Java ZGC技术深度解析
发表时间: 2024-06-27 13:42
01
前言
在 Java 应用程序中,垃圾回收(Garbage Collection,以下简称 GC)是一个不可避免的过程,它负责释放不再使用的内存空间以避免内存泄漏。然而,GC 操作通常会导致短暂的停顿时间(Stop the World,以下简称 STW),这对于对延迟敏感的应用程序来说是一个严重的问题——STW 会导致应用程序暂停响应,从而影响用户体验和系统性能。
为了解决这个问题,Java 引入了 Z Garbage Collector(以下简称 ZGC),它是一种低延迟垃圾回收器,旨在减少 GC 引起的停顿时间。ZGC 通过使用并发和分区收集技术,大大减少了 STW 的时间和频率,使得应用程序可以在 GC 期间继续运行,从而提供更加平滑和一致的性能。
AutoMQ 基于 ZGC 进行了一系列调优,以获得更低的延迟。在本文中,我们将详细介绍 ZGC 的工作原理,以及如何通过调整和优化 ZGC 的配置来实现更低的延迟,从而提高 Java 应用程序的性能和响应能力。
02
ZGC 特点
在介绍 ZGC 的实现原理之前,我们先来了解一下 ZGC 的特点,以便更好地理解 ZGC 的工作原理:
可扩展性:ZGC 支持各种规模的内存大小,从 8MB 到 16TB,可以满足不同规模和需求的应用程序。
极低延迟:单次 GC 操作 STW 时间低于 1ms(一般不超过 200 μs),平均仅需数十微秒。
可预测性:ZGC 的 STW 时长不会随着堆大小的增加、对象数量的增加或者 GC 操作的频率而增加,因此可以提供可预测的性能。
高吞吐量:ZGC 的吞吐量与 G1GC 相当,可以满足高吞吐量的应用程序需求。
自动调优:ZGC 会自动调整自身的配置参数,以适应不同的应用程序和环境,减少了手动调优的工作量。
03
ZGC 工作原理
下面我们将详细介绍 ZGC 的工作原理,以便更好地理解 ZGC 的优势和特点。
注意:以下介绍均基于 JDK 17 版本的 ZGC,部分内容可能与其他版本有所不同,例如,没有涉及到 JDK 21 中引入的分代(Generational)ZGC。
3.1 核心概念
着色指针与多重映射
ZGC 使用了一种称为“着色指针(Colored Pointers,又称染色指针)”的技术,它将对象指针的高位用于存储额外的信息,这些额外的信息可以用于标记对象的状态,进而帮助 ZGC 实现高效的并发垃圾回收。ZGC 中着色指针的结构如下图所示:
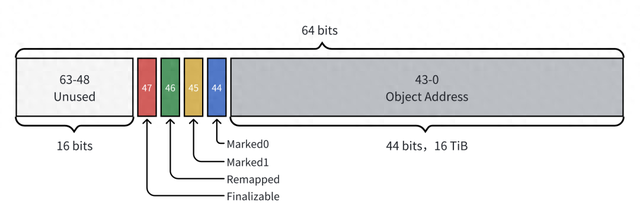
如上图所示,着色指针的高位包含了 20 位的元数据,这 20 位元数据用于存储对象的标记信息。目前,ZGC 中使用了其中的 4 位,剩余的 16 位保留用于未来的扩展。这 4 位的作用如下:
Marked0 & Marked1:这两位表示对象是否已被 GC 标记,以及是在哪个周期标记。ZGC 在每个 GC 周期中交替使用这两位,以确定对象是在上个周期亦或当前周期被标记。
Remapped:该位表示指针是否已经进行了重映射,即指针不再指向迁移集合(Relocation Set)中的对象。
Finalizable:该位表示对象是否仅通过 finalizer 可达。需要注意的是,JDK 18 中的 JEP 421 已经将 finalization 标记为过时,并将在未来的版本中移除。
Java 应用程序本身不会感知到着色指针,当从堆内存中加载对象时,着色指针的读取由读屏障处理。
相较于传统的垃圾回收器将对象存活信息记录在对象头中,ZGC 基于着色指针记录了对象状态,在修改状态时仅为寄存器操作,无需访问内存(对象头的 Mark Word),速度更快。
由于着色指针在对象地址的高位存储了额外的信息,因此会有多个虚拟地址映射到同一个对象,此即多重映射(Multi-Mapping)。在 ZGC 中,每个对象的物理地址会映射到三个虚拟地址,分别对应着色指针的三种状态,下图展示了多重映射的实际情况:
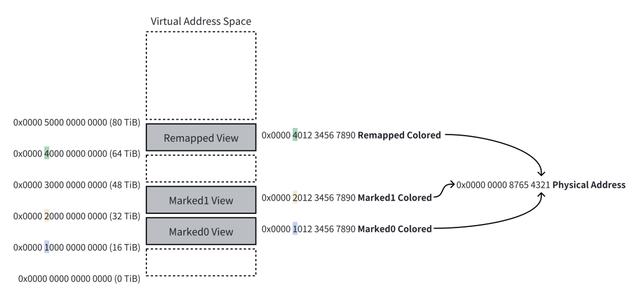
值得一提的是,某些监控工具(比如 top)没有处理这种多重映射的场景,这会导致其无法正确识别开启了 ZGC 的 Java 进程占用的内存——监控值会显示为实际值的 3 倍,甚至可能会出现使用 100%+ 物理内存的现象。
读屏障
