揭秘当下最热门的大模型排名
发表时间: 2024-06-26 20:08
目前在大模型这个领域,走闭源路线的OpenAI发布了免费的GPT-4o,chatGPT的领先优势得到了进一步加强。而国内外各家AI大模型产商,也纷纷以GPT系列的大模型作为对标选手,在争先恐后推出自家最新的大模型。比如,前段时间Meta发布的Llama3,号称宇宙最强的开源大模型;而随后,阿里云发布通义千问大模型Qwen2.5,号称开源大模型的王者;智谱AI发布ChatGLM 4超越Llama 3,比肩GPT4等。可见随着技术的迭代,各家大模型的能力水平也在不断攀升,而各家宣称的“超越“、”比肩“究竟如何定义,那这里不得不提在大模型研究领域,各种权威的Benchmark数据集。
大模型这些公开的优质评测数据集,一方面使得各家大模型之间有了一个公开统一的评判标准,同时也为大模型的缺陷识别与能力提升提供了非常好的数据集参考。可见无论是对于大模型的从业者,还是大模型的使用者,了解这些评测数据集,究竟包括哪些领域知识、评测什么能力,对于我们选择大模型具有非常大的帮助作用。
本文将针对通用常识、综合学科、标准考试、数学推理、代码生成等领域,对目前主流的大模型评测数据集进行汇总介绍。
该数据集由斯坦福研究人员提出,用于评估NLP模型在常识推理上的性能,该数据集包含约10万个问答对,对人类来说很容易,但对SOTA模型来说具有挑战性。
https://arxiv.org/abs/1905.07830
AI2 Reasoning Challenge,简称ARC,是一个由AI2发布、中小学级别自然科学领域的多项选择问答数据集。该数据集共有7787个,分为Challenge Set(2590个)与Easy Set(5197个)两部分,同时也包含了1400万科学领域的语料库
全称Massive Multitask Language Understanding,是一种针对大模型的语言理解能力的测评,是目前最著名的大模型理解测评之一,主要由UC Berkeley大学的研究人员在2020年9月推出。该测试,主要语言为英文,涵盖57项任务,包括初等数学、美国历史、计算机科学、法律等,主要用于评测大模型的基本知识覆盖范围和理解能力。
https://arxiv.org/abs/2009.03300
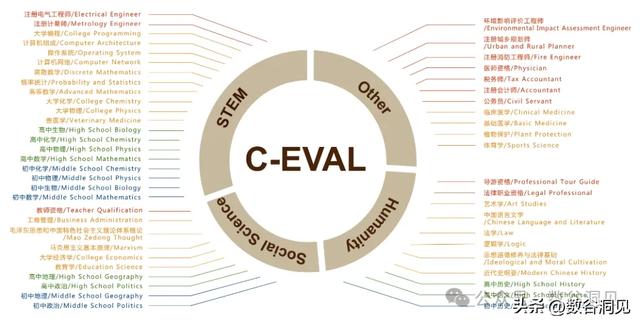
是一个多层次多学科的中文测评,由上海交通大学、清华大学和爱丁堡大学研究人员在2023年5月份联合推出,包含了13948个多项选择题,涵盖52个不同的学科和四个难度级别(中学、高中、大学和专业),用以评测大模型的中文理解能力
https://arxiv.org/pdf/2304.06364 一个由微软发布,搜集了人类现存的标准智能考试的数据集,考试包含大学入学考试、法学院入学考试、数学竞赛、律师资格考试、公务员考试,如下表所示
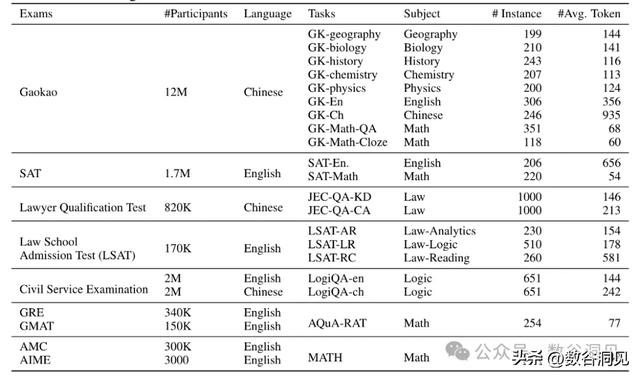
通过这个数据集,可以考察大模型的类人能力水平,令人震惊的是GPT-4在SAT、LSAT和数学竞赛中的表现均超过人类平均水平,然而在一些需要复杂推理或涉及特定领域知识的任务中表现不理想。

Chatbot Arena是一个大语言模型的benchmark平台,以众包方式进行匿名随机对战,该项目方LMSYS Org是由UC Berkeley、加州大学圣地亚哥分校和卡内基梅隆大学合作创立的研究组织。
通过demo体验地址进入对战平台,输入自己感兴趣的问题,提交问题后,匿名模型会两两对战,分别生成相关答案,然后由用户对答案做出评判(模型A更好、模型B更好、平好、都很差)。最终使用Elo评分系统对大模型的能力进行综合评估
是一个用于测评数学解决问题能力的数据集,包含12500多个样本的初高中数学题。每个样本均具有完整的求解步骤。同时这个数据集也提供了非常多的预训练数据,以便于让大模型具备基础的数学知识。https://github.com/hendrycks/math

https://github.com/openai/grade-school-math 是一个大小为8.5k的小学数学数据集,涉及基本算术运算,每道题均需要2-8个步骤才能解决,包含完整的解题过程,有助于CoT训练
https://github.com/idavidrein/gpqa Graduate-Level Google-Proof Q&A,在2023年11月发布,包含448道多项选择题,是一个由生物、物理和化学领域专家精心编制而成的高质量数据集,主要用于衡量大模型在复杂问题上的性能。
该数据集难度达到研究生水平,极具挑战性。对于一般的高技能专家,允许其无限制使用网络(google-proof)来搜寻答案,正确率仅为34%,即使是拥有某些领域博士学位的专家也只有65%的准确率。而对于GPT4,目前也仅能达到39%的正确率。
https://github.com/openai/human-eval Hand-Written Evaluation Set,是一个OpenAI在2021年发布的代码生成的数据集,主要用于评测大模型的代码生成能力。该数据集一共包括164个编程任务样本,每个任务样本包括一个提示词、有效的代码示例以及多个测试代码
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号