阿里的新款模型与Sora媲美,但“假”开源引发网友热议?
发表时间: 2024-03-05 18:00
作者 | 凌敏、核子可乐
国外有文生视频的 Sora,国内有图生视频的 EMO。
近日,阿里巴巴集团智能计算研究院上线了一款 AI 图生视频模型 EMO(Emote Portrait Alive)。据悉,EMO 是一种富有表现力的音频驱动型肖像视频生成框架,用户用户只需要提供一张照片和一段任意音频文件,EMO 即可生成具有丰富面部表情和多种头部姿态的语音头像视频。此外,EMO 还可以根据输入音频的长度生成任意长度的视频。
在阿里给出的示例中,奥黛丽·赫本深情吟唱:

视频请到原文观看
小李子演唱超“烫嘴”Rap《哥斯拉》:

视频请到原文观看
蒙娜丽莎声情并茂地演讲:

视频请到原文观看
高启强化身罗翔普法:

视频请到原文观看
据了解,为了训练这套模型,阿里建立起一套庞大且多样化的音频视频数据集,共收集了超过 250 小时的视频与超过 1.5 亿张图像。这套庞大的数据集涵盖广泛内容,包括演讲、影视片段、歌唱表演,并涵盖汉语、英语等多种语言。丰富多样的语音和歌唱视频确保训练素材能够涵盖广泛的人类表情与声乐风格,为 EMO 模型的开发提供坚实基础。
论文:
https://arxiv.org/abs/2402.17485
目前,EMO 相关论文已发表于 arXiv,同时在 GitHub 上出现了同名疑似开源的 repo,该项目 GitHub Star 数已达到 3.6 k,但仍然是空仓。这也引起了一部分开发者的不满,质疑其是“假开源”。
GitHub:https://github.com/HumanAIGC/EMO

目前该 repo 并不在阿里官方的 GitHub 目录下,也没有任何地方显示该 repo 与阿里官方直接相关。虽然该 repo 上一级 HumanAIGC 页面显示介绍为“Alibaba TongYi XR”,但真实性并不可考,同时 HumanAIGC 目录下还有多个子项目,但情况都与 EMO 类似,基本都是空仓。InfoQ 就此事向阿里方面求证,截至发稿时暂未得到回应。


目前,EMO 的 issues 中充满了抱怨,有开发者认为,如果该模型效果不好,也不会引来这么多“骂声”,大家对 EMO GitHub 空仓事件反应越大,越说明大家对 EMO 源码感兴趣,也侧面认可了 EMO 的效果。
也有开发者表示可以接受 EMO 不开源,开放 API 接口就行,并表示愿意为其付费。
有专家指出,如果没有开源计划,请不要放空的 GitHub repo;如果有开源计划,最好整理完再开源。


阿里在论文中详细介绍了 EMO 的训练过程。
据介绍,阿里希望建立一套创新型语音头像框架,旨在捕捉广泛且真实的面部表情,包括各种细致的微表情,同时配合自然的头部运动,保证生成的头像视频获得无与伦比的表现力。为了实现这个目标,阿里提出一种新的扩散模型生成能力应用方法,可以直接根据给定的图像和音频片段合成角色头像视频。
这种方法摆脱了对中间表示或复杂预处理的高度依赖,简化了语音头像视频的创建过程,其成果表现出极高的视觉和情感保真度,能够与音频中存在的细微动态紧密匹配。音频信号实际已经包含与面部表情相关的信息,理论上足以支持模型生成各种富有表现力的面部动作。
此外,阿里还在模型中添加了稳定的控制机制,即速度控制器与面部区域控制器,旨在增强生成过程中的稳定性。这两个控制器将充当超参数,以微妙的方式控制信号,保证不致损害最终生成视频的多样性与表现力。为了确保生成视频中的角色与输入参考图像保持一致,阿里还设计并采用了类似的 FrameEncoding 模块以增强 ReferenceNet 方法,借此让角色在整段视频中始终保持稳定。
扩散模型
扩散模型在各个领域都展现出卓越的功能,包括图像合成、图像编辑、视频生成乃至 3D 内容生成等。其中的 Stable Diffusion(稳定扩散,简称 SD)更是堪称典型案例,在利用大型文本图像数据集进行广泛训练之后,采用 UNet 架构迭代生成的模型获得了强大的文本到图像生成能力。这些预训练模型目前已被广泛应用于各类图像与视频生成任务当中。
此外,近期一些工作还采用了 DiT(Diffusion-in-Transformer),这种方法使用包含时间模块和 3D 卷积的 Transformer 对 UNet 进行增强,从而支持更大规模的数据与模型参数。通过从零开始训练整个文本到视频模型,其实现了卓越的视频生成结果。此外,也有研究深入探索了如何应用扩散模型生成语音头像视频并获得了不错的效果,这再次凸显出此类模型在创建逼真头像视频方面的强大能力。
音频驱动头像生成
音频驱动的头像生成技术大致可以分为两种具体方法——基于视频的方法与基于单图像的方法。基于视频的语音头像生成允许对输入的视频片段进行直接编辑。例如,Wav2Lip 就使用音频-唇形同步鉴别器,可根据音频重新生成视频中的唇部运动。但它的局限性在于严重依赖基础视频,导致头部无法自由运动而仅改变嘴部活动,这自然会限制观感的真实性。
至于单图像头像生成,则是利用参考照用来生成与之相符的动态视频。其基本原理是通过学习混合形状与头部姿态来分别生成头部运动和面部表情,然后借此创建 3D 面部网格,以此作为指导最终视频帧生成的中间表示。同样的,3D Morphable Model(3DMM)则作为生成语音头部视频的中间表示。这种方法的常见问题,就是 3D 网格的表现力有限,同样会限制生成视频的整体表现力与真实感。
此外,这两种方法均基于非扩散模型,这进一步限制了生成结果的实际表现。尽管过程中也尝试使用扩散模型来生成语音头像,但结果并未被直接应用于图像帧,而是借此生成 3DMM 的系数。与前两种方法相比,Dreamtalk 在结果上有所改进,但仍无法实现高度自然的面部视频生成。
EMO 框架主要由两个阶段组成。在称为帧编码的初始阶段,ReferenceNet 用于从参考图像和运动帧中提取特征。在随后的扩散过程阶段,预训练的音频编码器负责处理音频嵌入。面部区域掩模与多帧噪声集成则控制面部图像的生成。接下来是使用 Backbone Network 主干网络来促进去噪操作。在主干网络中应用到两种形式的注意力机制:参考注意力和音频注意力。这些机制分别对应维持角色身份和调节角色动作。此外,Temporal Modules 时间模块用于操纵时间维度并调整运动速度。