在上一小节中,我们提到了着色指针的读取由读屏障处理。读屏障(Load barriers)是 JIT 编译器(C2)注入到类文件中的代码段,它会在 JVM 解析类文件时添加到所有从堆中检索对象的地方。下面的 Java 代码示例展示了读屏障会被添加的地方:
Object o = obj.fieldA; // 从堆中读取 Object,会触发读屏障Object p = o; // 没有从堆中加载,不会触发读屏障o.doSomething(); // 没有从堆中加载,不会触发读屏障int i = obj.fieldB // 加载的不是对象,不会触发读屏障
具体的插入方式形如:
Object o = obj.fieldA;// 触发读屏障if (o & bad_bit_mask) {// o 的着色指针的颜色不对,进行修复slow_path(register_for(o), address_of(obj.fieldA));}
实际的汇编实现:
mov 0x20(%rax), %rbx // Object o = obj.fieldA;// %rax 寄存 obj 地址,0x20 为 fieldA 在其中的偏移量,%rbx 用于寄存 Object o 的地址test %rbx, %r12 // if (o & bad_bit_mask)// %r12 寄存染色指针当前 bad color 的掩码// ZGC 不支持压缩对象指针(compressed oops),故可以利用为压缩指针预留的 %r12 寄存器jnz slow_path // %rbx 中的指针为 bad color,修复颜色——按需修改 0x20(%rax) 与 %rbx
ZGC 中,读屏障注入的代码会检查对象指针的颜色,如果颜色是“坏的”,那么读屏障会尝试修复颜色——更新指针,使它指向对象的新位置,或者迁移对象本身。
这种处理方式保证了,在一次 GC 期间,对象迁移等重操作仅会在首次加载对象时发生,之后的加载操作则会直接读取对象的新位置,额外开销仅为一次位运算判断。据官方测试,ZGC 读屏障带来的额外性能开销在 4% 左右。
区域化内存管理
类似于 G1GC,ZGC 会动态地将堆划分为独立的内存区域(Region),但是,ZGC 的区域更加灵活,包括小、中、大三种尺寸,活跃区域的数量会根据存活对象的需求而动态增减。
将堆划分为区域可以带来多方面的性能优势,包括:
分配和释放固定大小的区域的成本是恒定的。
当区域内的所有对象都不可达时,GC 可以释放整个区域。
相关对象可以被分组到同一个区域中。
值得注意的是,所谓的“小区域”、“中区域”和“大区域”并不是指区域的大小,而是指区域的类别和用途。例如,一个大区域可能比一个中等区域还要小。下面将介绍不同区域尺寸及其用途:
小区域:小区域的大小为 2 MB,用于存储小于 1/8 区域大小(即 256 KB)的对象。小区域的大小是固定的,不会随着堆的大小而变化。
中区域:中区域的大小会根据堆的大小(-XX:MaxHeapSize,-Xmx)而变化。如下表所示,中区域的大小可能为 4 / 8 / 16 / 32 MB,特别地,如果堆大小小于 128 MB,则不会有中区域。中区域用于存储小于 1/8 区域大小的对象。
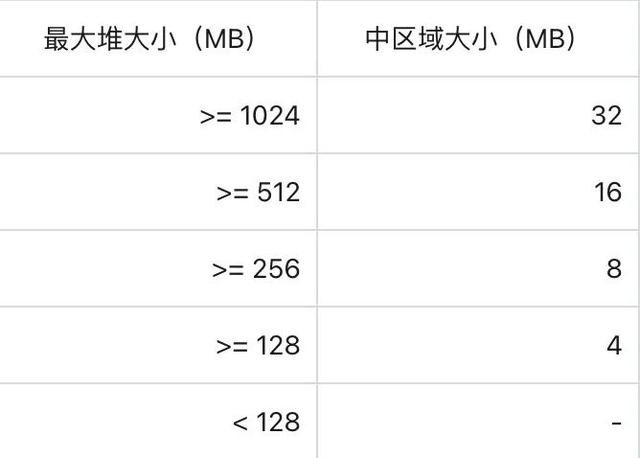
大区域:大区域用于存储巨大对象,其大小与对象的大小紧密匹配,以 2 MB 为增量。例如,一个 13 MB 的对象将被存储在一个 14 MB 的大区域中。任何无法适应中区域的对象都将被放置在自己的大区域中,每个大区域仅会放置一个大对象,并且不会被重复利用。
压缩与迁移
上一小节中提到,区域化的优势之一是可以利用“大多数同一时间创建的对象也会在同一时间离开作用域”的特点。然而,并非所有对象都是这样,在区域内部必然会产生碎片,导致内存利用率下降。
基于内部的启发式算法,ZGC 会将主要由不可访问对象组成的区域中的对象复制到新区域中,以便释放旧区域并释放内存,这就是压缩与迁移(Compaction and Relocation)。ZGC 通过两种迁移方法实现压缩:就地迁移和非就地迁移。
非就地迁移:ZGC 的首选迁移方法,当存在空区域可用时,ZGC 会执行非就地迁移。非就地迁移的示例如下:
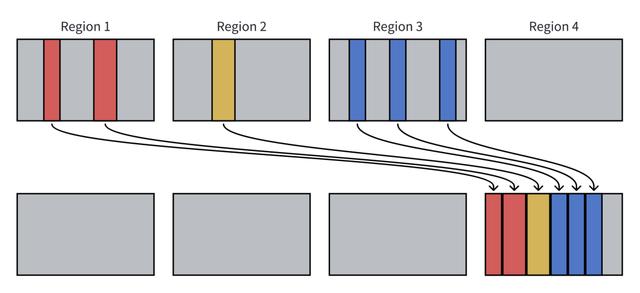
就地迁移:当没有空区域可用时,ZGC 将使用就地迁移。在这种情况下,ZGC 会将对象移动到一个较为稀疏的区域中。就地迁移的示例如下:

值得说明的是,在执行就地迁移时,ZGC 必须首先压缩指定为对象迁移区域内的对象,这可能会对性能产生负面影响。增加堆大小可以帮助 ZGC 避免使用就地迁移。
3.2 工作流程
值得说明的是,在执行就地迁移时,ZGC 必须首先压缩指定为对象迁移区域内的对象,这可能会对性能产生负面影响。增加堆大小可以帮助 ZGC 避免使用就地迁移。
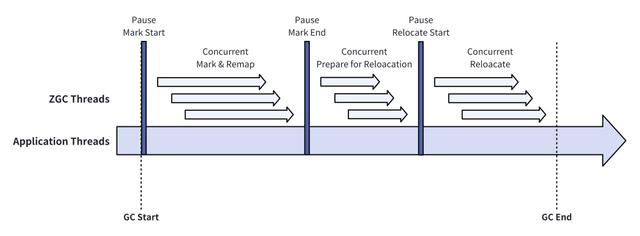
如上图,ZGC 的工作流程主要包括以下几个步骤:
(STW)标记开始
标记阶段开始的同步点,只会执行一些小的操作,例如设置一些标记位和确定全局颜色。
值得说明的是,在 JDK 16 之前,该阶段的耗时和 GC Roots(静态变量与线程栈中的局部变量)的数量成正比。因此在 JEP 376 中引入了一种新的算法,将扫描线程栈的操作转移到并发阶段,从而显著减少了该阶段的耗时。
(并发)标记与重映射
在这个并发阶段,ZGC 将遍历整个对象图,并标记所有对象(根据 GC 周期不同,设置 Marked0 或 Marked1 标记)。同时,将上一个 GC 周期中尚未被重映射的对象(标记仍为 Marked1 或 Marked0)进行重映射。
(STW)标记结束
标记阶段结束的同步点,会处理一些边界情况。
(并发)迁移准备
该阶段会处理弱引用、清理不再使用的对象,并筛选出需要迁移的对象(Relocation Set)。
(STW)迁移开始
迁移阶段开始的同步点,通知所有涉及到对象迁移的线程。
同样的,在 JDK 16 引入 JEP 376 之后,该阶段的耗时不再与 GC Roots 的数量成正比。
(并发)迁移
该阶段会并发地迁移对象,压缩堆中的区域,以释放空间。迁移后的对象的新地址会记录到转发表(Forwarding Table)中,用于后续重映射时获取对象的新的地址;该转发表是一个哈希表,使用堆外内存,每个区域分别有一个转发表。
可以看到,在一个 GC 周期中,STW 的阶段和并发阶段交替执行,并且绝大多数操作均在并发阶段执行。
示例
为了更好地理解 ZGC 的工作原理,下面通过一个例子来展示 ZGC 工作各阶段执行的操作。
1. 【GC 开始】初始状态

上图中为 GC 开始前 Java 堆的状态:共有 3 个区域,9 个对象。
所有新创建的对象初始颜色均为 Remapped。
2. 【标记阶段】从 GC Roots 开始遍历,标记所有存活的对象
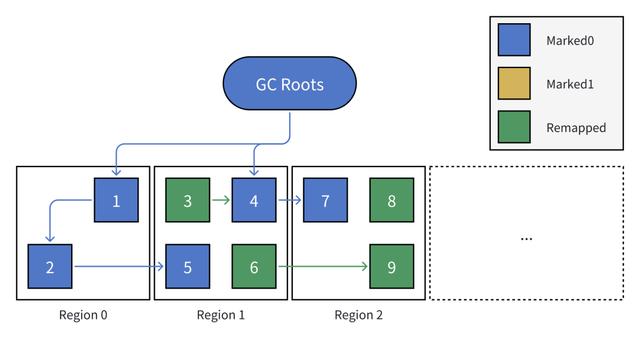
每次 GC 之间的标记阶段轮流使用 Marked0 与 Marked1,本次使用 Marked0。
GC Roots(例如,线程栈中引用的对象,静态变量等)为每次标记的起点,所有被 GC Roots 引用的对象都应被认为是存活的;同样的,如果未被标记(颜色仍为 Remapped),则认为可被回收。
3. 【迁移准备阶段】选择需要压缩的区域,并创建转发表
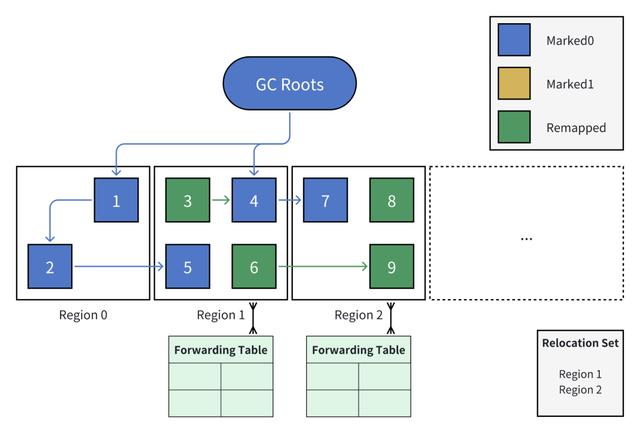
检查各区域发现,区域 1 与区域 2 存在需要回收的对象,将它们加入迁移集合。
并为所有迁移集合中的区域创建转发表。
4. 【迁移阶段】遍历所有对象,迁移其中处于迁移集合中的对象
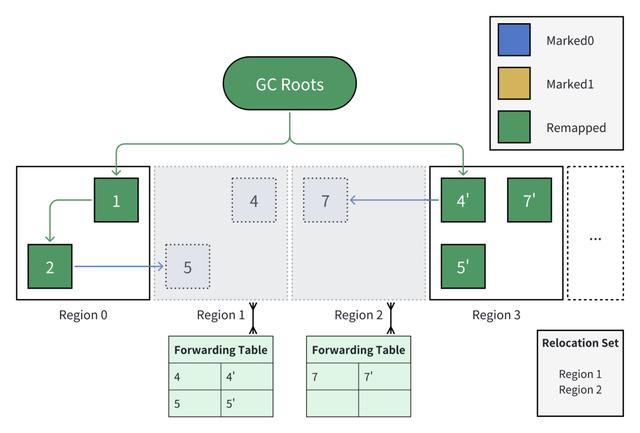
a. 遍历到对象 1、2,发现它们位于区域 0(不在迁移集合中),无需迁移,仅将颜色恢复为 Remapped。
b. 遍历到对象 4、5、7,均在迁移集合中,需要迁移。
创建(或复用)一个新的区域——区域 3,用于放置这 3 个对象。
依次将这 3 个对象迁移至新的区域,并将它们新的地址记录在转发表中。
将这 3 个对象的颜色恢复为 Remapped。
注意:
迁移完成后,迁移集合中的区域 1 与区域 2 即可被复用,用于分配新的对象。但为了便于理解,图中保留了 4、5、7 这 3 个对象的历史位置,并加了“'”号用以区分新老位置。
值得注意的是,此时对象 2(对象 4')中记录的对象 5(对象 7)的地址仍为迁移前的地址,指针的颜色也仍为标记时的颜色 Marked0。
5. 【迁移后的任意时间】用户线程加载对象
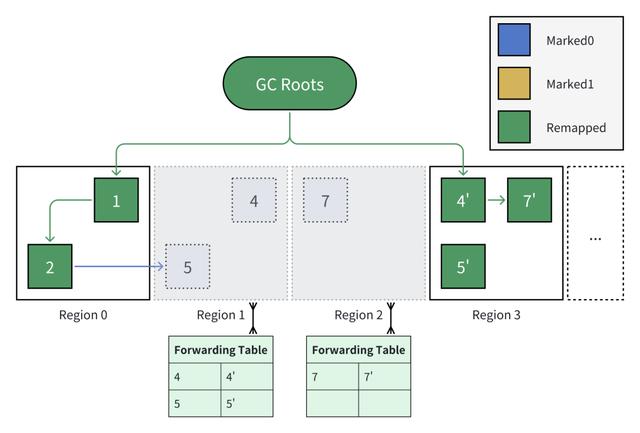
