K8s 标准的 PriorityClass 形式对各资源优先级进行了定义,代表 Pod 申请资源的优先级。在多优先级资源超卖情况下,当单机资源紧张时,低优先级 Pod 会被压制或驱逐。此外,Koordinator 还提供了 Pod 级别的子优先级(sub-priority),用于调度器层面的精细化控制(排队,抢占等)。
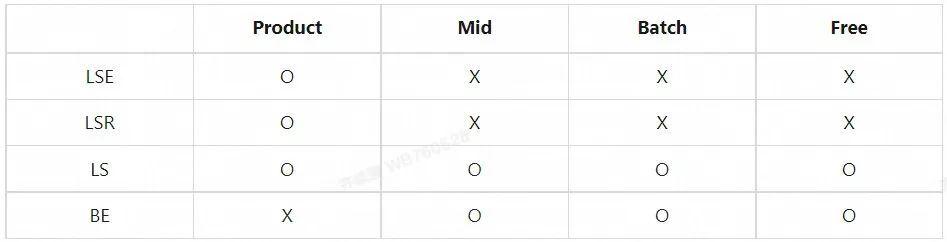
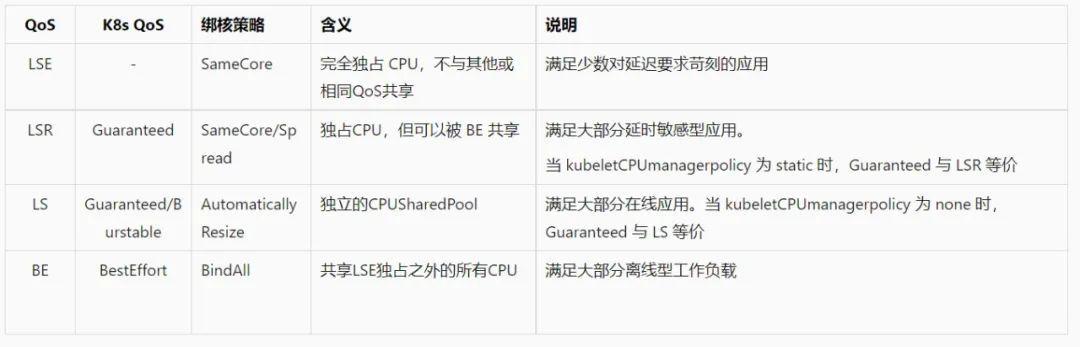
Koordinator 的设计中另一个核心的概念是服务质量(Quality of Service),Koordinator 将 QoS 模型在 Pod Annotation 级别进行了扩展定义,它代表了 Pod 在单机运行过程中的资源质量,主要表现为使用的隔离参数不同,当单机资源紧张时会优先满足高等级 QoS 的需求。如下表所示,Koordinator 将 QoS 整体分为 System(系统级服务),Latency Sensitive(延迟敏感性的在线服务),Best Effort(资源消耗型的离线应用)三类,根据应用性能敏感程度的差异,Latency Sensitive 又细分为 LSE,LSR 和 LS。

在 Priority 和 QoS 的使用上,二者整体是正交的两个维度,可以排列组合使用。不过受模型定义和实际的需求情况影响,部分排列组合存在约束。下表展示了混部场景中经常使用到的一些组合,其中“O”表示常用的排列组合,“X”表示基本使用不到的排列组合。
各场景的实际使用举例如下。
Koordinator 支持多种工作负载的灵活接入混部,这里我们以 Spark 为例,介绍如何使用混部超卖资源。在 K8s 集群中运行 Spark 任务有两种模式:一种是通过 Spark Submit 提交,也就是在本地使用 Spark 客户端直接连接 K8s 集群,这种方式比较简单快捷,不过在整体的管理能力上有所缺乏,常用于开发自测;另一种方式是通过 Spark Operator 提交,如下图所示,它定义了 SparkApplication CRD,用于 Spark 作业的描述,用户可以通过 kubectl 客户端将提交 SparkApplication CR 到 APIServer,随后由 Spark Operator 负责作业生命周期以及 Driver Pod 的管理。
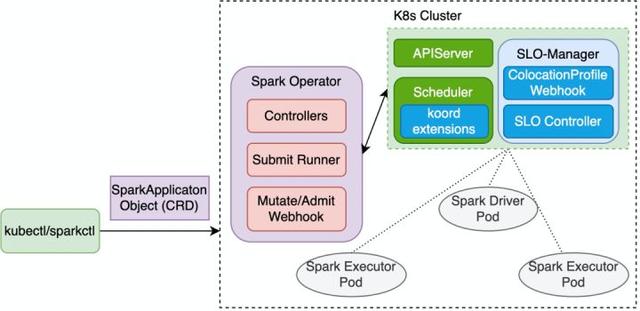
凭借 Koordinator 能力的加持,ColocationProfile Webhook 会自动为 Spark 任务的 Pod 注入相关混部配置参数(包括QoS,Priority,extened-resource等),如下所示。Koordlet 在单机侧负责 Spark Pod 在混部后不会影响在线应用性能表现,通过将 Spark 与在线应用进行混部,可以有效提升集群整体资源利用率。
