视频编解码理论:音视频开发的基础知识解析
发表时间: 2022-09-23 21:41
**像素是图像的基本单元,一个个像素就组成了图像。你可以认为像素就是图像中的一个点。**在下面这张图中,你可以看到一个个方块,这些方块就是像素。

图像(或视频)的分辨率是指图像的大小或尺寸。我们一般用像素个数来表示图像的尺寸。比如说一张1920x1080的图像,前者1920指的是该图像的宽度方向上有1920个像素点,而后者1080指的是图像的高 度方向上有1080个像素点。
一般来说,我们看到的彩色图像中,都有三个通道,这三个通道就是R、G、B通道,(有的时候还会有Alpha值,代表透明度) 通常R、G、B各占8个位,我们称这种图像是8bit图像。
对于图像显示器来说,它是通过RGB模型来显示图像的。而在传输图像数据时是使用YUV模型的,因为YUV模型可以节省带宽。所以就需要采集图像时将RGB模型转换到YUV模型,显示时再将YUV模型转换为RGB模型。
从视频采集与处理的角度来说,一般的视频采集芯片输出的码流一般都是YUV数据流的形式,而从视频处理(例如H.264、MPEG视频编解码)的角度来说,也是在原始YUV码流进行编码和解析 ;如果采集的资源时RGB的,也需要转换成YUV。
使用YUV而非RGB的两个原因: 1)yuv提取y亮度信号,可以直接给黑白电视使用,兼容黑白电视 2)人对uv的敏感性小于亮度,这样我们适当减少uv的量,进行视频的压缩。所以才会有420 422 444等不同的yuv描述
YUV 颜色编码采用的是 明亮度 和 色度 来指定像素的颜色。 其中,Y 表示明亮度(Luminance、Luma),而 U 和 V 表示色度(Chrominance、Chroma)。 YUV主要分为YUV 4:4:4,YUV 4:2:2,YUV 4:2:0几种常用类型。
YUV格式有两大类:planar和packed。对于planar的YUV格式,先连续存储所有像素点的Y,紧接着存储所有像素点的U,随后是所有像素点的V。对于packed的YUV格式,每个像素点的Y,U,V是连续交叉存储的。
【相关学习资料推荐,点击下方链接免费报名,免费报名后即可领到学习资料~】
【免费】
FFmpeg/WebRTC/RTMP/NDK/Android音视频流媒体高级开发-学习视频教程-腾讯课堂
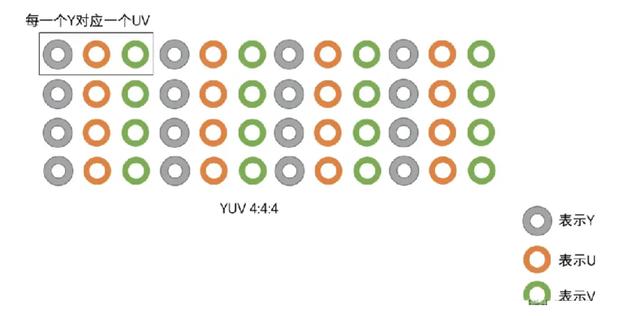

