Redis为何能在缓存架构中如此迅速?揭秘顶级缓存策略
发表时间: 2023-10-28 08:10
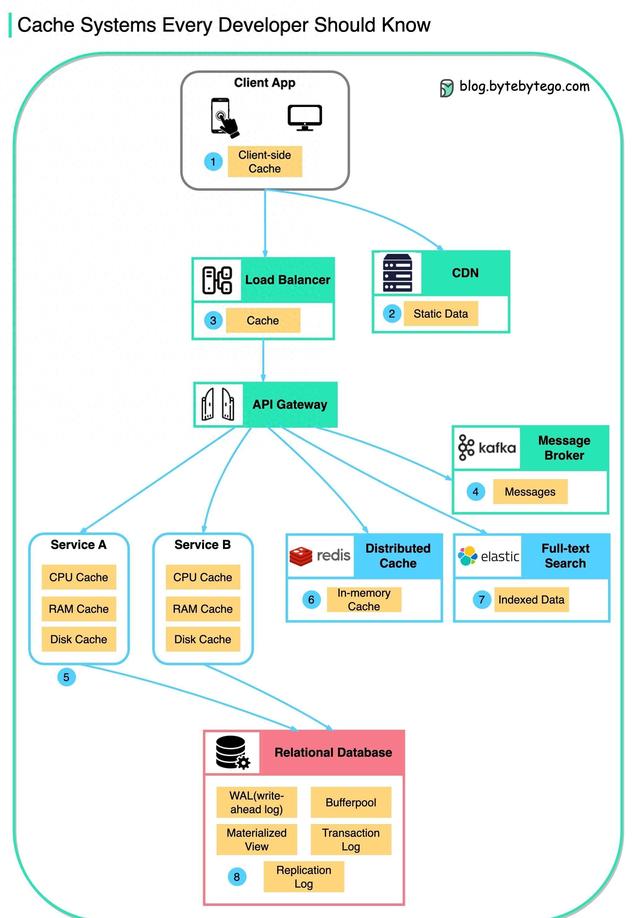
缓存数据的位置在典型架构中的重要性不可忽视。从客户端应用程序到消息传递基础设施,再到服务和数据库,各个层级都可以通过缓存来提升性能和效率。本文将介绍这些不同层级中的缓存位置,并解释为什么Redis作为一种分布式缓存具有出色的性能。在典型架构中,客户端应用程序往往是第一层缓存数据的位置。通过HTTP响应,浏览器可以缓存数据,以减少对服务器的请求。当第一次请求数据时,服务器会在HTTP标头中包含过期策略,然后再次请求时,客户端应用程序会优先尝试从浏览器缓存中检索数据。这样可以大大减少对服务器的请求,提高响应速度。CDN(内容分发网络)是另一个缓存数据的位置。CDN可以缓存静态网页资源,并通过附近的CDN节点提供给客户端。这样可以减少数据传输的时间和成本,提高用户的访问速度。负载均衡器也可以作为缓存数据的位置。在负载均衡过程中,负载均衡器可以缓存资源,以减少对后端服务器的请求。
这在高流量情况下尤为重要,可以有效地分摊服务器的负载,提高整个系统的性能。消息传递基础设施中的消息代理也可以缓存数据。消息代理首先将消息存储在磁盘上,然后按照消费者的节奏逐步检索消息。根据保留策略,数据会在Kafka集群中缓存一段时间。这种方式既能保证数据的可靠性,又能提高整体的处理效率。服务中也有多层缓存。如果数据没有缓存在CPU缓存中,服务将尝试从内存中检索数据。有时,服务还会使用二级缓存将数据存储在磁盘上,以进一步提高查询的速度和效率。分布式缓存是一种非常重要的缓存数据的位置。像Redis这样的分布式缓存可以将键值对保存在内存中,提供比数据库更好的读/写性能。这对于需要快速访问和处理大量数据的应用程序来说是非常有价值的。全文搜索也需要使用缓存来提高性能。
例如,使用Elastic Search进行文档搜索或日志搜索时,数据副本会在搜索引擎中建立索引,以加快搜索的速度和效率。即使在数据库中,我们也会使用不同级别的缓存来提升性能。在构建B树索引之前,数据会先被写入WAL(Write-ahead Log)。数据库还会分配一个Bufferpool来缓存查询结果的内存区域。此外,物化视图可以预先计算查询结果并将其存储在数据库表中,以获得更好的查询性能。事务日志和复制日志则用于记录事务和数据库集群中的复制状态。那么,为什么Redis如此快速呢?主要有三个原因。首先,Redis是一个基于RAM的数据存储,RAM的访问速度至少比随机磁盘访问快1000倍,因此能够提供更高的读写性能。其次,Redis利用IO多路复用和单线程执行循环来提高执行效率。这种方式可以减少线程切换和内存拷贝的开销,提高整体的处理速度。