在对象 7 迁移完成后,如果此时用户线程尝试加载对象 7,会触发读屏障(指针实际颜色 Marked0 与期望颜色 Remapped 不符,是“坏的”)。在读屏障中,会基于转发表,将对象 7 的地址重映射对象 7'。
6. 【下一次 GC 标记阶段】重映射所有未被用户线程加载过的对象
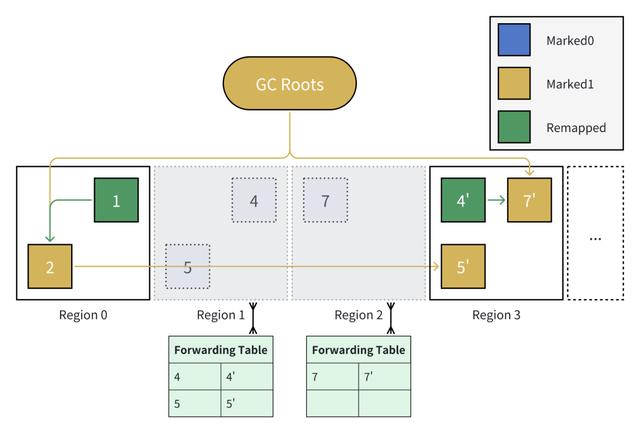
在下一次 GC 的标记阶段,会使用 Marked1 标记出所有存活对象。
与此同时,发现对象 2 引用了对象 5,而对象 5 的颜色是“坏的”(对象 5 的实际颜色 Marked0 与期望颜色 Remapped 不符),会基于转发表,将对象 5 的地址重映射对象 5'。
注意:
每次 GC 的 GC Roots 引用的对象可能不同,在本例中,从对象 1 与对象 4' 变成了对象 2 与对象 7'。
7. 【下一次 GC 迁移准备阶段】清理转发表
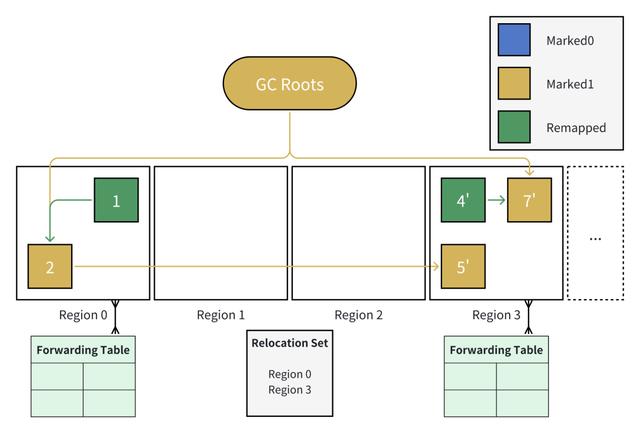
与之前的迁移准备阶段类似,需要确定迁移集合、创建转发表。此外,还需要将上一次 GC 的转发表删除。
04
使用 ZGC
接下来,我们将介绍如何更好地使用 ZGC,以及一些基本的调优方法。
4.1 配置
正如在本文开头所述,ZGC 的一个设计目标是,尽可能自动调整自身的配置参数,以减少手动配置项。但是我们还是应该了解各个配置的含义以及对 ZGC 的影响,以应对实际生产中的各种需求。
-XX:+UseZGC:开启 ZGC。
-XX:MaxHeapSize, -Xmx:堆的最大大小。它是 ZGC 最重要的调优配置,它的数值越大,ZGC 的理论性能上限越高,但同时也可能会造成部分内存浪费。
由于 ZGC 是一个并发垃圾回收器,最大堆的大小必须满足:能够容纳应用程序的存活对象,并且有足够的空间以便在 GC 运行期间分配新的对象。出于同样的原因,ZGC 比传统 GC 需要相对更多的冗余空间。
-XX:+UseDynamicNumberOfGCThreads:是否开启并发阶段动态 GC 线程数,默认为开启。
° 当开启时,ZGC 会根据 GC 运行状态(例如 GC 耗时、堆空余空间、对象分配频率等)由内置的启发式算法自动选择并发阶段的 GC 线程数量(最小为 1,最大为 -XX:ConcGCThreads)。
° 当关闭时,则会固定使用 -XX:ConcGCThreads 数量的线程。
-XX:ConcGCThreads:用于控制并发阶段的 GC 线程数量。当开启 -XX:+UseDynamicNumberOfGCThreads 时,默认值为处理器数量的 1/4(向上取整);关闭时,默认值为处理器数量的 1/8(向上取整)。
° 该配置过高可能会导致 GC CPU 占用过多,进而导致应用程序延迟上升。
° 过低则可能导致 GC 不及时以至于发生 Allocation Stall(无法分配新对象)。
° 推荐开启 -XX:+UseDynamicNumberOfGCThreads 以自动调整并发阶段的 GC 线程数量
-XX:ParallelGCThreads:用于控制 STW 阶段的 GC 线程数量。默认值为处理器数量的 60%(向上取整)。
-XX:+UseLargePages:用于控制是否开启巨页(Huge Page,又称 Large Page)。开启后可以提高 ZGC 吞吐、降低延迟,并加快启动速度。默认关闭,开启前需要在 OS 分配巨页。
-XX:+ZUncommit、-XX:ZUncommitDelay:用于控制是否将不使用的内存返回给操作系统,以及返回前等待的时间。当 -XX:MaxHeapSize 与 -XX:MinHeapSize 相同时,则不会生效。默认值为开启、300 秒。
需要注意的是,开启该功能可能会导致分配内存变慢,进而导致延迟升高。对于对延迟较为敏感的应用程序,建议将 -Xmx 与 -Xms 设置成相同的值。特别地,可以开启 -XX:AlwaysPreTouch 以在应用启动前预分配内存,进而降低延迟。
-XX:ZAllocationSpikeTolerance:用于控制 GC 频率自适应算法的“毛刺系数”。ZGC 内置了一套自适应算法,会根据对象分配频率与堆可用空间自动调整 GC 频率。该配置的值越大,该算法会更加敏感,即,更容易因为对象分配频率的增加而增大 GC 频率。默认值为 2。
该配置值过小会导致对象分配速率激增时 GC 不及时,进而可能导致 Allocation Stall;过大则可能会导致 GC 频率过高,占用 CPU 资源增加,影响应用延迟。
