开始使用LangGraph — 图形数据库基础
发表时间: 2024-05-27 10:58

本篇文章你将了解到图数据库的基础知识,以及它们为何在基于 RAG 的应用场景中具有相关性
前言
在 LangGraph 入门(1)-介绍 文章中,我探讨了大语言模型(LLM)加持下的应用中,图形技术的运用。我们深入了解了这些数据结构如何在多代理框架中被利用。更具体地说,我们介绍了一个名为 LangGraph 的新库,它在2024年1月推出,以图形(一个数学概念)作为代理应用的框架基础。
LangGraph 旨在克服传统 LangChain 链条的主要限制——即它们在运行时缺少循环。这个问题可以通过引入图形结构来轻松解决,因为图形结构可以轻松地在链中引入循环,而这些链本质上是有向无环图(DAGs)。
此外,在组织检索增强生成(RAG)场景中的知识库时,图形工具也显示出其强大的能力。具体来说,它们能够增强“检索”阶段,从而实现更有意义的上下文检索,最终提高生成响应的准确性。为了达到这一目标,我们的策略是将知识库存储在基于图的数据库(例如Neo4j)中,借助LLM的语义能力来正确识别和映射实体和关系。
为了现这一目标,LangChain 开发了一个名为 LLMGraphTransformer 的强大库,其目标是将非结构化文本数据转换为基于图的表示形式。
为了更好地理解这个库的工作原理,我们首先了解一下图的工作原理及相关术语。
图是一种用来建模对象之间成对关系的数学结构。它主要由两个元素组成:节点和关系。

检索增强生成(RAG)是一种在LLM驱动应用场景中的强大技术,它解决了这样一个问题:“如果我想要向我的LLM询问一些不在其训练集中的信息怎么办?”。RAG 背后的理念是将 LLM 与我们想要浏览的知识库分离,后者被适当地向量化或嵌入并存储到向量数据库中。
RAG 分为三个阶段:
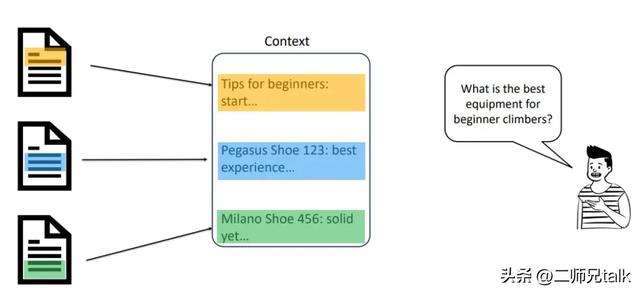
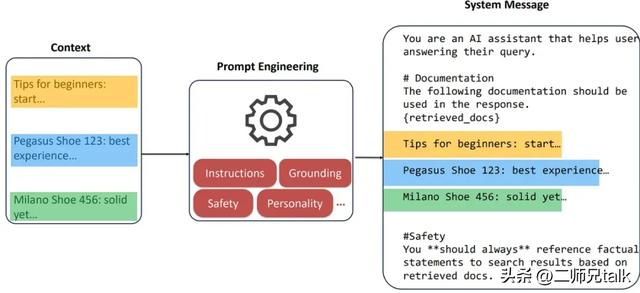
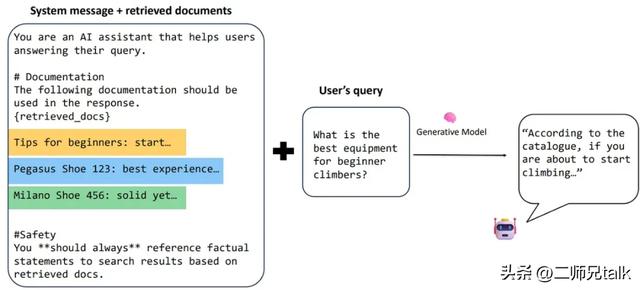
如前所述,典型的 RAG 应用都假设有一个底层的 VectorDB,并存储了所有嵌入的知识库。然而,当涉及到 GraphRAG 时,这种方法稍有不同。
事实上,GraphRAG 在“检索”阶段发挥作用,利用图结构的灵活性来存储知识库,目标是检索到更相关的文档片段,然后将其增强为上下文(你可以在这里阅读微软关于GraphRAG的第一个实验(
https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/))。你可以利用图数据库检索知识的两种主要方式:
注意:Neo4j 也支持向量搜索,这使得它非常适合混合 GraphRAG 场景。
无论你采取哪种方法,过程中的关键步骤是将你的知识库组织到你的图中。LLMGraphTransformer 就是这么一个强大的库,他可以将非结构化知识映射到你的图数据库变得更容易,下文字中,我们会用 Neo4j 作为用例来实现。
LangChain 有一个特别活跃的生态系统,包括库、预建组件和连接器,使得将 LLM 集成到你的应用中变得更容易。它的最新发布之一确实是朝着 GraphRAG 的方向:LLMGraphTransformer。
LLMGraphTransformer 强大之处在于,它利用 LLM 来解析和分类文本中的实体及其关系。实际上,得益于 LLM 的自然语言能力,生成的图倾向于捕捉文档中最复杂的相互连接,与以前的方法相比,这使得它极其准确。
因此,你可以仅用几行代码就从你的非结构化文档中得到一个完全填充的图(如果你想查看其背后的逻辑,你可以在这里看到源代码(
https://api.python.langchain.com/en/latest/_modules/langchain_experimental/graph_transformers/llm.html#LLMGraphTransformer))。
我们来看一个例子。首先,我将使用一个免费的 Neo4j Aura 数据库实例(你可以按照这个教程创建你自己的Neo4j 数据库(
https://neo4j.com/cloud/platform/aura-graph-database/?utm_source=Google&utm_medium=PaidSearch&utm_campaign=UCGenAI&utm_content=
AMS-Search-SEMCO-UCGenAI-None-SEM-SEM-NonABM&utm_term=neo4j+ai&utm_adgroup=genai-llm&gad_source=1&gclid=
CjwKCAjwxLKxBhA7EiwAXO0R0E7DBMdsxo8LGQQU_oHNTuC5jfoeq0gf69CBYGxVSNr5ibUyvIxiyRoCOYYQAvD_BwE))和Azure OpenAI GPT-4模型。
一旦你的 AuraDB 实例被创建,你将能够在这里看到它运行(
https://login.neo4j.com/u/signup/identifier?state=
hKFo2SBPbDhNSW4zQnlpX1JuVkZTUExOTmJGNjd3WFhXU19Pb6Fur3VuaXZlcnNhbC1sb2dpbqN0aWTZIHVweGxoUE5nUXAyOC1Lbm5WQUpLS1hla0xrT3J3dlo4o2NpZNkgV1NMczYwNDdrT2pwVVNXODNnRFo0SnlZaElrNXpZVG8):

这些是将需要用来连接到实例的变量:
os.environ["NEO4J_URI"] = os.getenv("NEO4J_URI") os.environ["NEO4J_USERNAME"] = "neo4j" os.environ["NEO4J_PASSWORD"] = os.getenv("NEO4J_PASSWORD") api_key = os.getenv("AZURE_OPENAI_API_KEY") azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT") api_version = "2023-07-01-preview" 我们初始化LLM:
llm = AzureChatOpenAI( model="gpt-4", azure_deployment="gpt-4", api_key=api_key, azure_endpoint=azure_endpoint, openai_api_version=api_version, ) 我们选择使用《哈利波特与魔法石》的前几行作为示例文档(
https://docenti.unimc.it/antonella.pascali/teaching/2018/19055/files/ultima-lezione/harry-potter-and-the-philosophers-stone)):
# 初始化 LLMTransformer 模型llm_transformer = LLMGraphTransformer(llm=llm)# 转换文件from langchain_core.documents import Documenttext = """Mr. and Mrs. Dursley, of number four, Privet Drive, were proud to saythat they were perfectly normal, thank you very much. They were the lastpeople you'd expect to be involved in anything strange or mysterious,because they just didn't hold with such nonsense.Mr. Dursley was the director of a firm called Grunnings, which madedrills. He was a big, beefy man with hardly any neck, although he didhave a very large mustache. Mrs. Dursley was thin and blonde and hadnearly twice the usual amount of neck, which came in very useful as shespent so much of her time craning over garden fences, spying on theneighbors. The Dursleys had a small son called Dudley and in theiropinion there was no finer boy anywhere.The Dursleys had everything they wanted, but they also had a secret, andtheir greatest fear was that somebody would discover it. They didn'tthink they could bear it if anyone found out about the Potters. Mrs.Potter was Mrs. Dursley's sister, but they hadn't met for several years;in fact, Mrs. Dursley pretended she didn't have a sister, because hersister and her good-for-nothing husband were as unDursleyish as it waspossible to be. The Dursleys shuddered to think what the neighbors wouldsay if the Potters arrived in the street. The Dursleys knew that thePotters had a small son, too, but they had never even seen him. This boywas another good reason for keeping the Potters away; they didn't wantDudley mixing with a child like that."""documents = [Document(page_content=text)]graph_documents = llm_transformer.convert_to_graph_documents(documents)print(f"Nodes:{graph_documents[0].nodes}")print(f"Relationships:{graph_documents[0].relationships}")Nodes:[Node(id='Mr. Dursley', type='Person'), Node(id='Mrs. Dursley', type='Person'), Node(id='Dudley', type='Person'), Node(id='Privet Drive', type='Location'), Node(id='Grunnings', type='Organization'), Node(id='Mrs. Potter', type='Person'), Node(id='The