# Spark Driver Pod exampleapiVersion: v1kind: Podmetadata: labels: koordinator.sh/qosClass: BE...spec: containers: - args: - driver...resources: limits: koordinator.sh/batch-cpu: "1000" koordinator.sh/batch-memory: 3456Mi requests: koordinator.sh/batch-cpu: "1000" koordinator.sh/batch-memory: 3456Mi...资源超发 - Resource Overcommitment
在使用 K8s 集群时,用户很难准确的评估在线应用的资源使用情况,不知道该怎么更好的设置 Pod 的 Request 和 Limit,因此往往为了保障在线应用的稳定性,都会设置较大的资源规格。在实际生产中,大部分在线应用的实际 CPU 利用率大多数时候都比较低,高的可能也就百分之十几或者二十几,浪费了大量已经被分配但未使用的资源。
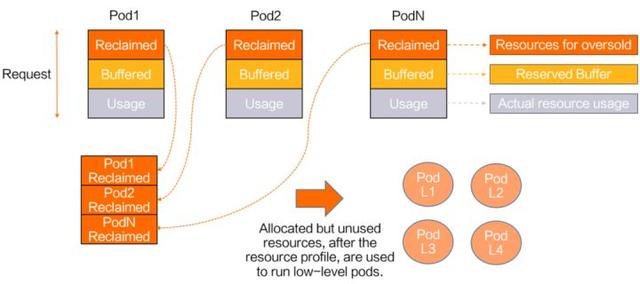
Koordinator 通过资源超发机制回收复用这部分分配但未被使用的资源。Koordinator 根据指标数据评估在线应用的 Pod 有多少资源是可以回收的(如上图所示,标记为 Reclaimed 的部分就是可被回收的资源),这些可回收的资源就可以超发给低优先级的工作负载使用,例如一些离线任务。为了让这些低优先级工作负载方便使用这些资源,Koordinator 会把这些超发资源更新到 NodeStatus 中(如下面所示的 node info)。当在线应用有突发的请求需要处理时要求使用更多的资源,Koordinator 通过丰富的 QoS 增强机制帮助在线应用拿回这些资源以保证服务质量。
# node infoallocatable: koordinator.sh/bach-cpu: 50k # milli-core koordinator.sh/bach-memory: 50Gi # pod infoannotations: koordinator.sh/resource-limit: {cpu: “5k”}resources: requests koordinator.sh/bach-cpu: 5k # milli-core koordinator.sh/bach-memory: 5Gi负载均衡调度 - Load-Aware Scheduling
超发资源可以极大的提升集群的资源利用率,但也会凸显集群内节点之间资源利用率不均匀的现象。这个现象在非混部环境下也是存在的,只是因为 K8s 原生是不支持资源超发机制,节点上的利用率往往不是很高,一定程度上掩盖了这个问题。但当混部时,资源利用率会上升到比较高的水位时就暴露了这个问题。
