中国数据库:40年的陪伴,黄金时代的来临
发表时间: 2023-03-16 10:22

数据库,成为率先突围的关键技术。
文 | 华商韬略 熊剑辉
2023年“两会”期间,最新组建的“国家数据局”,引发了人们的特别关注。
有人认为,它的成立意味着“数字中国”将进入快车道;更有人认定,以数据库技术为核心的数据安全领域,有望迎来“大提速”。
显然,中国数据库正迈出“关键一步”。
【从集中式到分布式 数据库革命悄然爆发】
作为数字经济的“根技术”,数据库的重要性不亚于芯片。
一切数据,都必须在数据库中奔跑。
人们每天社交、餐饮、游戏、支付、打车等日常活动,离不开各种各样的程序应用。它们的背后,都离不开数据库。
而数据库技术的诞生与发展,即便顺应了时代的召唤,也充满了斗争与艰辛。
上世纪70年代,IBM的天才研究员科德,率先提出关系型数据库的理论、模型,甚至把查询语言SQL也琢磨了出来。
但当时的“蓝色巨人”,沉浸在大型计算机巨大的商业成功里,对数据库软件兴趣寥寥。
结果,“硅谷大忽悠”拉里·埃里森,抓住了逆天改命的机会。

他认真研究了科德的论文,觉得极富商业价值,并在1977年创立了数据库公司甲骨文(Oracle)。早期的Oracle相当不靠谱,但在埃里森的巧舌如簧下,美国海军、中情局、国家航天局等一帮“冤大头”,依然为Oracle买了单。

▲1977年中国第一届数据库年会
彼时,神州大地万物复苏,中国计算机学会敏锐把握到了科技的脉搏,在黄山召开了第一届数据库年会。
可惜的是,这个时代中国的数据库技术,始终囿于高校和科研机构里。
但拿到“第一桶金”的甲骨文,很快走上了正轨。
80年代,美国数据库市场迎来井喷,甲骨文的Oracle、IBM的DB2、微软的SQLServer等,如雨后春笋般冒了出来。
产业的风口,让甲骨文迎来了发展的春天。它不但创造了连续12 年销售翻番的奇迹,成长为全球第二大软件公司;连埃里森本人也一度问鼎“硅谷首富”,与比尔·盖茨不相伯仲。
不过1996年,诞生在瑞典的免费数据库MySQL,给巨头们带来了一丝挑战。但在霸主甲骨文坚持不懈的猎杀下,2009年MySQL也臣服在甲骨文麾下。
美国的数据库产业在高歌猛进,中国的数据库技术却尘封在象牙塔里。结果90年代,当甲骨文们来到中国,基本是大杀四方的状态。
1995年,邮电部提出“九七工程”,使得国内第一批数据库企业有了发展的土壤,在少数大学和国家机关得到应用。
但最终,还是甲骨文乘着工程的东风,接连拿下东北邮电、中国电信等超级大单。
至此,中国的金融、电信、航空等领域,逐渐被“IOE”(即IBM的小型机、Oracle的数据库、EMC的存储设备)横扫。
据全国人大代表、合肥工业大学应用数学所所长檀结庆调研统计,2020年之前,甲骨文、IBM、微软等巨头把持了87.7%的全球份额,处于绝对垄断地位。
关系型数据库统治全球40余年,成就了甲骨文们的黄金时代。
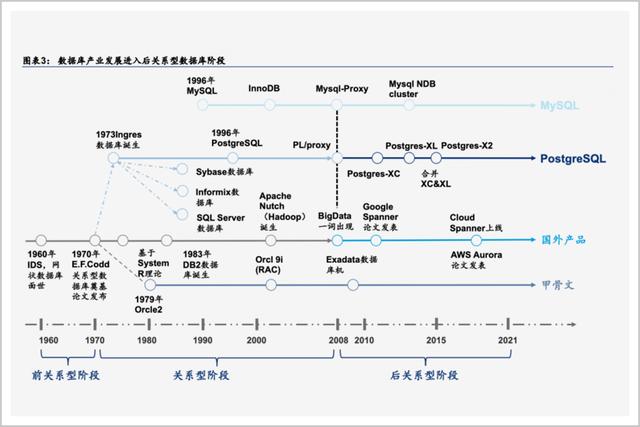
但2008年,时代的洪流突然急转,NoSQL(非关系型数据库)诞生了。
驱动这场变革的,是亚马逊、阿里等互联网电商的崛起。
2009年,淘宝跃升为Oracle全球居前的超级应用集群。但集群的CPU跑得冒了烟,依然抵挡不住“双十一”的超级洪流。
与此同时,通信技术不断向3G、4G、5G演进,让图片、语音、视频等非结构化数据,呈现指数级规模的暴涨。
战无不胜的Oracle,怎么就扛不住了?这来自于关系型数据库和非关系型数据库的区别。
我们可以把关系型数据库,看成一家“火锅店”。在Oracle支持下,它每天能招待1000位客人,很不错了。
但现在,店里突然涌进了1000万客人。他们不但要吃火锅,还要泡温泉、做美甲、放烟花、坐过山车……
在天量的、爆发式增长的非结构化数据面前,传统的关系型数据库的天花板被冲破了。
“火锅店”,必须升级成云端的超级“游乐场”。
于是,一场由关系型向非关系型、由集中式向分布式转型的数据库革命,爆发了!
