C++内存优化的悲剧:一次善意却带来灾难
发表时间: 2024-03-12 22:45
我又来了,又是一次九点半刚下班后的更新,各位劳烦点点关注。。。创作不易啊。。。
事情的背景是这样的,有个同学,需要开发一个需求,需求的核心经过我的简化后,大致描述如下:
赋值规则如下:
a. curTreeNode->left->val = curTreeNode->val * 2 + 1;
b. curTreeNode->right->val = curTreeNode->val * 2 + 2;
用语言描述就是,二叉树的某个节点的子左节点如果存在,那么子左节点的值应该是父节点值的两倍 加1, 如果二叉树的某个节点的子右节点存在,那么子右节点的值应该是父节点的值的两倍加2。
然后,这个很简单的需求,三下五除二就实现了,具体核心代码如下:
原版本是C语言版本,大家将就看,肯定是有更好的实现方式,这里只是完美呈现事实:
enum ChildType { LEFT = 1, RIGHT};bool exist[2000000];void dig(TreeNode* tree, int parentVal, enum ChildType direction) { if (tree == nullptr) return ; // 简单的递归实现 ,根据规则重写二叉树, // 赋值需要标记左右节点 tree->val = 2 * parentVal + direction; exist[tree->val] = true; // 使用tree -> val 当作下标,填充exist 数组,达到O(1)索引的目的 dig(tree->left, tree->val, LEFT); dig(tree->right, tree->val, RIGHT);}class FindElements { public: FindElements(TreeNode* root) { memset(exist, 0, 2000000); // 初始化exists 数组 dig(root, -1, RIGHT); // 递归刷新树节点值,并填充exists 数组 } bool find(int target) { return exist[target]; // 给定target 是否存在二叉树,可以直接使用下标进行索引 }};额,总的来说,没啥可说的,就是个简单的递归遍历二叉树,然后构建数组索引,达到O(1)判断可见性的目的。
然后,重点来了,这位同学觉得,我这个exists 数组有点浪费啊,就是为了存一个是否存在,0,1 一个bit位就够用了,我现在用一个字节(8bit)的bool类型去存,有点憨憨啊。
这内存瞬间损失了八倍有木有啊。
这作为一个底层语言开发,对性能这么敏感,这哪儿行啊。。必须改,改成单个bit位的。
欸,你说巧不巧,我刚好能用个现成的,c++不是有个bitset 吗? 就用这个多香啊?
于是,他兴高采烈的把上面的exist 数组改成如下:
bool exists[2000000] =====> std::bitset<1> exists[2000000]; //这岂不完美,一个bit一个,// 然后总共200000 个,占用应该是2000000/8个字节吧,瞬间内存省了八倍啊然而,再往下一测试,傻眼的事情发生了,这内存使用的咋还越来越多了呢?
我们来探个究竟,先写一个简单的代码,探探:
int main() { std::bitset<1> one_bit; bool one_bool = false; std::cout << sizeof one_bit << '\n'; std::cout << sizeof one_bool << '\n'; return 0;}打印结果如下:

发现bitset 打印的字节是4, bool 打印的字节是1
这就可以解释上面代码的问题了,一个bitset 原来是占了4个字节啊,一个bool 才占了一个字节,那你2000000个bitset 可不比bool 占的内存更多了嘛。
然后我们再试试如下代码:
int main() { std::bitset<1> one_bit; std::cout << sizeof one_bit << '\n'; std::bitset<31> has_31_bit; std::cout << sizeof has_31_bit << '\n'; std::bitset<32> has_32_bit; std::cout << sizeof has_32_bit << '\n'; std::bitset<33> has_33_bit; std::cout << sizeof has_33_bit << '\n'; return 0;}打印结果如下:
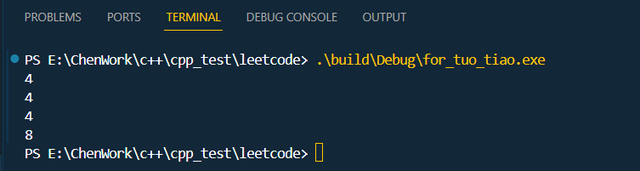
bitset不同位打印结果
从上面打印可以看出,原来,bitset 是 以四个字节为单位做分配的,但凡是小于32个bit,都是四个字节的大小,但凡是小于64个bit位,都是八个字节的大小。
所以,正确的bitset 的用法应该是怎么去改呢?
bool exists[2000000] =====> std::bitset<2000000> exists; //正确的bitset使用方式如上所示:那就是真的使用bitset 做了压缩了,我们做一下测试:
测试代码如下:
int main() { std::bitset<20000> exists_bit; bool exists[20000]; std::cout << sizeof(exists_bit) << '\n'; std::cout << sizeof(exists) << '\n'; return 0;}打印结果如下:
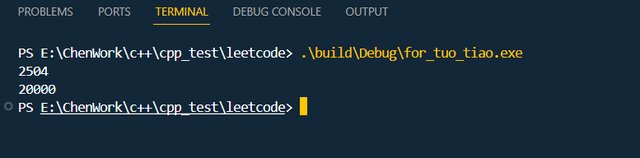
使用bitset 字节数是2504, 不使用时20000
可见,bitset 的确能够在不丢失信息的情况下, 帮助我们压缩状态,节省内存,但是,节省的内存未必是8的倍数,要理解bitset 的使用方法和扩展方式,才能对bitset如何节省内存有更深入的了解。
好的,希望大家今天都能有所收获。如果大家有任何想要学习或者想要了解的IT知识,可以关注,给我留言,任何IT相关知识,我都可以给大家讲解与科普。
最后,重点的重点,求关注啊。。粉丝都不涨的啊。。。小哥哥小姐姐们,点点关注。。。。。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号