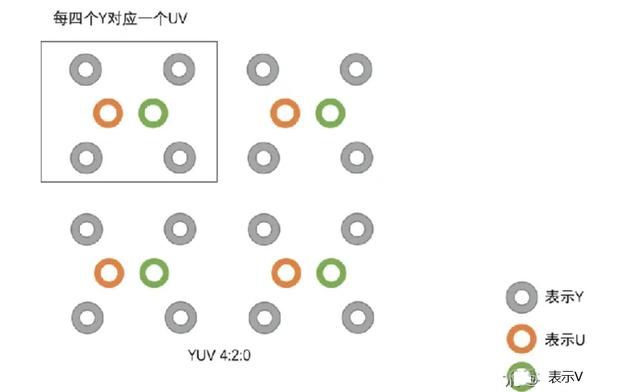
1.YUV 4:4:4, 每一个Y对应一组UV。 2.YUV 4:2:2,每两个Y共用一组UV。 3.YUV 4:2:0,每四个Y共用一组UV。
YUV 4:4:4采样 意味着Y、U、V三个分量的采样比例相同,所以在生成的图像里,每个像素的三个分量信息都是8bit。
举个例子 :假如图像像素为:[Y0 U0 V0]、[Y1 U1 V1]、[Y2 U2 V2]、[Y3 U3 V3]那么采样的码流为:Y0 U0 V0 Y1 U1 V1 Y2 U2 V2 Y3 U3 V3最后映射出的像素点依旧为 [Y0 U0 V0]、[Y1 U1 V1]、[Y2 U2 V2]、[Y3 U3 V3]这种采样方式的图像和 RGB 颜色模型的图像大小是一样,并没有达到节省带宽的目的
YUV 4:2:2采样 UV分量是Y分量的一般,Y分量和UV分量按照2:1的比例采样,如果水平方向有10个像素点,那么采样了10个Y分量,就只采样了5个UV分量。
举个例子 :假如图像像素为:[Y0 U0 V0]、[Y1 U1 V1]、[Y2 U2 V2]、[Y3 U3 V3]那么采样的码流为:Y0 U0 Y1 V1 Y2 U2 Y3 V3 其中,每采样过一个像素点,都会采样其 Y 分量,而 U、V 分量就会间隔一个采集一个。最后映射出的像素点为 [Y0 U0 V1]、[Y1 U0 V1]、[Y2 U2 V3]、[Y3 U2 V3]通过这个例子就可以发现第一个像素点和第二个像素点共用了[U0、V1]分量,第三个像素点和第四个像素点共用了[U2、V3]分量,这样就节省了图像空间。比如一张1280*720大小的图片,如果按照RGB方式存储,会耗费:
(1280∗720∗8+1280∗720∗8+1280∗720∗8)、8/1024/1024=2.637 其中1280*720是表示有多少个像素点。但如果采用了YUV4:2:采样格式:
(1280∗720∗8+1280∗720∗0.5∗8∗2)/8/1024/1024=1.76 节省了1/3的存储空间,适合进行图像传输。
YUV 4:2:0采样 YUV 4:2:0 采样,并不是指只采样 U 分量而不采样 V 分量。而是指,在每一行扫描时,只扫描一种色度分量(U 或者 V),和 Y 分量按照 2 : 1 的方式采样。比如,第一行扫描时,YU 按照 2 : 1 的方式采样,那么第二行扫描时,YV 分量按照 2:1 的方式采样。对于每个色度分量来说,它的水平方向和竖直方向的采样和 Y 分量相比都是 2:1 。
举个例子 :假设图像像素为:[Y0 U0 V0]、[Y1 U1 V1]、 [Y2 U2 V2]、 [Y3 U3 V3][Y4 U4 V4]、[Y5 U5 V5]、[Y6 U6 V6]、 [Y7 U7 V7]那么采样的码流为:Y0 U0 Y1 Y2 U2 Y3 Y4 V4 Y5 Y6 V6 Y7其中,每采样过一个像素点,都会采样其 Y 分量,而 U、V 分量就会间隔一行按照 2 : 1 进行采样。最后映射出的像素点为:[Y0 U0 V5]、[Y1 U0 V5]、[Y2 U2 V7]、[Y3 U2 V7][Y5 U0 V5]、[Y6 U0 V5]、[Y7 U2 V7]、[Y8 U2 V7]通过YUV 4:2:0采样后的图片大小为: (1280∗720∗8+1280∗720∗0.25∗8∗2)/8/1024/1024=1.32 采样的图像比RGB模型图像节省了一半的存储空间,因此也是比较主流的采样方式。
大量的图像连续起来,就是视频。

衡量视频,又是用的什么指标参数呢?最主要的一个,就是帧率(Frame Rate)。在视频中,一个帧(Frame)就是指一幅静止的画面。帧率,就是指视频每秒钟包括的画面数量(FPS,Frame per second)。
有了视频之后,就涉及到两个问题: 一个是存储; 二个是传输。
未经编码的视频,它的体积是非常庞大的。 以一个分辨率1920×1280,30FPS的视频为例: 共:1920×1280=2,073,600(Pixels 像素),每个像素点是24bit(前面算过的哦); 也就是:每幅图片2073600×24=49766400 bit,8 bit(位)=1 byte(字节); 所以:49766400bit=6220800byte≈6.22MB。 这是一幅1920×1280图片的原始大小,再乘以帧率30。
也就是说:每秒视频的大小是186.6MB,每分钟大约是11GB,一部90分钟的电影,约是1000GB
显然如此大的体积需要压缩,于是编码就产生了。
编码:就是按指定的方法,将信息从一种形式(格式),转换成另一种形式(格式)。视频编码:就是将一种视频格式,转换成另一种视频格式。
编码的终极目的,就是为了压缩。各种视频编码方式,都是为了让视频变得体积更小,有利于存储和传输。 要实现压缩,就要设计各种算法,将视频数据中的冗余信息去除。
当你面对一张图片,或者一段视频的时候,如果是你,你会如何进行压缩呢? 我觉得,首先你想到的,应该是找规律。是的,寻找像素之间的相关性,还有不同时间的图像帧之间,它们的相关性。
举个例子:如果一幅图(1920×1080分辨率),全是红色的,我有没有必要说2073600次[255,0,0]?我只要说一次[255,0,0],然后再说2073599次“同上”。
如果一段1分钟的视频,有十几秒画面是不动的,或者,有80%的图像面积,整个过程都是不变(不动)的。那么,是不是这块存储开销,就可以节约掉了?

