Node.js应用故障排查手册:深度解析GC问题与优化策略
发表时间: 2019-04-09 13:01
本章前面两节生产案例分别侧重于单一的 CPU 高和单一的内存问题,我们也给大家详细展示了问题的定位排查过程,那么实际上还有一类相对更复杂的场景——它本质上是 V8 引擎的 GC 引发的问题。
简单的给大家介绍下什么是 GC,GC 实际上是语言引擎实现的一种自动垃圾回收机制,它会在设定的条件触发时(比如堆内存达到一定值)时查看当前堆上哪些对象已经不再使用,并且将这些没有再使用到的对象所占据的空间释放出来。许多的现代高级语言都实现了这一机制,来减轻程序员的心智负担。
本书首发在 Github,仓库地址:https://github.com/aliyun-node/Node.js-Troubleshooting-Guide,云栖社区会同步更新。
虽然上面介绍中现代语言的 GC 机制解放了程序员间接提升了开发效率,但是万事万物都存在利弊,底层的引擎引入 GC 后程序员无需再关注对象何时释放的问题,那么相对来说程序员也就没办法实现对自己编写的程序的精准控制,它带来两大问题:
内存泄漏问题我们已经在上一节的生产案例中体验了一下,那么后者是怎么回事呢?
其实理解起来也很简单:原本一个程序全部的工作都是执行业务逻辑,但是存在了 GC 机制后,程序总会在一定的条件下耗费时间在扫描堆空间找出不再使用的对象上,这样就变相降低了程序执行业务逻辑的时间,从而造成了性能的下降,而且降低的性能和耗费在 GC 上的时间,换言之即 GC 的次数 * 每次 GC 耗费的时间成正比。
现在大家应该对 GC 有了一个比较整体的了解,这里我们可以看下 GC 引发的问题在生产中的表现是什么样的。在这个案例中,表象首先是 Node.js 性能平台 上监控到进程的 CPU 达到 100%,但是此时服务器负载其实并不大,QPS 只有 100 上下,我们按照前面提到的处理 CPU 问题的步骤抓取 CPU Profile 进行分析可以看到:
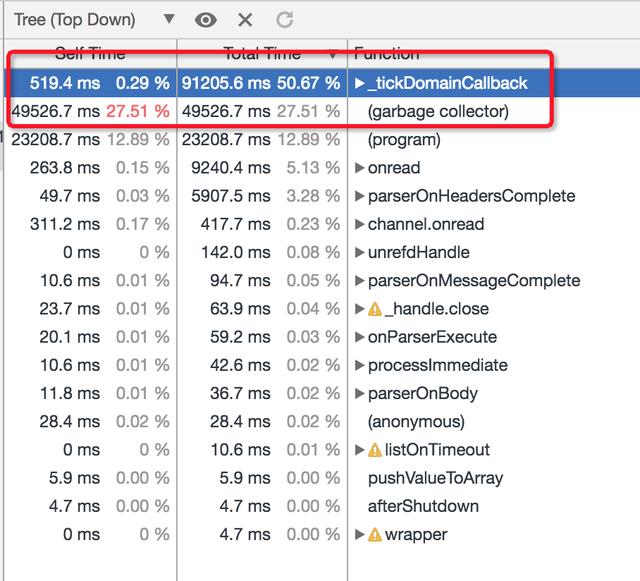
这次的问题显然是 Garbage Collector 耗费的 CPU 太多了,也就是 GC 的问题。实际上绝大部分的 GC 机制引发的问题往往表象都是反映在 Node.js 进程的 CPU 上,而本质上这类问题可以认为是引擎的 GC 引起的问题,也可以理解为内存问题,我们看下这类问题的产生流程:
而且 GC 问题不像之前的 ejs 模板渲染引发的问题,就算我们在 CPU Profile 中可以看到这部分的耗费,但是想要优化解决这个问题基本是无从下手的,幸运的是 Node.js 提供了(其实是 V8 引擎提供的)一系列的启动 Flag 能够输出进程触发 GC 动作时的相关日志以供开发者进行分析:
加粗的 Flag 意味着我们需要在启动应用前加上才能在运行时生效,这部分的日志实际上是一个文本格式,可惜的是 Chrome devtools 原生并不支持 GC 日志的解析和结果展示,因此需要大家获取到以后进行对应的按行解析处理,当然我们也可以使用社区提供 v8-gc-log-parser 这个模块直接进行解析处理,对这一块有兴趣的同学可以看 @joyeeCheung 在 JS Interactive 的分享: Are Your V8 Garbage Collection Logs Speaking To You?,这里不详细展开。