Potters', type='Family')]Relationships:[Relationship(source=Node(id='Mr. Dursley', type='Person'), target=Node(id='Mrs. Dursley', type='Person'), type='MARRIED_TO'), Relationship(source=Node(id='Mr. Dursley', type='Person'), target=Node(id='Dudley', type='Person'), type='PARENT_OF'), Relationship(source=Node(id='Mrs. Dursley', type='Person'), target=Node(id='Dudley', type='Person'), type='PARENT_OF'), Relationship(source=Node(id='Mr. Dursley', type='Person'), target=Node(id='Grunnings', type='Organization'), type='WORKS_AT'), Relationship(source=Node(id='Mr. Dursley', type='Person'), target=Node(id='Privet Drive', type='Location'), type='LIVES_AT'), Relationship(source=Node(id='Mrs. Dursley', type='Person'), target=Node(id='Privet Drive', type='Location'), type='LIVES_AT'), Relationship(source=Node(id='Mrs. Dursley', type='Person'), target=Node(id='Mrs. Potter', type='Person'), type='SISTER_OF'), Relationship(source=Node(id='The Dursleys', type='Family'), target=Node(id='The Potters', type='Family'), type='WANTS_TO_AVOID')]正如你所看到的,我们的 llm_transformer 能够从数据中捕捉到相关的实体和关系,无需我们指定任何内容。现在我们需要将这些节点和关系存储在我们的 AuraDB 中。
graph.add_graph_documents( graph_documents, baseEntityLabel=True, include_source=True)我们现在有了一个填充的图数据库。我们现在可以在我们的在线 AuraDB 实例中检查文档是否已正确上传:

还可以使用以下 Python 函数绘制我们数据库的图形表示:
# 直接显示给定Cypher查询的结果图default_cypher = "MATCH (s)-[r:!MENTIONS]->(t) RETURN s,r,t LIMIT 50"def showGraph(cypher: str = default_cypher): # 创建一个neo4j会话来运行查询 driver = GraphDatabase.driver( uri = os.environ["NEO4J_URI"], auth = (os.environ["NEO4J_USERNAME"], os.environ["NEO4J_PASSWORD"])) session = driver.session() widget = GraphWidget(graph = session.run(cypher).graph()) widget.node_label_mapping = 'id' #display(widget) return widgetshowGraph()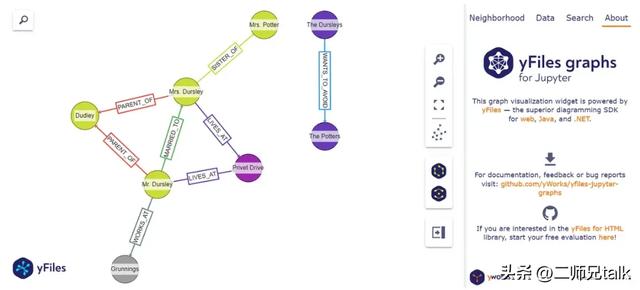
现在我们有了我们的 GraphDB,我们可以添加向量搜索功能来增强检索阶段。为此,我们将需要一个嵌入模型,我将使用 Azure OpenAI 的 text-embedding-ada-002 如下:
from langchain_openai import AzureOpenAIEmbeddingsembeddings = AzureOpenAIEmbeddings( model="text-embedding-ada-002", api_key=api_key, azure_endpoint=azure_endpoint, openai_api_version=api_version,)vector_index = Neo4jVector.from_existing_graph( embeddings, search_type="hybrid", node_label="Document", text_node_properties=["text"], embedding_node_property="embedding")vector_index 已经可以使用向量相似性方法进行查询了:
query = "Who is Dudley?"results = vector_index.similarity_search(query, k=1)print(results[0].page_content)Mr. and Mrs. Dursley, of number four, Privet Drive, were proud to saythat they were perfectly normal, thank you very much. They were the lastpeople you'd expect to be involved in anything strange or mysterious,because they just didn't hold with such nonsense.Mr. Dursley was the director of a firm called Grunnings, which madedrills. He was a big, beefy man with hardly any neck, although he didhave a very large mustache. Mrs. Dursley was thin and blonde and hadnearly twice the usual amount of neck, which came in very useful as shespent so much of her time craning over garden fences, spying on theneighbors. The Dursleys had a small son called Dudley and in theiropinion there was no finer boy anywhere.The Dursleys had everything they wanted, but they also had a secret, andtheir greatest fear was that somebody would discover it. They didn'tthink they could bear it if anyone found out about the Potters. Mrs.Potter was Mrs. Dursley's sister, but they hadn't met for several years;in fact, Mrs. Dursley pretended she didn't have a sister, because hersister and her good-for-nothing husband were as unDursleyish as it waspossible to be. The Dursleys shuddered to think what the neighbors wouldsay if the Potters arrived in the street. The Dursleys knew that thePotters had a small son, too, but they had never even seen him. This boywas another good reason for keeping the Potters away; they didn't wantDudley mixing with a child like that.由于没有将文本分割成块,查询会返回整个文档。我们将在下一篇文章中处理较大的文档。
最后一步是从我们的模型中获取实际生成的答案。为此,我们可以利用两种不同的方法:
from langchain.chains import GraphCypherQAChainchain = GraphCypherQAChain.from_llm(graph=graph, llm=llm, verbose=True)response = chain.invoke({"query": "What is Mr. Dursley's job?"})response> Entering new GraphCypherQAChain chain...Generated Cypher:MATCH (p:Person {id: "Mr. Dursley"})-[:WORKS_AT]->(o:Organization) RETURN o.idFull Context:[{'o.id': 'Grunnings'}]> Finished chain.{'query': "What is Mr. Dursley's job?", 'result': 'Mr. Dursley works at Grunnings.'}利用经典QA链并使用方法 vector_index.as_retriever(),它可以应用于 LangChain 中的数据存储(无论是vectordb还是graphdb)。
from langchain.chains import RetrievalQAqa_chain = RetrievalQA.from_chain_type(llm, retriever=vector_index.as_retriever())result = qa_chain({"query": "What is Mr. Dursley's job?"})result["result"]'Mr. Dursley is the director of a firm called Grunnings, which makes drills.'现在,先不考虑回答的准确性——在文档没有被分割情况下,没有进行基准测试的意义。我们将在下一篇文章中介绍些组件之间的差异,以及它们如何能够带来出色的 RAG 性能。
我们介绍了图数据库的基础知识,以及它们为何在基于 RAG 的应用场景中具有相关性。在下一篇文章中,我们将看到一个基于图的方法的实际实现,并且会利用本篇文章中介绍的所有组件。整个 GitHub 代码也将连下一篇文章一起提供。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号