王兴兴等专家共探具身前沿技术,未来趋势展望!
发表时间: 2024-06-19 14:42
清华大学助理教授,视觉与具身智能实验室主任高阳认为成本是阻碍的重要因素:“机器人本体的高成本是限制仿生人工智能发展的主要瓶颈之一。”
宇树科技创始人&CEO王兴兴认为目前训练数据不够多维,限制了具身智能的发展,他表示:如果结合实际操作中的真实数据进行强化学习,效果会更好。
NUS助理教授邵林也对数据的重要性表示认同:核心问题在于如何定义和处理数据,实现最高效和实用的解决方案,关键是对数据的理解和有效利用。
同时学者们对未来发展也有独到的见解,例如北京大学副教授,智源学者卢宗青认为“机器人触觉”至关重要:如果没有触觉,就像是在玩一场虚拟游戏,而不是与真实世界进行交互。
北京大学助理教授,智源学者王鹤表示“模块化系统”或许是关键:即使在工厂这种复杂环境中,只要设计一个良好的模块化系统,也可以实现sim-to-real的无缝转换。
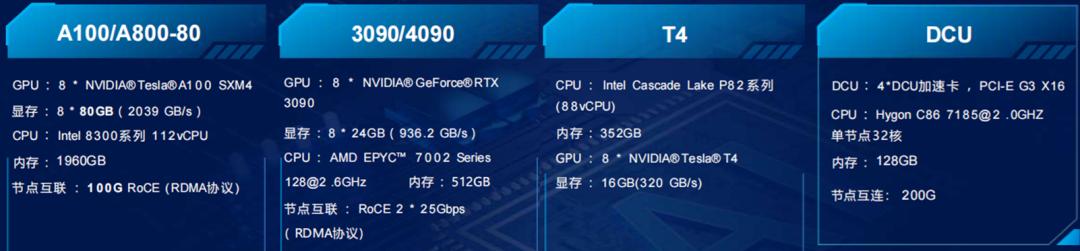
......









声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12



 鲁公网安备37020202000738号
鲁公网安备37020202000738号