图像一般都是有数据冗余的,主要包括以下4种: **空间冗余。**比如说将一帧图像划分成一个个16x16的块之后,相邻的块很多时候都有比较明显的相似性, 这种就叫空间冗余。 **时间冗余。**一个帧率为25fps的视频中前后两帧图像相差只有40ms,两张图像的变化是比较小的,相似性很高,这种叫做时间冗余。 视觉冗余。我们的眼睛是有视觉灵敏度这个东西的。人的眼睛对于图像中高频信息的敏感度是小于低频信息的。有的时候去除图像中的一些高频信息,人眼看起来跟不去除高频信息差别不大,这种叫做视觉冗余。 **信息炳冗余。**我们一般会使用Zip等压缩工具去压缩文件,将文件大小减小,这个对于图像来说也是可以 做的,这种冗余叫做信息嫡冗余。
【相关学习资料推荐,点击下方链接免费报名,免费报名后即可领到学习资料~】
【免费】
FFmpeg/WebRTC/RTMP/NDK/Android音视频流媒体高级开发-学习视频教程-腾讯课堂
各种视频压缩算法就是为了减少上面的这几种冗余。视频编码技术优先消除的目标,就是空间冗余和时间冗余。
每一帧图像,又是划分成一个个块来进行编码的,这一个个块在H264中叫做宏块,而在VP9、AV1 中称之为超级块,其实概念是一样的。宏块大小一般是16x16 (H264、VP8) , 32x32 (H265、VP9), 64x64 (H265、VP9、AV1) , 128x128 (AV1)这几种。这里提到的H264、H265、VP8、VP9和AV1都是市面上常见的编码标准。

帧内预测——基于同一帧内已编码块预测,构造预测块,计算与当前块的残差,对残差、预测模式等信息进行编码。其主要去除的是空间冗余。
帧间预测——基于一个或多个已编码帧预测,构造预测块,计算与当前块的残差,对残差、预测模式、运动矢量残差、参考图像索引等信息进行编码。其主要去除的是时间冗余。
帧间预测需要参考已经编码的帧,帧间编码帧可以分为只参考前面帧的前向编码帧和前后都可以参考的双向编码帧
I帧:是自带全部信息的独立帧,是最完整的画面(占用的空间最大),无需参考其它图像便可独立进行解码。视频序列中的第一个帧,始终都是I帧。
P帧:“帧间预测编码帧”,需要参考前面的I帧和/或P帧的不同部分,才能进行编码。P帧对前面的P和I参考帧有依赖性。但是,P帧压缩率比较高,占用的空间较小。
B帧:“双向预测编码帧”,以前帧后帧作为参考帧。不仅参考前面,还参考后面的帧,所以,它的压缩率最高,可以达到200:1。
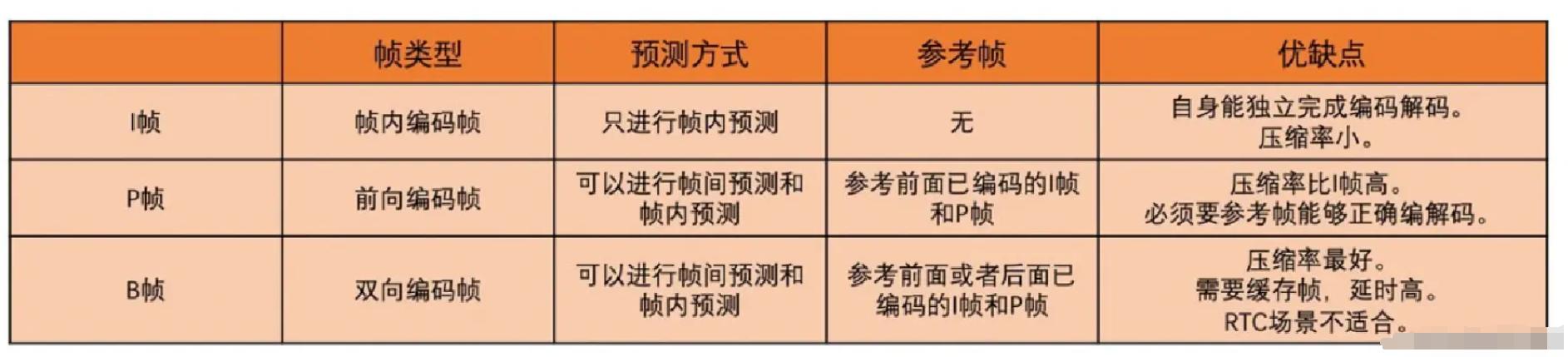
如图,箭头是从参考帧指向编码帧