-XX:ZCollectionInterval:用于控制每次 GC 的最大时间间隔。默认值为 0,即不做限制。
-XX:ZFragmentationLimit:用于控制每个区域碎片的最大占比。配置为更小的值会导致内存压缩是更加激进,花费更多的 CPU 以换取更多的可用内存。默认值为 25。
-XX:+ZProactive:用于控制是否启用主动 GC 循环。如果启用此选项,ZGC 将在预计对运行中的应用程序影响最小的情况下启动主动 GC 循环。默认开启。
4.2 日志
可以通过设置 -Xlog:gc*:gc.log 选项以开启 ZGC 日志。其中 "gc*" 意为打印所有 tag 中以 "gc" 开头的日志,"gc.log" 为日志存储路径。
下面以 AutoMQ 在实际运行时的一次 GC 为例,按照不同的 log tag,解释 ZGC 日志的含义。
"gc,start","gc,task","gc"
[gc,start ] GC(100) Garbage Collection (Timer)[gc,task ] GC(100) Using 1 workers...[gc ] GC(100) Garbage Collection (Timer) 2240M(36%)->1190M(19%)
第 1 行标志了一次 GC 的开始,是进程启动后的第 100 次(从 0 开始计数)GC,触发原因为 "Timer"。ZGC 可能的触发条件有:
Warmup:ZGC 首次启动后的预热。
Allocation Rate:由 ZGC 内部自适应的 GC 频率算法触发。如前文所述,其敏感度受 -XX:ZAllocationSpikeTolerance 控制。
Allocation Stall:在分配对象时,堆可用内存不足时触发。这会导致部分线程阻塞,应尽可能避免该场景。
Timer:当 -XX:ZCollectionInterval 配置不为 0 时,定时触发的 GC。
Proactive:当应用程序空闲时由 ZGC 主动触发,受 -XX:+ZProactive 控制。
System.gc():在代码中显式调用System.gc()时触发。
Metadata GC Threshold:元数据空间不足时触发。
第 2 行意为该次 GC 使用了 1 个并发线程,受 -XX:ConcGCThreads 与 -XX:+UseDynamicNumberOfGCThreads 控制。
最后 1 行标志了一次 GC 的开始,GC 开始前堆中占用的内存为 2240M,占堆总大小的 36%;GC 完成后为 1190M,占 19%。
"gc,phases"
[gc,phases ] GC(100) Pause Mark Start 0.005ms[gc,phases ] GC(100) Concurrent Mark 1952.113ms[gc,phases ] GC(100) Pause Mark End 0.018ms[gc,phases ] GC(100) Concurrent Mark Free 0.001ms[gc,phases ] GC(100) Concurrent Process Non-Strong References 79.422ms[gc,phases ] GC(100) Concurrent Reset Relocation Set 0.066ms[gc,phases ] GC(100) Concurrent Select Relocation Set 12.019ms[gc,phases ] GC(100) Pause Relocate Start 0.009ms[gc,phases ] GC(100) Concurrent Relocate 149.037ms
记录了 ZGC 各个阶段的耗时,其中 "Pause" 与 "Concurrent" 分别标识了 STW 阶段与并发阶段。每次 GC 会存在 3 个 "Pause" 阶段,应主要关注它们的耗时。
"gc,load",
[gc,load ] GC(100) Load: 2.74/2.02/1.54记录了过去 1 分钟、5 分钟、15 分钟的平均负载,即系统的平均活跃进程数。
"gc,mmu"
