大模型之争:开源与闭源,谁将主导未来?
发表时间: 2024-06-17 18:05
咱们国内的网友对自家的原创是有执着的,因为不了解模型建设,部分网友认为用了外国的“开源模型”就是在偷懒,没有技术含量,当然,某些企业是存在这些问题的,但是也有一些是在开源模型上得到更进一步的发展。
而不管是开源和闭源都是为了模型生态建设的越来越好,国内的厂商,对开源和闭源也是有争论的。

从技术发展策略的角度来看,阿里坚持开放源代码的原则。他们不仅公开了一系列人工智能模型,还建立了一个名为"魔搭社区"的AI模型开源平台。阿里云的首席技术官周靖人明确表示,开放源代码生态对全球技术发展的贡献是显而易见的,无需进一步讨论。
与此相反,百度则坚定地支持闭源策略。百度的首席执行官李彦宏公开宣称,开放源代码模型的价值有限,而闭源模式才能带来真正的商业机会,吸引资金和人才,并认为开放源代码的模型将逐渐落后。
腾讯在开源和闭源之间的态度则显得有些犹豫不决。直到最近,他们才决定将"混元文生图"大模型开源。该产品的负责人芦清林承认,在文生图领域,开源和闭源模型之间的差距正在扩大,他希望通过开源能够缩小这一差距。
开放源代码确实有其独特的优势,比如它能够推动技术的普及和共享,吸引众多开发者的参与,从而加速创新的步伐。然而,闭源策略也有其独到之处,它能够更有效地保护公司的知识产权和商业秘密,使得企业能够集中精力进行技术的研发和改进。成都市人工智能产业协会的秘书长李娅娜指出,我们不能简单地将二者进行比较,而应该根据各自的实际情况,选择最合适的技术发展路径来实现我们的发展目标。
开源模型有哪些优势
开源大模型是让大模型行业卷起来的根源。
在ChatGPT首次亮相时,业界普遍感到不安;然而,随着Llama模型的开源,业界的情绪转变为兴奋,因为更多的人看到了希望的光芒。
开源的优势在于能够汇聚众多人才,尽管有人可能会质疑AI领域的工作需要顶尖的专家,但俗话说得好,"三个臭皮匠,赛过诸葛亮"。许多业界领袖实际上也是从零开始,从头进行预训练,这需要巨大的资源投入。
当有更多的人参与进来,就会有更多的创意和想法,从而产生许多与大型模型相关的创新技巧,例如如何扩展模型的上下文理解能力(如NTK、YaRN、LongLora等技术)、如何以较低的成本合并模型以获得更大、更优的模型(如SOLAR、Llama-Pro等方法)、以及如何更有效地实现模型与人类偏好的对齐(如DPO、ORPO等技术)等。如果没有优质的开源模型作为基础,许多研究可能就无法得到发展和涌现。
随着越来越多的人投身于大型模型的研究,这无疑将为大型模型的进步带来正面影响。即使是那些坚持闭源策略的大型模型团队,也能够借鉴外部的创新方法,以此来优化和提升他们模型的性能。
随着微调技术、部署框架等的开源化,现在许多中小型企业和开发者能够迅速地应用大型模型,探索其在实际应用中的潜力和限制,使得大型模型的应用更加多样化和灵活,从而促进了人工智能技术的商业化和实际应用。
正如基于通用问答系统的开源大型模型Qwen1.5-110B在经过微调后性能显著超越了其原始版本一样,开源的力量是巨大的,它能够激发出更多的创新和突破。
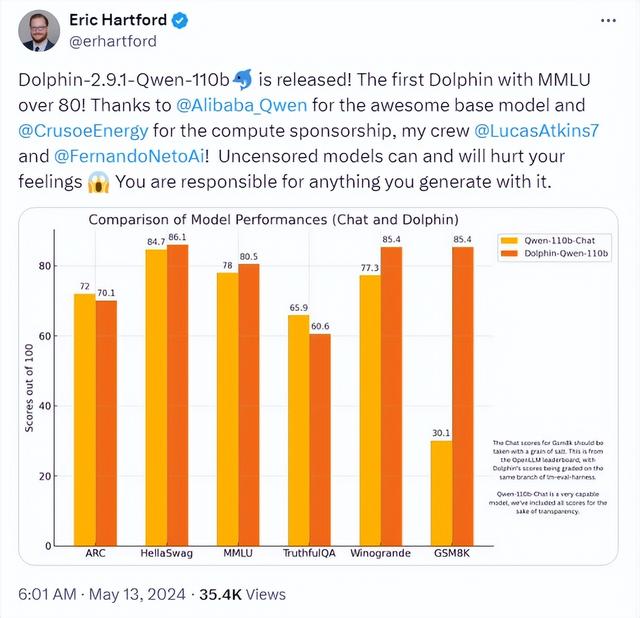
