深入解析MySQL的WAL技术:日志先行,磁盘随后
发表时间: 2019-07-16 00:01
今天主要说说mysql数据库的WAL机制,WAL 的全称是 Write-Ahead Logging,它的关键点是,先写日志,再写磁盘。
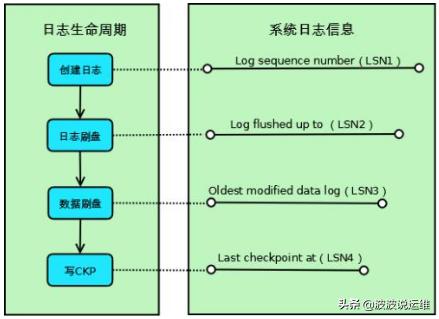
用户如果对数据库中的数据就行了修改,必须保证日志先于数据落盘。当日志落盘后,就可以给用户返回操作成功,并不需要保证当时对数据的修改也落盘。如果数据库在日志落盘前crash,那么相应的数据修改会回滚。在日志落盘后crash,会保证相应的修改不丢失。有一点要注意,虽然日志落盘后,就可以给用户返回操作成功,但是由于落盘和返回成功包之间有一个微小的时间差,所以即使用户没有收到成功消息,修改也可能已经成功了,这个时候就需要用户在数据库恢复后,通过再次查询来确定当前的状态。 在日志先行技术之前,数据库只需要把修改的数据刷回磁盘即可,用了这项技术,除了修改的数据,还需要多写一份日志,也就是磁盘写入量反而增大,但是由于日志是顺序的且往往先存在内存里然后批量往磁盘刷新,相比数据的离散写入,日志的写入开销比较小。 日志先行技术有两个问题需要工程上解决:
1、日志刷盘问题。由于所有对数据的修改都需要写日志,当并发量很大的时候,必然会导致日志的写入量也很大,为了性能考虑,往往需要先写到一个日志缓冲区,然后在按照一定规则刷入磁盘,此外日志缓冲区大小有限,用户会源源不断的生产日志,数据库还需要不断的把缓存区中的日志刷入磁盘,缓存区才可以复用,因此,这里就构成了一个典型的生产者和消费者模型。现代数据库必须直面这个问题,在高并发的情况下,这一定是个性能瓶颈,也一定是个锁冲突的热点。
2、数据刷盘问题。在用户收到操作成功的时候,用户的数据不一定已经被持久化了,很有可能修改还没有落盘,这就需要数据库有一套刷数据的机制,专业术语叫做刷脏页算法。脏页(内存中被修改的但是还没落盘的数据页)在源源不断的产生,然后要持续的刷入磁盘,这里又凑成一个生产者消费者模型,影响数据库的性能。如果在脏页没被刷入磁盘,但是数据库异常crash了,这个就需要做崩溃恢复,具体的流程是,在接受用户请求之前,从checkpoint点(这个点之前的日志对应的数据页一定已经持久化到磁盘了)开始扫描日志,然后应用日志,从而把在内存中丢失的更新找回来,最后重新刷入磁盘。这里有一个很重要的点:在数据库正常启动的期间,checkpoint怎么确定,如果checkpoint做的慢了,就会导致奔溃恢复时间过长,从而影响数据库可用性,如果做的快了,会导致刷脏压力过大,甚至数据丢失。
MySQL中为了解决上述两个问题,采用了以下机制:
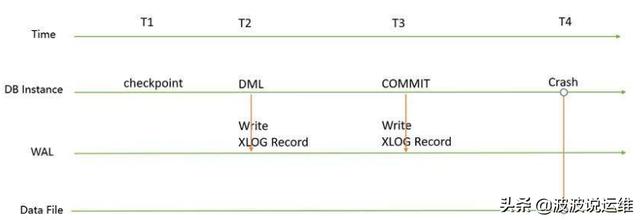
当用户线程产生日志的时候,首先缓存在一个线程私有的变量(mtr)里面,只有完成某些原子操作(例如完成索引分裂或者合并等)的时候,才把日志提交到全局的日志缓存区中。全局缓存区的大小(innodb_log_file_size)可以动态配置。当线程的事务执行完后,会按照当前的配置(
innodb_flush_log_at_trx_commit)决定是否需要把日志从缓冲区刷到磁盘。
当把日志成功拷贝到全局日志缓冲区后,会继续把当前已经被修改过的脏页加入到一个全局的脏页链表中。这个链表有一个特性:按照最早被修改的时间排序。
例如,有数据页A,B,C,数据页A早上9点被第一次修改,数据页B早上9点01分被第一次修改,数据页C早上9点02分被第一次修改,那么在这个链表上数据页A在最前,B在中间,C在最后。即使数据页A在早上9点之后又一次被修改了,他依然排在B和C之前。在数据页上,有一个字段来记录这个最早被修改的时间:oldest_modification,只不过单位不是时间,而是lsn,即从数据库初始化开始,一共写了多少个字节的日志,由于其是一个递增的值,因此可以理解为广义的时间,先写的数据,其产生的日志对应的lsn一定比后写的小。在脏页列表上的数据页,就是按照oldest_modification从小到大排序,刷脏页的时候,就从oldest_modification小的地方开始。
checkpoint就是脏页列表中最小的那个oldest_modification,因为这种机制保证小于最小oldest_modification的修改都已经刷入磁盘了。这里最重要的是,脏页链表的有序性,假设这个有序性被打破了,如果数据库异常crash,就会导致数据丢失。例如,数据页ABC的oldest_modification分别为120,100,150,同时在脏页链表上的顺序依然为A,B,C,A在最前面,C在最后面。数据页A被刷入磁盘,然后checkpoint被更新为120,但是数据页B和C都还没被刷入磁盘,这个时候,数据库crash,重启后,从checkpoint为120开始扫描日志,然后恢复数据,我们会发现,数据页C的修改被恢复了,但是数据页B的修改丢失了。
WAL的机制在redo log的使用场景,充分展现。
具体说来,当执行一条sql时,过程如下:
Redo log 的示意图如下
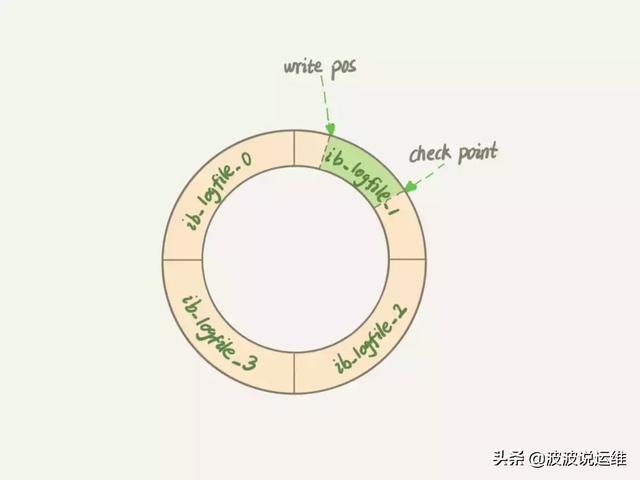
redo log示意图
说明:
write pos 是当前记录的位置
checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件
write pos和checkpoint之间空着的部分,可以用来记录新的操作。如果write pos追上checkpoint,这时候就不能在执行新的更新。得停下来擦掉一些记录,把checkpoint前进一下。
有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe。
后面会分享更多devops和DBA方面的内容,感兴趣的朋友可以关注下!

声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号