虽然 Chrome devtools 并不能直接帮助我们解析展示 GC 日志的结果,但是 Node.js 性能平台 其实给大家提供了更方便的动态获取线上运行进程的 GC 状态信息以及对应的结果展示,换言之,开发者无需在运行你的 Node.js 应用前开启上面提到的那些 Flag 而仍然可以在想要获取到 GC 信息时通过控制台拿到 3 分钟内的 GC 数据。
对应在这个案例中,我们可以进入平台的应用实例详情页面,找到 GC 耗费特别大的进程,然后点击 GC Trace 抓取 GC 数据:
这里默认会抓取 3 分钟的对应进程的 GC 日志信息,等到结束后生成的文件会显示在 文件 页面:

此时点击 转储 即可上传到云端以供在线分析展示了,如下图所示:

最后点击这里的 分析 按钮,即可看到 AliNode 定制后的 GC 信息分析结果的展现:
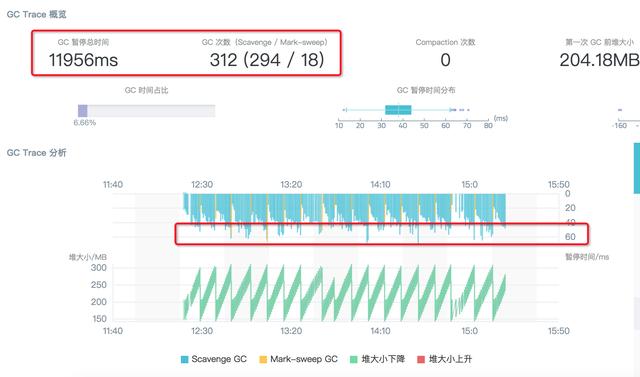
结果展示中,可以比较方便的看到问题进程的 GC 具体次数,GC 类型以及每次 GC 的耗费时间等信息,方便我们进一步的分析定位。比如这次问题的 GC Trace 结果分析图中,我们可以看到红圈起来的几个重要信息:
从这些解困中我们可以看到此次 GC 案例的问题点集中在 Scavenge 回收阶段,即新生代的内存回收。那么通过翻阅 V8 的 Scavenge 回收逻辑可以知道,这个阶段触发回收的条件是:Semi space allocation failed。
这样就可以推测,我们的应用在压测期间应该是在新生代频繁生成了大量的小对象,导致默认的 Semi space 总是处于很快被填满从而触发 Flip 的状态,这才会出现在 GC 追踪期间这么多的 Scavenge 回收和对应的 CPU 耗费,这样这个问题就变为如何去优化新生代的 GC 来提升应用性能。
通过平台提供的 GC 数据抓取和结果分析,我们知道可以去尝试优化新生代的 GC 来达到提升应用性能的目的,而新生代的空间触发 GC 的条件又是其空间被占满,那么新生代的空间大小由 Flag --max-semi-space-size 控制,默认为 16MB,因此我们自然可以想到要可以通过调整默认的 Semi space 的值来进行优化。
这里需要注意的是,控制新生代空间的 Flag 在不同的 Node.js 版本下并不是一样的,大家具体可以查看当前的版本来进行确认使用。
在这个案例中,显然是默认的 16M 相对当前的应用来说显得比较小,导致 Scavenge 过于频繁,我们首先尝试通过启动时增加 --max-semi-space-size=64 这个 Flag 来将默认的新生代使用到的空间大小从 16M 的值增大为 64M,并且在流量比较大而且进程 CPU 很高时抓取 CPU Profile 观察效果:
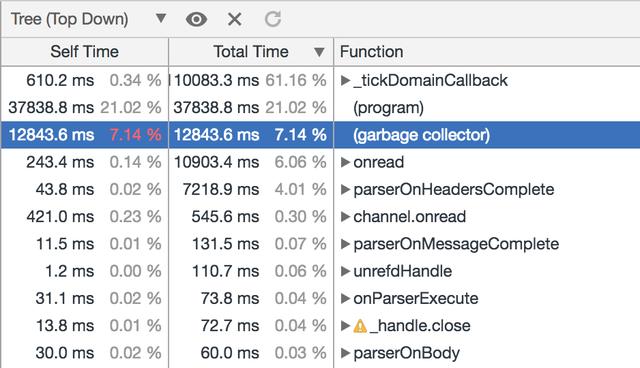
调整后可以看到 Garbage collector 阶段 CPU 耗费占比下降到 7% 左右,再抓取 GC Trace 并观察其展示结果确认是不是 Scavenge 阶段的耗费下降了:
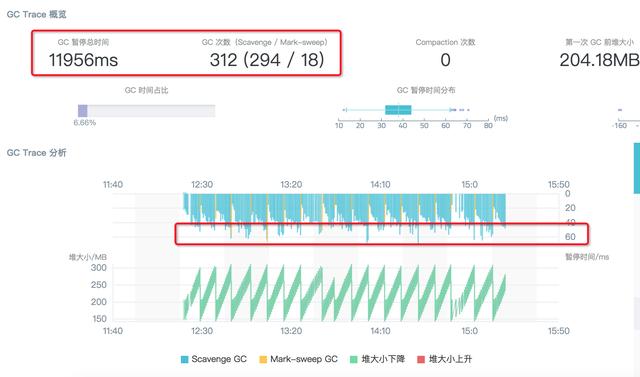