[gc,mmu ] GC(100) MMU: 2ms/93.9%, 5ms/97.6%, 10ms/98.8%, 20ms/99.4%, 50ms/99.7%, 100ms/99.9%记录了 GC 期间的最小可用性(Minimum Mutator Utilization)。以本次 GC 为例,在任何连续的 2ms 的时间窗口中,应用至少能使用 93.9% 的 CPU 时间。
"gc,ref"
[gc,ref ] GC(100) Soft: 6918 encountered, 0 discovered, 0 enqueued[gc,ref ] GC(100) Weak: 8835 encountered, 1183 discovered, 4 enqueued[gc,ref ] GC(100) Final: 63 encountered, 3 discovered, 0 enqueued[gc,ref ] GC(100) Phantom: 957 encountered, 882 discovered, 0 enqueued
记录了 GC 期间不同类型的引用对象的处理情况。各字段含义如下:
"Soft":软引用(SoftReference)。软引用对象会在内存不足时被回收。
"Weak":弱引用(WeakReference)。弱引用对象只要被垃圾收集器发现,就会被回收。
"Final":终结引用(FinalReference)。终结引用允许对象在被垃圾回收之前执行一些特定的清理操作。
"Phantom":幽灵引用(PhantomReference)。幽灵引用通常用于确保对象被完全回收后才执行某些操作,它比终结引用提供了更精确的控制。
"encountered":GC 期间遇到的引用对象的数量。
"discovered":GC 期间发现需要处理的引用对象的数量。
"enqueued":GC 期间加入到引用队列(Reference Queue)中的引用对象的数量。
"gc,reloc"
[gc,reloc ] GC(100) Small Pages: 1013 / 2026M, Empty: 2M, Relocated: 41M, In-Place: 0[gc,reloc ] GC(100) Medium Pages: 2 / 64M, Empty: 0M, Relocated: 9M, In-Place: 0[gc,reloc ] GC(100) Large Pages: 3 / 150M, Empty: 0M, Relocated: 0M, In-Place: 0[gc,reloc ] GC(100) Forwarding Usage: 19M
前 3 行记录了不同大小的区域在 GC 时的表现。以第 1 行为例:
共有 1013 个小区域,总大小为 2026 MB
整理过程中发现了 2MB 的未被使用的区域
迁移了 41MB 的对象
其中有 0 MB 是原地迁移(该值过大意味着堆可用空间不足)
第 4 行记录了迁移对象时,各区域使用的转发表的总大小。
"gc,heap"
[gc,heap ] GC(100) Min Capacity: 6144M(100%)[gc,heap ] GC(100) Max Capacity: 6144M(100%)[gc,heap ] GC(100) Soft Max Capacity: 6144M(100%)[gc,heap ] GC(100) Mark Start Mark End Relocate Start Relocate End High Low[gc,heap ] GC(100) Capacity: 6144M (100%) 6144M (100%) 6144M (100%) 6144M (100%) 6144M (100%) 6144M (100%)[gc,heap ] GC(100) Free: 3904M (64%) 3394M (55%) 3372M (55%) 4954M (81%) 4954M (81%) 3340M (54%)[gc,heap ] GC(100) Used: 2240M (36%) 2750M (45%) 2772M (45%) 1190M (19%) 2804M (46%) 1190M (19%)[gc,heap ] GC(100) Live: - 543M (9%) 543M (9%) 543M (9%) - -[gc,heap ] GC(100) Allocated: - 510M (8%) 534M (9%) 570M (9%) - -[gc,heap ] GC(100) Garbage: - 1696M (28%) 1694M (28%) 75M (1%) - -[gc,heap ] GC(100) Reclaimed: - - 2M (0%) 1620M (26%) - -