具体来说,EMO 采用 Stable Diffusion(SD)作为基础框架。SD 是一种被广泛使用的文本到图像(T2I)模型,由 Latent Diffusion Model(LDM)发展而来。其利用自动编码器 Variational Autoencoder(VAE)将原始图像的特征分布 x0 映射至潜在空间 z0,将图像编码为 z0=E(x0),并将潜在特征重建为 x0=D(z0)。这种架构能够降低计算成本,同时保持更高的视觉保真度。
基于 Denoising Diffusion Probabilistic Model (去噪扩散概率模型,简称 DDPM)或 Denoising Diffusion Implicit Model (去噪扩散隐式模型,简称 DDIM)方法,SD 能够将高斯噪声ε引入至潜在 z0,从而在特定时步上产生带噪声的潜在 zt。在推理过程中,SD 会消除潜在 zt 中的噪声ε,并结合文本控制以通过集成文本特征来达成预期结果。整个去噪过程的训练目标表示为:
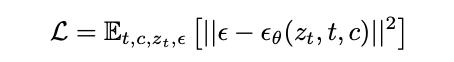
整个训练过程分为三个阶段。第一阶段为图像预训练,其中主干网络、ReferenceNet 和面部定位器被标记在训练当中。在此阶段,主干将单个帧作为输入,而 ReferenceNet 则处理随机选取自一视频片段中的另一不同帧。主干与 ReferenceNet 都以原始 SD 为基础初始化权重。在第二阶段,阿里引入了视频训练,在其中将时间模块与音频层相结合,从视频片段中采样 n+f 个连续帧,其中开始的 n 帧为运动帧。
时间模块从 AnimateDiff 初始化权重。在最后一个阶段,速度层被整合进来,阿里在此阶段只训练时间模块与速度层。作为一项重要决策,团队决定故意在训练过程中省略掉音频层。这是因为说话人的表情、嘴部动作和头部运动的频率主要受音频影响。因此,这些元素之间似乎具有相关性,可能会提示模型根据速度信号、而非音频来驱动角色的运行。最终的实验结果也表明,在训练中同时引入速度层和音频层会破坏音频对角色运动的驱动效果。
与几款领先头像生成模型间的量化比较结果:

测试结果表明,EMO 在视频质量方面具有显著优势,其中 FVD 得分越低则表明质量越好。此外,阿里的方法在单个帧质量上同样优于其他方法,其中 FID 得分越高则表明质量越好。尽管在 SyncNet 指标上未能获得最高分,但阿里的方法在面部表情生动度方面仍表现出色,对应表中的 E-FID 得分(越低越好)。

配合长时间、高音质音频片段,EMO方法生成的结果。在每个片段中,角色均由高音质音频驱动创建,例如歌唱音频。每个片段的时长约为1分钟。

与Diffused Heads的比较,生成的片段时长为6秒。Diffused Heads的生成结果分辨率较低,且生成帧会受到错误累积的影响。
不过,该方法仍有一定局限性。首先,与不依赖扩散模型的方法相比,EMO 更为耗时。其次,由于阿里未使用任何明确的控制信号来引导角色运行,因此可能会无意中生成其他身体部位(例如手部),从而导致视频结果中出现伪影。此问题的一个潜在解决方案,就是采用专门针对身体部位的控制信号。
原文链接:
https://www.infoq.cn/news/oAsg5cT8RBZ7bXDgB70d
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号