当然上面只是从技术思维来讲开源的好处,但不可否认的是开源的商业模式确实不明朗,很难避免白嫖的现象。
考虑到当前GPU的成本,许多选择使用开源模型的企业倾向于选择10B参数规模的模型,因为规模更大的模型成本过高,难以承受。在这种情况下,选择API服务可能更为经济。因此,这为那些在开源市场占据领先地位的企业提供了机会。
最终,开源的大型模型和闭源的大型模型应该是互补的,它们服务于不同的用户群体。那些资源有限、愿意深入研究、需要更多定制化服务的用户,可能会倾向于选择开源的大型模型。而那些资源丰富、希望立即获得服务、追求更高端体验的用户,则可能更倾向于选择闭源的大型模型。
开源模型与闭源模型的差距
开源大模型跟闭源大模型最后应该是相辅相成的
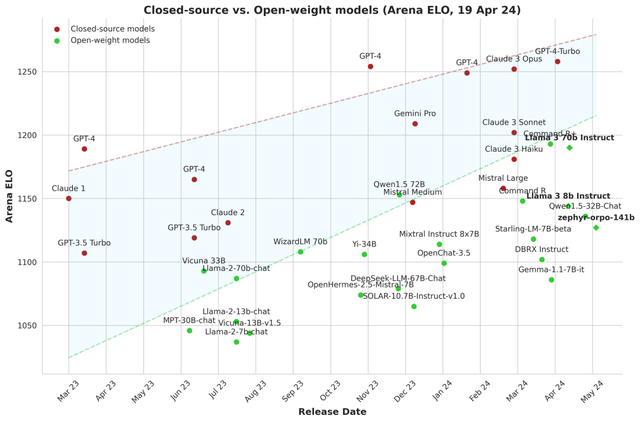
很难相信大型模型的发展速度如此之快,让人难以置信的是,曾经令人惊叹的GPT3.5现在已经不再能够与顶级开源模型相提并论,它们的目标已经转向了GPT4。
在性能对比的排行榜上,我们可以看到,开源模型在顶级模型中占据了相当的比例,这表明它们与闭源模型之间的差距正在缩小。从实际使用体验来看,这些顶级开源模型的表现也是相当令人满意的。
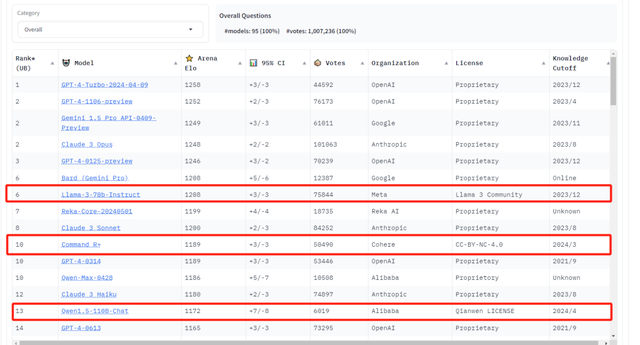
闭源模式由于数据的独占性,确实形成了一定的进入壁垒,使得追赶变得困难,主要依赖于那些领先的开源组织来推动发展。对于个人或小型团队而言,他们可能只能做一些小规模的修补和改进,毕竟从头开始进行大规模预训练(Pre-train)是不现实的。
然而,不要低估这些小规模的修补和改进工作,因为在某些特定任务上,即使是对72B参数的模型进行微调,也有可能超越GPT4的性能。
开源模型哪家强
目前,开源模型的数量相当可观,但在中国,阿里云推出的通义千问模型在性能和全面性方面都表现出色。
Qwen系列模型是真正开放的,从1.5系列的0.5B到1.8B、7B、14B、32B、72B,直至目前的110B参数模型,还包括Code系列和MOE系列,以及1系列中的VL模型,提供了全面的选择。
无论你需要何种规模的模型,Qwen都能提供,并且性能卓越。在HuggingFace发布的开源大型模型排行榜Open LLM Leaderboard上,Qwen1.5-110B模型超越了Meta的Llama-3-70B,位居榜首,这充分证明了其强大的实力。
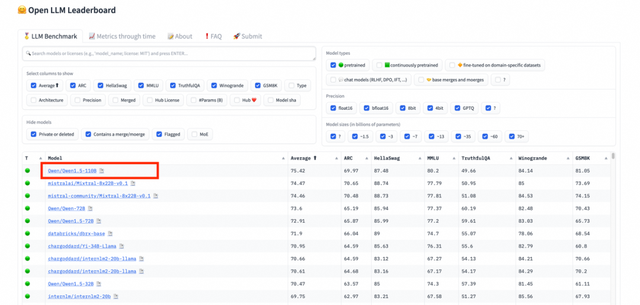
据初步统计数据显示,Qwen系列开源模型的下载量已经超过了700万次。
在当前国内无法访问HuggingFace的情况下,魔搭社区成为了获取模型的重要渠道。它不仅提供了模型下载服务,还提供了一定时长的免费GPU使用(对于测试小型模型来说已经足够),更不用说它还包含了其他配套的模型训练项目和Agent项目。
可以说,魔搭社区提供了一站式的服务,让人很难不对其产生好感。
尽管国内还有其他的开源模型,但如果论及全面性,Qwen系列模型仍然是首屈一指的。
信息来源于网络
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号