记录了该 GC 周期中,不同阶段(标记前、标记后、迁移前、迁移后)的各类内存的大小。具体地说:
Capacity:堆的容量。
Free:堆中空闲的内存大小,与 Used 相加即为堆的容量。
Used:堆中使用的内存大小,其最大值即为 GC 期间堆的最大使用量。
Live:堆中存活的对象,即,可达的对象的总大小。
Allocated:和上一阶段相比,新分配的对象的大小。
Garbage:堆中垃圾对象的总大小。
Reclaimed:和上一阶段相比,回收的垃圾对象的大小。
4.3 版本演进
自 2018 年 ZGC 于 JDK 11 中首次发布以来,在后续的 JDK 版本中,ZGC 也在不断演进。在选择使用 ZGC 前,需要了解 ZGC 的版本演进,以及每个版本的特性和限制,并确认对应版本的 ZGC 可以满足使用需求。
JDK 11:ZGC 首次发布,支持 Linux/x64 平台
JDK 13:支持的最大堆内存大小从 4TB 提升到 16TB;支持 Linux/AArch64 平台
JDK 14:支持 MacOS 和 Windows 平台
JDK 15:首个生产就绪版本
JDK 16:引入 Concurrent Thread Stack Scanning,使得 STW 时间不再随线程数增加而线性增加,最大 STW 时长从 10ms 降低到 1ms;支持就地迁移
JDK 17:支持 MacOS/AArch64 平台
JDK 18:支持 Linux/PowerPC 平台
JDK 21:支持 Generational ZGC,通过将堆分为年轻代和老年代,大幅提高 ZGC 的最大吞吐
一般来说,JDK 16 及之后的 ZGC 性能已经优化得足够好,足以适配绝大多数场景。
05
AutoMQ 的调优实践
AutoMQ [1] 是我们基于云重新设计的云原生流系统,通过将存储分离至对象存储,在保持和 Apache Kafka 100% 兼容的前提下,可以为用户提供高达 10 倍的成本优势以及百倍的弹性优势。在流系统的应用场景中,诸如金融交易、实时推荐等场景都对延迟有非常高的要求。因此在设计 AutoMQ 时候,我们也十分重视延迟指标的优化。
在 AutoMQ 的实现中,我们需要尽可能地减少 GC 的停顿时间。而 ZGC 低延迟的特性完美匹配了我们的场景,AutoMQ 通过使用 ZGC,将 STW 时间降低到了 50μs 以下,大大提升了服务的性能,从而为用户提供端到端个位数毫秒的延迟能力。
5.1 案例
下面介绍一些 AutoMQ 在使用 ZGC 时遇到的问题与解决方法。
堆大小选取
使用 ZGC 的第一件事,就是确定堆的大小。有以下几个方面需要考虑:
由于 ZGC 是一个并发垃圾回收器,相较于传统 GC(例如 G1GC),ZGC 需要相对更多的冗余空间用于容纳 GC 期间新创建的对象。
较多的空闲内存可以使得 ZGC 在迁移阶段更多地使用非就地迁移(而非就地迁移),这可以加快 GC 速度,减少 CPU 消耗。但是,过多的冗余内存也会造成资源浪费。
将堆的大小配置为动态调整可以使应用在空闲时释放冗余内存,节约资源。但是,这样做也会导致堆扩容时分配内存变慢,进而导致应用延迟升高。
最终经过充分压测,将 AutoMQ 在经典机型(2 vCPU,16 GiB RAM)上堆大小相关的配置设为:
-Xms6g -Xmx6g -XX:MaxDirectMemorySize=6g -XX:MetaspaceSize=96m由于 AutoMQ 的缓存 Log Cache 与 Block Cache 都使用了 DirectByteBuffer,故还配置了 6 GB 的堆外内存。
在该配置下,可以做到:
通常场景下最高堆内存占用小于 50%,极端场景下小于 70%。
迁移阶段不会发生就地迁移。
考虑到 AutoMQ 一般不会与其他应用混部,将堆的最大大小与最小大小设置为同一个值,以避免堆扩容时延迟升高。
流量激增时延迟抖动
现象
当机器承载流量激增时(从 0 MBps 上升至 80 MBps),会出现数次 “Allocation Stall”(随后自动恢复),导致内存分配阻塞,应用卡顿。
分析