利用率不均匀一般是节点之间不均匀以及出现局部的负载热点,局部的负载热点会可能影响工作负载的整体运行效果。另一个是在负载高的节点上,在线应用和离线任务之间可能会存在的严重的资源冲突,影响到在线应用的运行时质量。

为了解决这个问题, Koordinator 的调度器提供了一个可配置的调度插件控制集群的利用率。该调度能力主要依赖于 koordlet 上报的节点指标数据,在调度时会过滤掉负载高于某个阈值的节点,防止 Pod 在这种负载较高的节点上无法获得很好的资源保障,另一方面是避免负载已经较高的节点继续恶化。在打分阶段选择利用率更低的节点。该插件会基于时间窗口和预估机制规避因瞬间调度太多的 Pod 到冷节点机器出现一段时间后冷节点过热的情况。

应用接入管理 - ClusterColocationProfile
我们在 Koordinator项目开源之初就考虑到,需要降低 Koordinator 混部系统的使用门槛,让大家可以简单快速的灰度和使用混部技术获得收益。因此 Koordinator 提供了一个 ClusterColocationProfile CRD,通过这个 CRD 和对应的 Webhook ,可以在不侵入存量集群内的组件的情况下,按需针对不同的 Namespace 或者不同的工作负载,一键开启混部能力,Webhook 会根据该 CRD 描述的规则对新创建的 Pod 自动的注入 Koorinator 优先级、QoS 配置和其他混部协议等。
apiVersion: config.koordinator.sh/v1alpha1kind: ClusterColocationProfilemetadata: name: colocation-profile-examplespec: namespaceSelector: matchLabels: koordinator.sh/enable-colocation: "true" selector: matchLabels: sparkoperator.k8s.io/launched-by-spark-operator: "true" qosClass: BE priorityClassName: koord-batch koordinatorPriority: 1000 schedulerName: koord-scheduler labels: koordinator.sh/mutated: "true" annotations: koordinator.sh/intercepted: "true" patch: spec: terminationGracePeriodSeconds: 30举个例子,上面是 ClusterColocationProfile 的一个实例,表示所有带有
koordinator.sh/enable-colocation=true 标签的 Namespace 和该 Namespace 下 SparkOperator 作业创建的 Pod 都可以转为 BE 类型的 Pod(BTW:SparkOperator 创建的 Pod 时会增加标签
