详解MySQL执行计划:深度分析与解读
发表时间: 2023-02-10 00:23
实际开发中经常会遇到需要优化sql语句的场景,通常我们会通过看sql执行计划来分析然后做优化,下面我们以一条简单的sql为例来分析执行计划。
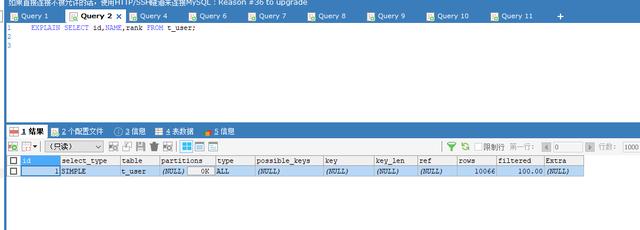
可以看到有很多的信息,我们对一些关键字段做一些解释:
id:id越大对应的优先级越高,id相同时从上到下执行
select type:查询的类型
simple 简单查询,查询中不包含子查询和union查询,就像我们上面的那条sql语句
primary 复杂查询的最外层
subquery 包含在select中的子查询,不在from后面,from后面的子查询是衍生查询,查询时生成的零时表
derived 衍生查询,from后面的子查询是derived
table:当前这条sql查询的数据来源
partitions:分区,很少用
type:表示sql的访问类型,system>const>eq_ref>ref>range>index>all,一般要保证达到range,在执行阶段不一定会访问表,有可能优化阶段就可以拿到结果,比如求id最小值min/max等,根据b+树的特性,优化阶段可以直接拿到结果。
1、system:跟const类似,是const的一种特例,一般查询的表只有一条结果,类似一个常量
2、const:一般用主键id或者唯一索引,一般查询只有一条数据
3、eq_ref:关联查询,一般是两个表的主键或者唯一key关联,没有太多的优化空间
4、ref:查询条件查出来的结果可能有多个,不是唯一的,结果集可能有多条,可以是普通索引查询或者联合索引最左前缀
5、range:范围查询,范围太大比较慢
6、index:扫描全部索引,查询的结果,聚簇索引和非聚簇都可以拿到结果,一般优先选择二级索引,二级索引比较小,比如二级索引和主键索引都可以查到结果,优先选择二级索引
7、all:全表查询,不走索引
possible_keys:sql通过查询分析,执行时可能会用到的索引,但实际不一定会用到
key:sql真正执行时用到的索引,可能出现possible_keys有值,key没有值
key_len:实际查询时用到的索引长度,key_len计算规则
字符串:
char(n):n字节长度
varchar(n):如果是utf8字集,3n+2字节长度,2是用来存储字符串的长度
数字类型:
tinyint :1字节
smallint :2字节
int :4字节
long :8字节
时间类型:
date:3字节
timestamp :4字节
datetime :8字节
注意:如果字段允许为空,则需要增加1个字节来记录字段允许为空
ref:显示key列中使用到的索引,关联的条件是什么,可能是常量也可能是字段
rows:查询需要扫描的行数,预估值
filtered:rows*filtered/100 一般估算两个表关联查询时连接的行数
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号