阿里通义Qwen2:领先斯坦福大模型榜单的开源强模新纪元
发表时间: 2024-06-20 11:10
来源:环球网
【环球网科技综合报道】6月20日消息,斯坦福大学的大模型测评榜单HELM MMLU发布最新结果,斯坦福大学基础模型研究中心主任Percy Liang发文表示,阿里通义千问Qwen2-72B模型成为排名最高的开源大模型,性能超越Llama3-70B模型。
MMLU(Massive Multitask Language Understanding,大规模多任务语言理解)是业界最有影响力的大模型测评基准之一,涵盖了基础数学、计算机科学、法律、历史等57项任务,用以测试大模型的世界知识和问题解决能力。但在现实测评中,不同参评模型的测评结果有时缺乏一致性、可比性,原因包括使用非标准提示词技术、没有统一采用开源评价框架等等。
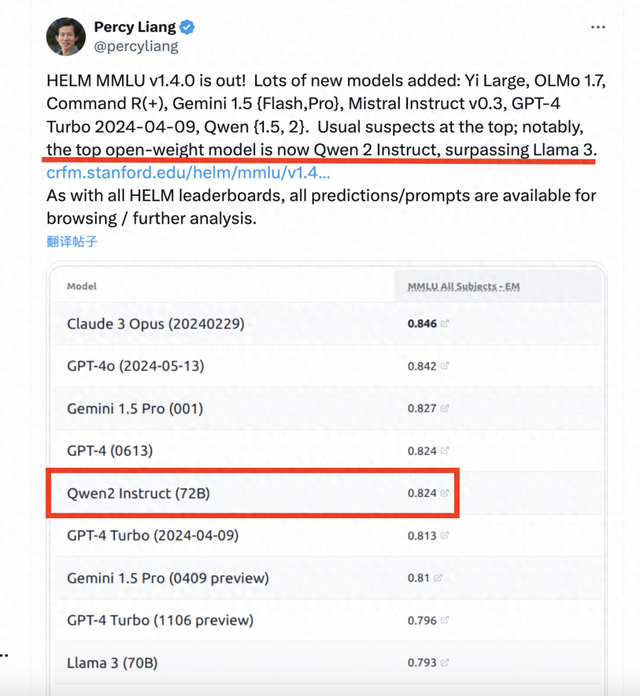
斯坦福大学基础模型研究中心(CRFM,Center for Research on Foundation Models)提出的基础模型评估框架HELM(A holistic framework for evaluating foundation models),旨在创造一种透明、可复现的评估方法。该方法基于HELM框架,对不同模型在MMLU上的评估结果进行标准化和透明化处理,从而克服现有MMLU评估中存在的问题。比如,针对所有参评模型,都采用相同的提示词;针对每项测试主题,都给模型提供同样的5个示例进行情境学习,等等。
日前,斯坦福大学基础模型研究中心主任Percy Liang在社交平台发布了HELM MMLU最新榜单,阿里巴巴的通义千问开源模型Qwen2-72B排名第5,仅次于Claude 3 Opus、GPT-4o、Gemini 1.5 pro、GPT-4,是排名第一的开源大模型,也是排名最高的中国大模型。
据悉,通义千问Qwen2于6月初开源,包含5个尺寸的预训练和指令微调模型,目前Qwen系列模型下载量已经突破1600万。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号