http://sparkoperator.k8s.io/launched-by-spark-operator=true 表示这个 Pod 是 SparkOperator 负责的)。
只需要按照如下步骤就可以完成混部接入:
$ kubectl apply -f profile.yaml$ kubectl label ns spark-job -l koordinator.sh/enable-colocation=true$ # submit Spark Job, the Pods created by SparkOperator are co-located other LS Pods.QoS 增强 – CPU Suppress
Koordinator 为保障在线应用在混部场景下的运行时质量,在单机侧提供了丰富的 QoS 增强能力。
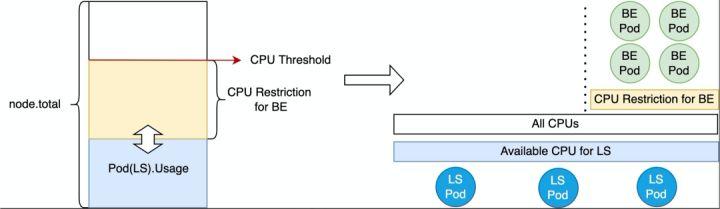
首先向大家介绍 CPU Suppress(CPU 动态压制)特性 。前面向大家介绍了,在线应用大多时候并不会完全用完申请到的资源,会有大量的空闲资源,这些空闲资源除了可以通过资源超发给新创建的离线任务使用外,还可以在节点上还没有新的离线任务需要执行时,尽可能的把空闲的 CPU 资源共享给存量的离线任务。如这个图中所示,当 koordlet 发现在线应用的资源空闲,并且离线任务使用的 CPU 还没有超过安全阈值,那么安全阈值内的空闲 CPU 就可以共享给离线任务使用,让离线任务可以更快的执行。因此在线应用的负载的高低决定了 BE Pod 总共有多少可用 CPU。当在线负载升高时,koordlet 会通过 CPU Suppress 压制 BE Pod,把共享的 CPU 还给在线应用。
QoS 增强 – 基于资源满足度的驱逐
CPU Suppress 在线应用的负载升高时可能会频繁的压制离线任务,这虽然可以很好的保障在线应用的运行时质量,但是对离线任务还是有一些影响的。虽然离线任务是低优先级的,但频繁压制会导致离线任务的性能得不到满足,严重的也会影响到离线的服务质量。而且频繁的压制还存在一些极端的情况,如果离线任务在被压制时持有内核全局锁等特殊资源,那么频繁的压制可能会导致优先级反转之类的问题,反而会影响在线应用。虽然这种情况并不经常发生。

为了解决这个问题,Koordinator 提出了一种基于资源满足度的驱逐机制。我们把实际分配的CPU总量 与 期望分配的 CPU 总量的比值成为 CPU 满足度。当离线任务组的 CPU 满足度低于阈值,而且离线任务组的 CPU 利用率超过 90% 时,koordlet 会驱逐一些低优先级的离线任务,释放出一些资源给更高优先级的离线任务使用。通过这种机制能够改善离线任务的资源需求。
QoS 增强 - CPU Burst
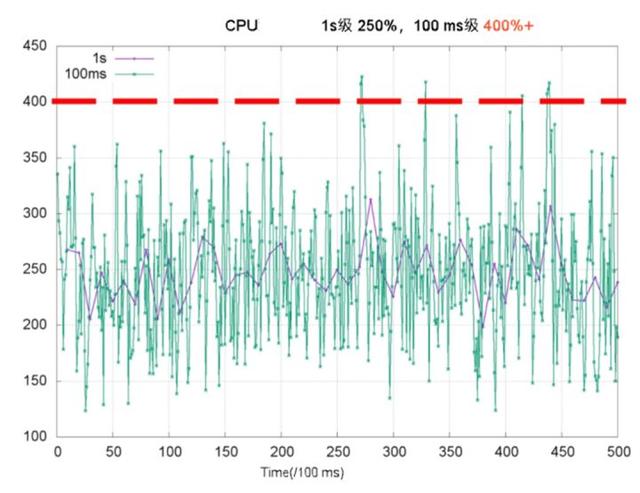