最后,Redis利用多种高效的低级数据结构来存储数据,例如字符串、哈希表、列表等,这些数据结构在不同场景下具有高效的操作和查询能力。除了作为缓存之外,Redis还有其他的用途。它可以用作消息队列,实现异步消息处理。它还可以用作分布式锁,实现并发控制。此外,Redis还支持发布/订阅模式,可以用于实时通信和事件驱动的应用程序。总结一下,缓存数据在典型架构中的位置多种多样,从客户端应用程序到消息传递基础设施,再到服务和数据库,各个层级都可以使用缓存来提升性能和效率。而Redis作为一种分布式缓存,具有出色的性能和多样化的应用场景。通过合理地使用缓存和选择适合的缓存位置,我们可以极大地提高系统的性能和可扩展性。你认为在你的架构中,如何合理地使用缓存来提升性能?请在评论中分享你的想法和经验。Redis在各种场景下的应用非常广泛。
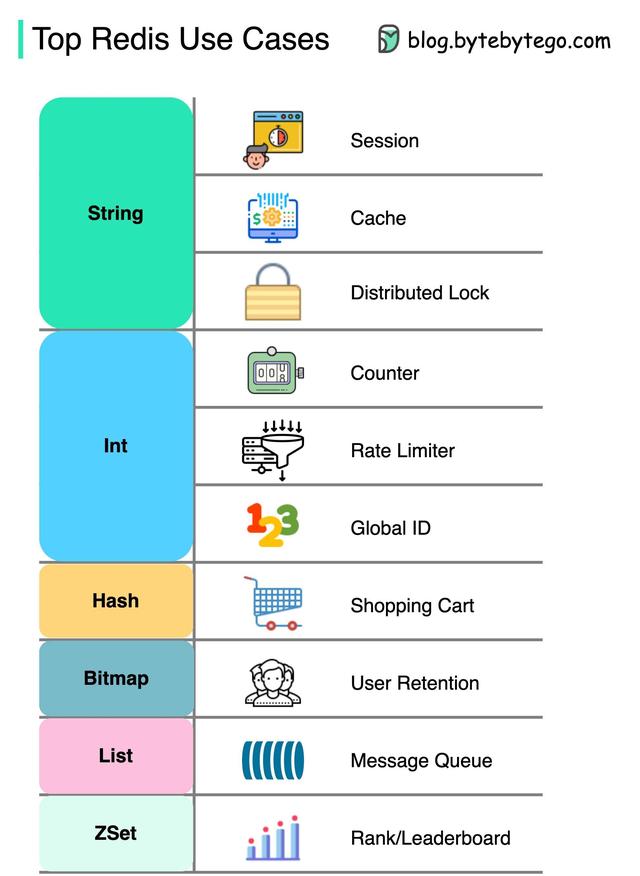
无论是在会议中共享用户会话数据,还是在缓存对象或页面时提高性能,Redis都能发挥巨大的作用。除此之外,Redis还可以用于分布式锁、统计、速率限制器、全局ID生成器、购物车、计算用户保留率、消息队列以及排行等方面。在设计大型系统时,选择合适的缓存策略也是至关重要的。接下来,我们将介绍五种常用的缓存策略。第一种缓存策略是基于时间的缓存。这种策略通过设置一个固定的时间,比如30秒或1分钟,来确定缓存的有效期。当数据过期时,系统会重新从数据库中获取最新的数据并更新缓存。这种策略适用于数据变化不频繁的场景,可以有效减轻数据库的负载。第二种缓存策略是基于事件的缓存。这种策略通过监听数据库中的数据变化事件,当数据发生变化时,立即更新缓存。这样可以保证缓存中的数据始终与数据库中的数据保持一致。这种策略适用于数据变化频繁的场景,可以提高系统的实时性。第三种缓存策略是基于LRU算法的缓存。
LRU(Least Recently Used)算法是一种常用的缓存淘汰算法,它会根据数据的访问频率来决定哪些数据保留在缓存中,哪些数据被淘汰。当缓存空间不足时,会优先淘汰最近最少使用的数据。这种策略适用于缓存空间有限且数据访问具有时序性的场景。第四种缓存策略是基于LFU算法的缓存。LFU(Least Frequently Used)算法也是一种常用的缓存淘汰算法,它会根据数据的访问频率来决定哪些数据保留在缓存中,哪些数据被淘汰。当缓存空间不足时,会优先淘汰访问频率最低的数据。这种策略适用于数据访问频率不均衡的场景。最后一种缓存策略是基于一致性哈希算法的缓存。一致性哈希算法是一种用于分布式系统中数据分片的算法,它可以保证在节点发生变化时,尽量少地影响已有的缓存数据。这种策略适用于分布式缓存的场景,可以提高系统的可扩展性和容错性。
总结起来,选择合适的缓存策略对于设计大型系统非常重要。根据不同的场景和需求,可以选择基于时间的缓存、基于事件的缓存、基于LRU算法的缓存、基于LFU算法的缓存以及基于一致性哈希算法的缓存。通过合理地使用缓存,可以提高系统的性能和可扩展性。现在,你有什么其他关于缓存策略的疑问吗?欢迎在评论区留言讨论。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12


 鲁公网安备37020202000738号
鲁公网安备37020202000738号