如何优化数据库云成本,节省高达98%?
发表时间: 2024-06-11 18:41
一次自研实践。
原文链接:https://hivekit.io/blog/how-weve-saved-98-percent-in-cloud-costs-by-writing-our-own-database/
编程的首要原则是什么?“不要重复你自己”?“如果正常工作,就不要动了”?又或者是“不要自己写数据库!”……最后这条建议不错。
编写数据库简直是噩梦,原子性、一致性、隔离性和持久性,分片、故障恢复和管理,一切的复杂性都不可想象。
幸运的是,我们有很多经过几十年打磨且可以免费使用的优秀数据库。那么,我们为什么还要从头开始编写一个数据库呢?
我们运行了一个云平台,同时跟踪成千上万的人和车辆。每个位置更新都会被保存起来,并通过API检索。
不同的时间点,同时跟踪的车辆数量以及位置的更新频率变化很大,同时连接数大约为13,000个,而这些连接点每秒发送一个更新是很常见的情况。
客户使用这些数据的方式也有很大的不同。有些使用非常粗糙,例如一家汽车租赁公司希望显示客户当天的路线梗概。为了处理这类需求,我们需要为一个小时的行程设置30~100个位置点,而且位置数据在存储之前需要大量的聚合和压缩。
然而,还有许多其他用例不能采用这种处理。例如,快递公司希望重现事故发生前几秒内的情况。我们需要使用非常精确的现场位置跟踪器,生成报告,记录哪位快递员进入了哪个禁区——需要精确到半米。
由于无法提前预知每个客户所需的精度,我们只好存储每一次位置更新。假设汽车租赁公司有13,000辆车,每月将产生大约 35 亿次更新,而且这个数字还会增长。到目前为止,我们一直在使用AWS Aurora和PostGIS扩展来存储地理空间数据。但是Aurora每个月仅数据库费用就超过了1万美元,而且还会越来越贵。
另外,我们所面临的不仅仅是Aurora的价格问题。虽然Aurora可以很好地应对负载,但我们的许多客户都在使用本地版本。他们必须运行自己的数据库集群,如此大量的更新,这些集群很容易被压垮。
不幸的是,如今市面上并没有这样的产品。许多数据库,比如Mongo、H2和Redis,支持点以及区域等空间数据类型。此外,还有“空间数据库”,但它们都是现有数据库之上的扩展。PostGIS建立在PostgreSQL之上,还有Geomesa之类的扩展,它们在其他存储引擎之上提供了很好的地理空间查询能力。
不幸的是,这并不符合我们的需求。
我们的需求大致如下:
极高的写入性能
我们希望每个节点能够处理每秒3万次的位置更新。写入之前可以进行缓 冲, 从而大大降低IOPS。
无限并行
我们希望多个节点能够同时写入数据,没有上限。
占用磁盘空间尽可能小
鉴于数据量巨大,我们需要占用磁盘空间尽可能小。
这意味着,我们需要接受一些权衡。以下是我们可以接受的条件:
中等水平的磁盘读取性能
我们的服务器是围绕内存架构而构建的。实时流的查询和过滤是在内存中的数据上进行的,因此非常快。只有当新服务器上线、客户端使用历史 API 或(即将推出的)应用用户通过数字界面回溯时间时,才会读取磁盘。读取磁盘的速度需要足够快才能提供良好的用户体验,但这类操作的频率相对较低,而且数据量较小。
低一致性保证
我们可以接受丢失一些数据。更新在写入磁盘前会缓冲大约一秒钟。在罕见的情况下,服务器宕机并由另一个服务器接管,这时我们可以接受丢失当前缓冲区中一秒的位置信息。
我们需要持久化的主要实体类型是“对象”,主要是车辆、人员、传感器或机器。对象有一个ID标签、位置和任意键值数据,例如燃料水平或当前乘客ID。位置包括经度、纬度以及精度、速度、方向、海拔和海拔精度,尽管每次更新只能更改这些字段的一个子集。
此外,我们还需要存储区域、任务(“对象”需要执行的任务)和指令(Hivekit服务器根据传入数据执行的一小段空间逻辑)。
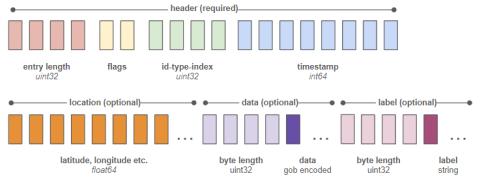
我们专门构建了一个存储引擎,作为核心服务器可执行文件的一部分。这个引擎主要负责以二进制格式写入最低限度的增量数据。记录的格式如下:
上图中的每一个方块代表一个字节。带有“flags”标记的两个字节是一个“是/否”开关列表,用于指定“是否有纬度”、“是否有经度”、“是否有数据”等,目的是告诉解析器在条目的剩余字节中查找哪些内容。
写入每发生200次,存储一次对象的完整状态。这之间(1~199次)只存储增量数据。这意味着,一次更新,包括时间和ID、纬度和经度,仅占用34字节。如此,1GB的磁盘空间就可以存储3千万次位置更新。
此外,我们还维护了一个单独的索引文件,将每个条目的静态字符串ID及其类型(对象、区域等)转换为一个唯一的4字节标识符。由于我们知道这个固定大小的标识符在每个条目字节索引中的位置为6~9,因此检索特定对象的历史记录非常快。
这个存储引擎是服务器二进制文件的一部分,所以运行成本没有变化。然而,真正的变化在于,原来每个月我们需要支付1万美元的Aurora实例费用,如今只需承担200美元的弹性块存储(EBS)。我们使用的是预配置的IOPS SSD(io2),IOPS为3000,同时更新采用了批量处理:每秒每个节点和域写入一次。
EBS具有内置的自动备份和恢复功能,而且可以保证长时间正常运行,所以我们在可靠性保证方面并没有任何损失。目前,我们的数据量大约为:每月100GB。但是,由于客户很少查询超过10天的条目,所以我们将超出30GB的数据移动到AWS Glacier,从而进一步降低了EBS成本。
然而,这不仅仅是成本的问题。通过文件系统写入本地EBS的速度超过了写入Aurora,开销也更低。由于查询内容并非完全相同,所以很难量化,此处仅举一例,重现某个域历史特定时间点的操作的时间从大约两秒降到了13毫秒。
当然,这样的比较并不公平,毕竟Postgres是一种通用数据库,拥有丰富的查询语言,而我们构建的只是一个流式处理二进制文件的游标,功能非常有限。但话说回来,我们所需的功能仅此而已,而且我们并没有失去任何功能。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12






 鲁公网安备37020202000738号
鲁公网安备37020202000738号