我们知道 CPU 利用率是一段时间内 CPU 使用的平均值。而且我们大多数时候都是以一种较粗的时间单位粒度观察统计 CPU 利用率,这个时候观察到 CPU 利用率的变化是基本稳定的。但如果我们以较细的时间单位粒度观察统计 CPU 利用率,可以看到 CPU 使用的突发特征非常明显,是不稳定的。如下图以 1s 粒度观察利用率(紫色)和 100ms 粒度观察的利用率(绿色)对比。
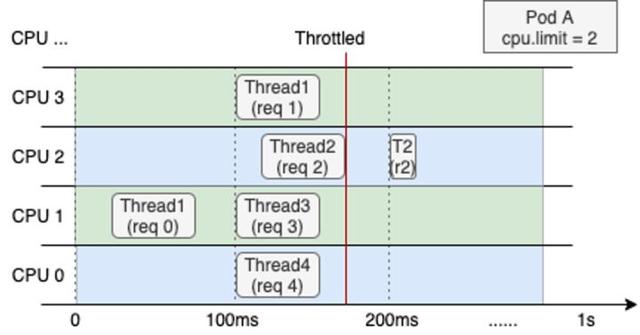
细粒度数据观测表明CPU 突发和压制是常态。Linux内核中通过 CFS 带宽控制器 cgroup CPU 的消耗,它限制了 cgroup 的 CPU 消耗上限,因此经常会遇到一些突发流量下业务短时间内被狠狠地 throttle,产生长尾延迟,造成服务质量下降,如下图所示,Req2 因为 CPU 被压制,延期到第 200ms 才得到处理。
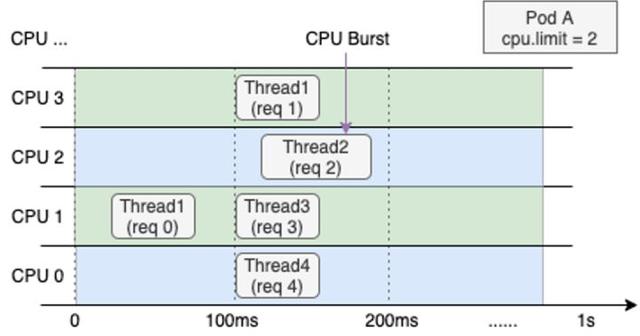
为了解决这个问题,Koordinator 基于 CPU Burst 技术帮助在线应用应对突发情况。CPU Burst 允许工作负载在有突发请求处理使用CPU 资源时,使用日常的 CPU 资源。比如容器在日常运行中使用的 CPU 资源未超过 CPU 限流,空余的CPU资源将会被积累。后续当容器运行需要大量 CPU 资源时,将通过 CPU Burst 功能突发使用 CPU 资源,这部分突发使用的资源来源于已积累的资源。如下图所示,突发的 Req2 因为有积累的 CPU 资源,通过 CPU Burst 功能得以避免被 throttle,快速的处理了请求。
QoS 增强 – Group Identity
在混部场景下,Linux 内核虽然提供了多种机制满足不同优先级的工作负载的调度需求,但当一个在线应用和一个离线任务同时运行在一个物理核上时,因为在离线任务都共享相同的物理资源,在线应用的性能不可避免的会被离线任务干扰从而性能下降。Alibaba Cloud Linux 2 从内核版本 kernel-4.19.91-24.al7 开始支持 Group Identity 功能,Group Identity 是一种以 cgroup 组为单位实现的调度特殊优先级的手段,简单讲,当在线应用需要更多资源时,通过 Group Identity 可以暂时压制离线任务保障在线应用可以快速的响应。
要使用这个特性比较简单,可以配置 cpu cgroup 的 cpu.bvt_warp_ns 即可。在 Koordinator 里,BE 类离线任务对应配置为 -1,即最低优先级, LS/LSR 等在线应用类型设置为 2,即最高优先级。
QoS 增强 – Memory QoS
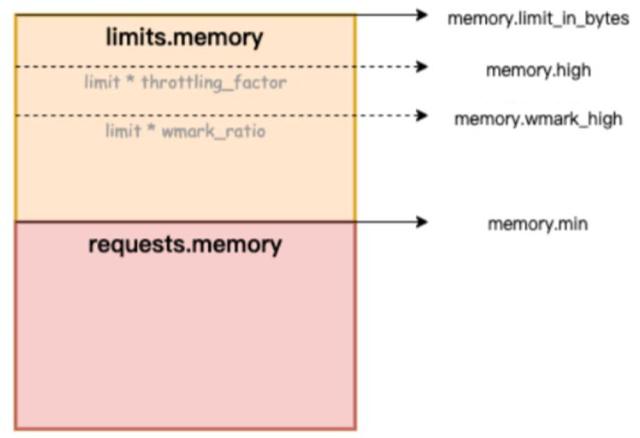
容器在使用内存时主要有以下两个方面的约束:
为了提高应用运行时性能和节点的稳定性,Koordinator 引入Memory QoS 能力,为应用提升内存性能。当功能开启时,koordlet 依据自适应配置内存子系统(Memcg),在保障节点内存资源公平的基础上,优化内存敏感型应用的性能。
精细化 CPU 编排 - Find-grained CPUOrchestration
我们正在设计和实现精细化 CPU 编排机制。
我们为什么要提供这个编排机制呢?随着资源利用率的提升进入到混部的深水区,需要对资源运行时的性能做更深入的调优,更精细的资源编排可以更好的保障运行时质量,从而通过混部将利用率推向更高的水平。
我们把 Koordinator QoS 在线应用 LS 类型做了更细致的划分,分为 LSE、LSR 和 LS 三种类型。拆分后的 QoS 类型具备更高的隔离性和运行时质量。通过这样的拆分,整个 Koordinator QoS 语义更加精确和完整,并且兼容 K8s 已有的 QoS 语义。
而且我们针对 Koordinator QoS,设计了一套丰富灵活的 CPU 编排策略,如下表所示。
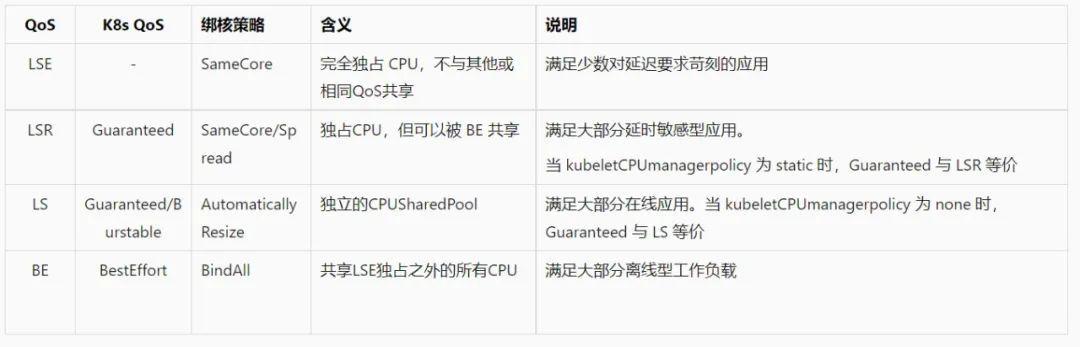
Koordinator QoS 对应的 CPU 编排策略
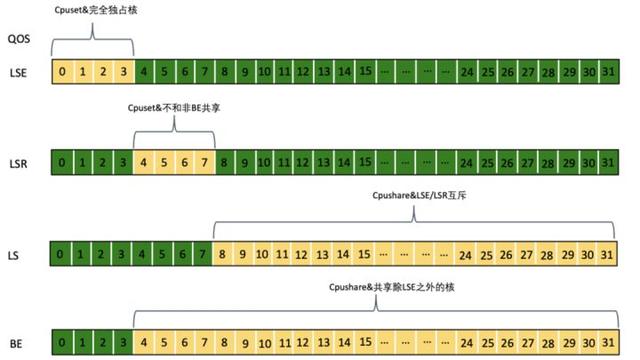
另外,针对 LSR 类型,还提供了两种绑核策略,可以帮助用户平衡性能和经济收益。
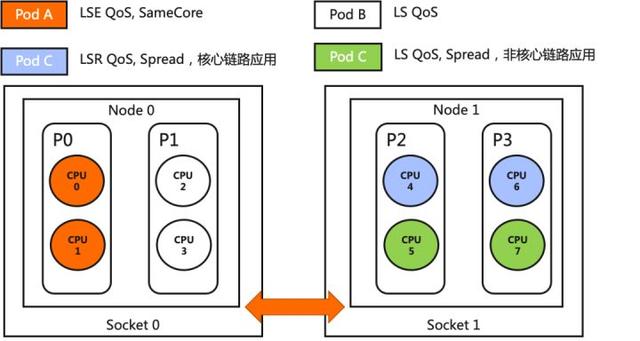
Koordinator 的这套精细化 CPU 编排方案兼容 K8s 已有的 CPUManager 和 NUMA Topology Manager 机制的。也就是说存量集群使用 Koordinator 时不会影响存量的 Pod,可以安全放心的灰度使用。
资源预留 - Resource Reservation
资源预留是我们另一个正在设计的特性。资源预留可以帮助解决资源管理的痛点。例如有时候像大家熟悉的互联网业务场景,都有非常强的峰谷特征。那么我们可以在峰值到达前预留资源确保一定有资源满足峰值请求。另外像大家在扩容时可能也会遇到的问题,发起扩容后因为没有资源 Pod 就 Pending 在集群里,如果能在扩容前提前确认是否资源,没资源时加新机器就能有更好的体验。还有像重调度场景,可以通过资源预留保障被驱逐的 Pod 一定有资源可以用,可以极大的降低重调度的资源风险,更安全放心的使用重调度能力。
Koordinator 的资源预留机制不会侵入 K8s 社区已有的 API 和代码。并支持 PodTemplateSpec,模仿一个Pod 通过调度器找到最合适的节点。并支持声明所有权的方式支持 Pod 优先使用预留资源,例如当一个真正的 Pod 调度时,会优先尝试根据 Pod 的特征找到合适的预留资源,否则继续使用集群内空闲的资源。
下面是一个 Reservation CRD 的例子(最终以 Koordinator 社区通过的设计为准)