显然,Semi space 调大为 64M 后,Scavenge 次数从近 1000 次降低到 294 次,但是这种状况下每次的 Scavenge 回收耗时没有明显增加,还是在 50 ~ 60ms 之间波动,因此 3 分钟的 GC 追踪总的停顿时间从 48s 下降到 12s,相对应的,业务的 QPS 提升了约 10% 左右。
那么如果我们通过 --max-semi-space-size 这个 Flag 来继续调大新生代使用到的空间,是不是可以进一步优化这个应用的性能呢?此时尝试 --max-semi-space-size=128 来从 64M 调大到 128M,在进程 CPU 很高时继续抓取 CPU Profile 来查看效果:
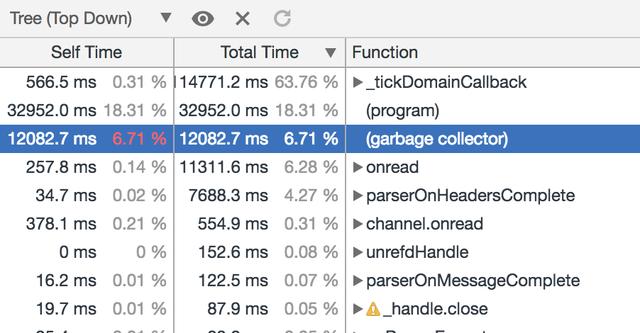
此时 Garbage collector 耗费下降相比上面的设置为 64M 并不是很明显,GC 耗费下降占比不到 1%,同样我们来抓取并观察下 GC Trace 的结果来查看具体的原因:
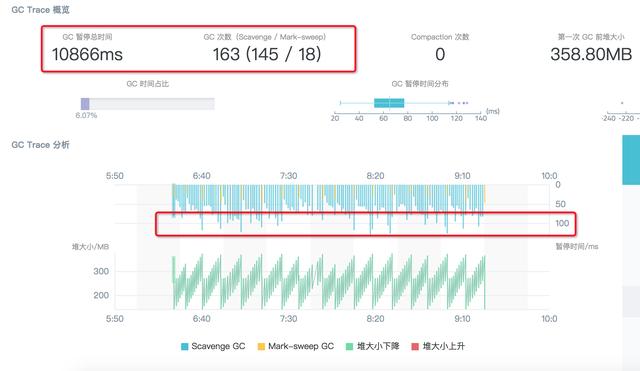
很明显,造成相比设置为 64M 时 GC 占比提升不大的原因是:虽然此时进一步调大了 Semi space 至 128M,并且 Scavenge 回收的次数确实从 294 次下降到 145 次,但是每次算法回收耗时近乎翻倍了,因此总收益并不明显。
按照这个思路,我们再使用 --max-semi-space-size=256 来将新生代使用的空间进一步增大到 256M 再来进行最后一次的观察:
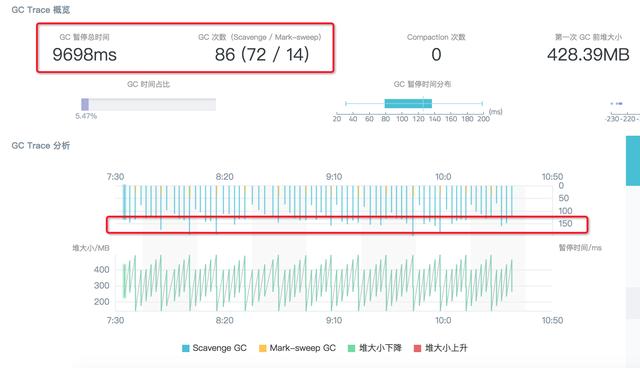
这里和调整为 128M 时是类似的情况: 3 分钟内 Scavenge 次数从 294 次下降到 72 次,但是相对的每次算法回收耗时波动到了 150ms 左右,因此整体性能并没有显著提升。
借助于性能平台的 GC 数据抓取和结果展示,通过以上的几次尝试改进 Semi space 的值后,我们可以看到从默认的 16M 设置到 64M 时,Node 应用的整体 GC 性能是有显著提升的,并且反映到压测 QPS 上大约提升了 10%;但是进一步将 Semi space 增大到 128M 和 256M 时,收益确并不明显,而且 Semi space 本身也是作用于新生代对象快速内存分配,本身不宜设置的过大,因此这次优化最终选取对此项目 最优的运行时 Semi space 的值为 64M。
在本生产案例中,我们首先可以看到,项目使用的三方库其实也并不总是在所有场景下都不会有 Bug 的(实际上这是不可能的),因此在遇到三方库的问题时我们要敢于去从源码的层面来对问题进行深入的分析。
最后实际上在生产环境下通过 GC 方面的运行时调优来提升我们的项目性能是一种大家不那么常用的方式,这也有很大一部分原因是应用运行时 GC 状态本身不直接暴露给开发者。通过上面这个客户案例,我们可以看到借助于 Node.js 性能平台,实时感知 Node 应用 GC 状态以及进行对应的优化,使得不改一行代码提升项目性能变成了一件非常容易的事情。
作者:奕钧
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号