在分布式数据库的世界里,数据库不会再集中于单机或一地,而会将查询、存储、事务管理等核心功能,扩展到多机或多地。
于是,200万人在A区吃火锅,300万人在B区泡温泉,400万人在C区做美甲……
另外,云计算还能通过存算分离、弹性分配等手段,打破资源瓶颈,让分布式数据库自由伸缩、无限扩展。
也就是说,哪怕“游乐场”突然闯进1亿人,分布式数据库“遇强更强”,照样能铺开。
这是传统的关系型数据库,根本无法比拟的。
因此在Gartner看来,云化、分布式数据库将主导未来,引领数据库技术的新趋势。预计2023年,75%的数据库会运行在云端;2024 年,全球数据库市场规模突破千亿美元,分布式数据库将成为最主要的市场增量。
如今,再造一个Oracle,做不到也没必要。云化、分布式数据库,成为中国数据库“换道超车”的唯一机会。
【率先破局的关键技术 造就数据库断代史】
机会永远属于敢于破局的人。
2022年4月,中国邮政储蓄银行(以下简称“邮储银行”)的新一代个人业务分布式核心系统成功上线。
这一出手,就建成了全球最大的银行分布式新核心系统。其中,华为云GaussDB功不可没。
众所周知,核心系统是银行的“大脑”和“心脏”,不但承担至关重要的任务,而且在亿万次存储、计算中不容丝毫闪失。
以往,这是只有Oracle才能染指的“禁区”。
邮储银行的老核心系统,使用的正是关系型、集中式Oracle数据库。但伴随金融服务在线化,交易频次越来越高,容量瓶颈、性能支撑、业务负载的挑战越来越大。一旦碰到交易高峰,系统资源缺乏弹性,拥堵成了家常便饭,严重影响用户体验。
如今,以华为云GaussDB等为代表的中国分布式数据库打破了这个“铁律”。
新系统上线后,邮储银行一举实现日均20亿笔、峰值6.7万笔/秒的超强交易处理能力。即便面对6.5亿客户、4万多个网点的数据冲击,依然游刃有余。
全天联机平均耗时从93毫秒减少到65毫秒,批处理时间从4.5小时缩短到3小时,较老核心系统提升30%以上性能。
2022年三季度,邮储银行迎来结息大考。过去耗时140分钟的任务,新核心系统仅用25分钟完成,性能、效率大幅提升,充分验证了中国数据库在安全可控上的承载能力。
实际上,在海量数据、任务并发的情况下,要实现数据处理“不出错”,是一件非常非常困难的事情。
这就像在1000万人涌动的“游乐场”里,要求游客不踩掉鞋、不走丢人、不传错菜。
听起来,这是一个几乎不可能完成的任务。
但在银行、电信、电力、航空等系统中,就是苛求“不出错”、“稳定压倒一切”。
华为云GaussDB做到了。

2022年,中国首个数据库行业最高安全认证-国际CC EAL4+,花落GaussDB;同年,高分通过北京国家金融科技认证中心的“分布式数据库金融标准验证”测试。
与此同时,GaussDB再次通过中国信通院防篡改、智能化、分布式事务基础能力三大专项严苛评测。
所谓防篡改,就是在极端情况下,数据库依然要具备识别风险、防止篡改、备份还原的能力。
所谓智能化,就是数据库不但要提供智能运维,而且通过趋势预测算法,帮管理者智能决策、推理预警,让系统更加安全可靠。
所谓分布式事务型数据库基础能力,就是一旦出现大规模数据需求,数据库要能迅速反应,就近调集分布式的CPU、内存、存储等系统资源,高效处理海量数据的能力。
如此强悍实力的背后,则是华为云GaussDB在全球范围内累计获得的700多件专利,在提供有力的支撑。
即便在数据库综合要求最严苛的金融业,GaussDB在包括工商银行、邮储银行、建设银行、华夏银行等规模落地,以及拥有永安保险、甘肃医保、一汽集团等重点行业客户。