默认配置下,ZGC 会基于内置的自适应算法决定 GC 频率,在该算法下,GC 频率主要由对象分配频率决定。
但是,当应用压力突然上升时,该算法可能无法及时感知,导致 GC 不及时,进而导致 Allocation Stall。
解决方法
增大 -XX:ZAllocationSpikeTolerance 的值(默认为 2),使得 ZGC 能处理更大的抖动(代价是触发 GC 的时机更加激进,GC 频率升高,GC 资源消耗变多)
配置 -XX:ZCollectionInterval,以强制定期触发 GC。
AutoMQ 将 -XX:ZCollectionInterval 设置为 5s,没有修改 -XX:ZAllocationSpikeTolerance(这是因为,每 5 秒进行一次 GC 时,已经能够承载较大的压力,不会再有压力大幅上升的情况)。
进行如上配置后,可以做到:
能够正常处理流量激增的情况,不会发生 "Allocation Stall"。
通常场景下,会固定 5s 进行一次 GC(日志中记录为 "Timer")。
极端场景下,约 3s 进行一次 GC(日志中记录为 "Allocation Rate")。
应用启动后 GC 压力逐渐升高
现象
在应用启动后,随着时间的推移,GC 频率逐渐上升、耗时变长、CPU 占用升高,并最终发生 “Allocation Stall”。
分析
检查 GC 日志,发现每次 GC 时,存活对象的大小逐渐增加,导致可用内存减少,最终导致 Allocation Stall。
解决方法
检查 Heap Dump,发现某模块存在内存泄露,导致无用对象没有及时释放,最终导致上述问题。
修复该问题后,AutoMQ 存活对象的大小维持在 500 MB~600 MB,极端场景下不超过 800 MB。
超大规模集群中 GC 压力高
现象
在超大规模集群压测(90 节点、100,000 分区、6 GiB/s 流量)中,发现 Active Controller CPU 占用达 80%,检查火焰图发现 ZGC 占用了一半以上的 CPU 时间。
分析
检查 GC 日志,发现 GC 耗时偏高(约 5s,主要为标记阶段耗时),且存活对象较多(约 1800 MB)。
检查 Heap Dump,发现为元数据相关的对象较多,导致 ZGC 遍历标记较慢,且占用大量 CPU。
解决方法
优化元数据管理模式,将部分元数据卸载到 S3 层(而非内存),以降低元数据的内存消耗。
JDK 21 中支持了 Generational ZGC,将对象分为老年代和新生代,可以较好地处理前述存活对象过多导致的 GC 压力高的问题。
5.2 调优效果
AutoMQ 经过大量的压测与调优,得益于 ZGC 并发 GC 的优势,实现了极低的延迟。下表对比了 AutoMQ 在 ZGC 和 G1GC 下的表现:

*:测试环境为 2 vCPU,16 GiB RAM。测试负载为 4,800 分区,80 / 80 MBps 生产/消费流量,1,600 Produce/s,1,600 Fetch/s
**:ZGC 的配置参数为 -XX:+UseZGC -XX:ZCollectionInterval=5
***:G1GC 的配置参数为 -XX:+UseG1GC -XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50 -XX:MaxMetaspaceFreeRatio=80 -XX:+ExplicitGCInvokesConcurrent
可以看到,AutoMQ 在使用 ZGC 时,由于 STW 时间极短,发送延迟大幅降低;以少量的 CPU 消耗为代价,整体性能大幅提升。
06
总结
在本文中,我们详细介绍了 ZGC 的工作原理和调优方法,以及 AutoMQ 基于 ZGC 调优的实践经验。通过调整和优化 ZGC 的配置,我们成功降低了 AutoMQ 的延迟,提高了系统的性能和响应能力。我们希望这些经验可以帮助更多的 Java 开发者更好地理解和使用 ZGC,从而提升他们的应用程序的性能和稳定性。
腾讯新闻推荐架构升级:2 年、 300w行代码的涅槃之旅
干货 | 携程数据基础平台2.0建设,多机房架构下的演进
当「软件研发」遇上 AI 大模型
美团对 Java 新一代垃圾回收器 ZGC 的探索与实践
本文由高可用架构转载。技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号