kind: Reservationmetadata: name: my-reservation namespace: defaultspec: template: ... # a copy of the Pod's spec resourceOwners: controller: apiVersion: apps/v1 kind: Deployment name: deployment-5b8df84dd timeToLiveInSeconds: 300 # 300 seconds nodeName: node-1status: phase: Available ...精细化 GPU 调度 - GPU Scheduling
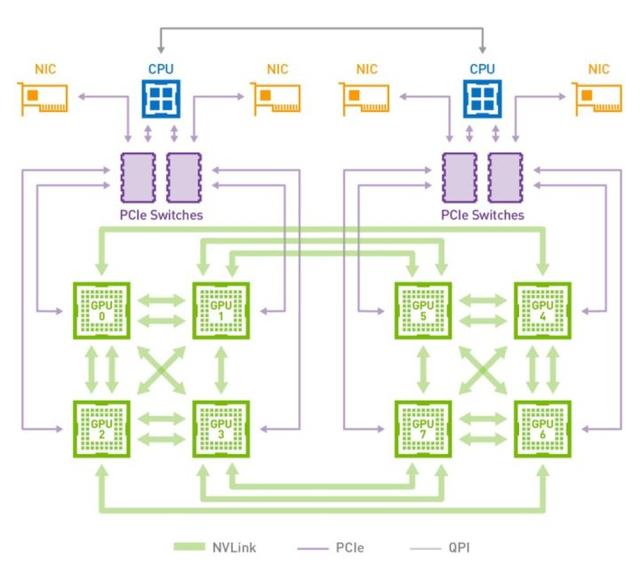
精细化 GPU 调度是我们未来期望提供的一种能力。GPU 和 CPU 在资源特征上差异比较大,而且在像机器学习的模型训练场景中,一个训练作业会因为不同的拓扑结构导致不同的性能差异,例如根据机器学习作业内 worker 之间不同的拓扑组合,会得到不同的性能,这不仅体现在集群内节点之间,而且即使单个节点上,GPU 卡之间也因为像是否使用 NVLINK 也会有巨大的性能差异,这让整个 GPU 的调度分配逻辑变的十分复杂。而且 GPU 和 CPU 的计算任务在集群内混部时,怎么避免两种资源的浪费,也是需要考虑解决优化的问题。
规格推荐 - Resource Recommendation
后续 Koordinator 还会提供基于画像的规格推荐能力。前面也提到,用户是很难精确评估应用程序的资源使用情况的,Request 和 Limit 到底是什么关系,到底该怎么设置 Request/Limit,对于我这个应用来说哪种组合才是最合适的?经常高估或者低估 Pod 资源规格,导致资源浪费甚至稳定性风险。
Koordinator 会提供资源画像能力,采集并加工分析历史数据,推荐更准确的资源规格。

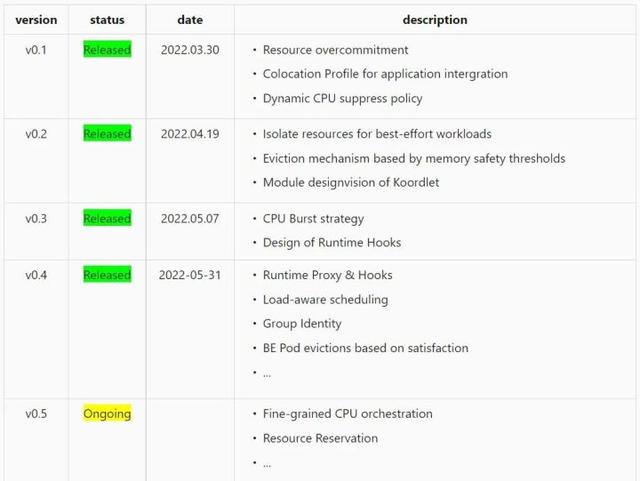
目前为止,我们在最近两个多月发布了四个版本。前面几个版本主要提供了资源超发、QoS 增强的能力,并且还开源了新的组件 koord-runtime-proxy。在 0.4 版本中,我们开始在调度器上发力,首先开放了负载均衡调度能力。目前 Koordinator 社区正在实现 0.5 版本,在这个版本中,Koordinator 会提供精细化 CPU 编排和资源预留的能力,在之后的规划中,我们还会在重调度、Gang 调度、GPU 调度、弹性 Quota 等实现一些新的创新。

非常期待您在使用 Koordinator 积极的反馈遇到的任何问题、帮助改善文档、修复 BUG 和添加新功能
原文链接:
http://click.aliyun.com/m/1000349753/
本文为阿里云原创内容,未经允许不得转载。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号