华为云GaussDB的崛起,同步带动了中国自研数据库影响力的提升。
IDC发布的《2021年上半年中国关系型数据库软件市场跟踪报告》显示,在传统部署模式市场中,华为、阿里、达梦、人大金仓的市占率,分别为14.7%、5.7%、5.7%、5.0%。
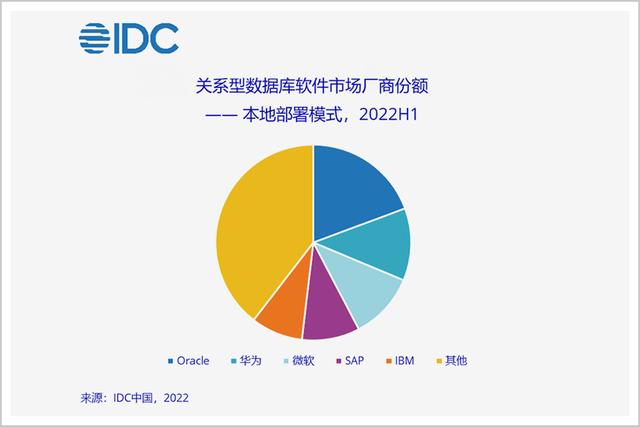
在IDC最新发布的《2022年上半年中国关系型数据库软件市场跟踪报告》中,在本地部署模式市场中,华为云数据库凭借GaussDB以16.59%的份额排名国内第一。自2020H1以来,GaussDB已经连续五次蝉联第一,在国内关系型数据库市场持续领跑。
今天,中国的分布式数据库正趋于成熟,获得市场认可。只要假以时日,就有望在时代的大潮中崛起。
【积于跬步,方能行至千里】
数字时代的蓬勃发展,也将中国的分布式数据库不断推向前台。
IDC数据显示,全球每年的数据量呈现爆发式增长,预计从2018年的33ZB增至2025年的175ZB。
中国的数据量增速更领跑全球,预计从2018 年的7.6ZB猛增至2025年的48.6ZB。
数据的计算载体,早就从大型机、小型机、PC,演变成云、边、端的联网计算,高并发、低时延的交互计算。
面对这样的未来,华为云GaussDB早有准备。
比如,大部分云数据库,只能在数据的传输态、存储态中进行加密。
而华为云GaussDB却实现在内存中的运算态加密,从而成为业界第一款纯软全密态的数据库,实现了对数据全生命周期的完整保护。
另外,在原生分布式数据库领域,中国数据库也更顺应企业的诉求和发展的趋势。
比如有的互联网企业,坐拥海量数据,极易患上数据库性能不足“恐惧症”。
但华为云GaussDB,直接打通了软硬件“任督二脉”,将数据库性能发挥到极致。
硬件上,GaussDB拥有鲲鹏处理器的多线程、原子指令、SCM的字节寻址持久化等能力;软件上,又实现了动态编译、SQL By Pass等。
于是,基于鲲鹏两路服务器,GaussDB 32节点处理能力达到了惊人的1500万tpmC(即每分钟系统处理新订单个数),百亿数据量查询“秒级响应”。
有的企业,依然对数据迁移心存顾虑,担心到最后才发现数据库不合适。
对此,GaussDB开发出一系列强悍的迁移工具。如数据库迁移工具UGO,实现了异构数据库对象和应用迁移,语法转化率达90%以上;数据在线迁移工具DRS,可实现数据的在线迁移、数据校验。
此外,由于是“自己人”,GaussDB完全能够为企业量身打造“数据库架构+应用+数据”一体化的迁移方案。
这才是以华为云GaussDB为代表的中国数据库真正的机遇所在。
而伴随大国崛起,国人对中国数据库更应该抱有一种开阔、包容、自信的气度。
因为历史证明,好数据库是用出来的。
1978年,Oracle在美国第二次石油危机引发的“滞胀”下诞生,草创之初Bug频出、骂声一片。美国海军、CIA、NASA硬是顶着“被骗”的压力,让Oracle闯过了生死关。
此后,又经过全球用户40多年不断的实践、反馈、打磨、培训,Oracle才拥有了成熟、稳定的口碑。
显然,中国数据库不可能一夜成熟,也必然要经历漫长打磨的过程。但只要今天播下宽容、创新的种,对襁褓中的中国数据库多采购、多使用、多呵护,明天才能收获卓越、成熟的果。
积于跬步,方能行至千里。
在新一轮科技革命的大潮中,这条漫漫长路显然才刚刚开始。
——END——
欢迎关注【华商韬略】,识风云人物,读韬略传奇。
版权所有,禁止私自转载
部分图片来源于网络
如涉及侵权,请联系删除
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号