在H264中图像以序列为单位进行组织,一个序列是一段图像编码后的数据流。 一个序列的第一个图像叫做 IDR 图像(立即刷新图像),IDR 图像都是 I 帧图像。H.264 引入 IDR 图像是为了解码的重同步,当解码器解码到 IDR 图像时,立即将参考帧队列清空,将已解码的数据全部输出或抛弃,重新查找参数集,开始一个新的序列。这样,如果前一个序列出现重大错误,在这里可以获得重新同步的机会。IDR图像之后的图像永远不会使用IDR之前的图像的数据来解码。
一个序列就是一段内容差异不太大的图像编码后生成的一串数据流。当运动变化比较少时,一个序列可以很长,因为运动变化少就代表图像画面的内容变动很小,所以就可以编一个I帧,然后一直P帧、B帧了。当运动变化多时,可能一个序列就比较短了,比如就包含一个I帧和3、4个P帧。 在视频编码序列中,GOP即Group of picture(图像组),指两个I帧之间的距离,Reference(参考周期)指两个P帧之间的距离。两个I帧之间形成一组图片,就是GOP(Group Of Picture)。

为什么会有PTS和DTS的概念?
P帧需要参考前面的I帧或P帧才可以生成一张完整的图片,而B帧则需要参考前面I帧或P帧及其后面的一个P帧才可以生成一张完整的图片。这样就带来了一个问题:在视频流中,先到来的 B 帧无法立即解码,需要等待它依赖的后面的 I、P 帧先解码完成,这样一来播放时间与解码时间不一致了,顺序打乱了,那这些帧该如何播放呢?这时就引入了另外两个概念:DTS 和 PTS。
DTS(Decoding Time Stamp):即解码时间戳,这个时间戳的意义在于告诉播放器该在什么时候解码这一帧的数据。 PTS(Presentation Time Stamp):即显示时间戳,这个时间戳用来告诉播放器该在什么时候显示这一帧的数据。
在视频采集的时候是录制一帧就编码一帧发送一帧的,在编码的时候会生成 PTS,这里需要特别注意的是 frame(帧)的编码方式,在通常的场景中,编解码器编码一个 I 帧,然后向后跳过几个帧,用编码 I 帧作为基准帧对一个未来 P 帧进行编码,然后跳回到 I 帧之后的下一个帧。编码的 I 帧和 P 帧之间的帧被编码为 B 帧。之后,编码器会再次跳过几个帧,使用第一个 P 帧作为基准帧编码另外一个 P 帧,然后再次跳回,用 B 帧填充显示序列中的空隙。这个过程不断继续,每 12 到 15 个 P 帧和 B 帧内插入一个新的 I 帧。P 帧由前一个 I 帧或 P 帧图像来预测,而 B 帧由前后的两个 P 帧或一个 I 帧和一个 P 帧来预测,因而编解码和帧的显示顺序有所不同,如下所示:

假设编码器采集到的帧是这个样子的:
I B B P B B P 那么它的显示顺序,也就是PTS应该是这样:
1 2 3 4 5 6 7编码器的编码顺序是:
1 4 2 3 7 5 6推流顺序也是按照编码顺序去推的,即
I P B B P B B那么接收断收到的视频流也就是:
I P B B P B B这时候去解码,也是按照收到的视频流一帧一帧去解的了,接收一帧解码一帧,因为在编码的时候已经按照 I、B、P 的依赖关系编好了,接收到数据直接解码就好了。那么解码顺序是:
I P B B P B BDTS:1 2 3 4 5 6 7PTS:1 4 2 3 7 5 6可以看到解码出来对应的 PTS 不是顺序的,为了正确显示视频流,这时候我们就必须按照 PTS 重新调整解码后的 frame(帧),即
I B B P B B PDTS:1 3 4 2 6 7 5PTS:1 2 3 4 5 6 7如果你对音视频开发感兴趣,觉得文章对您有帮助,别忘了点赞、收藏哦!或者对本文的一些阐述有自己的看法,有任何问题,欢迎在下方评论区与我讨论!
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号