揭秘MySQL性能管理:提升数据库效率的关键策略
发表时间: 2019-12-01 17:00
作者:唐成勇
来源:https://segmentfault.com/a/1190000013781544
1.1 获取有性能问题SQL的三种方式
1.1.2 慢查日志分析工具
相关配置参数:
slow_query_log # 启动停止记录慢查日志,慢查询日志默认是没有开启的可以在配置文件中开启(on)slow_query_log_file # 指定慢查日志的存储路径及文件,日志存储和数据从存储应该分开存储long_query_time # 指定记录慢查询日志SQL执行时间的阀值默认值为10秒通常,对于一个繁忙的系统来说,改为0.001秒(1毫秒)比较合适log_queries_not_using_indexes #是否记录未使用索引的SQL
常用工具:mysqldumpslow和pt-query-digest
pt-query-digest --explain h=127.0.0.1,u=root,p=p@ssWord slow-mysql.log
1.1.3 实时获取有性能问题的SQL(推荐)

SELECT id,user,host,DB,command,time,state,infoFROM information_schema.processlistWHERE TIME>=60
查询当前服务器执行超过60s的SQL,可以通过脚本周期性的来执行这条SQL,就能查出有问题的SQL。
1.2 SQL的解析预处理及生成执行计划(重要)
1.2.1 查询过程描述(重点!!!)

上图原文连接
通过上图可以清晰的了解到MySql查询执行的大致过程:
1.2.2 查询缓存对性能的影响(建议关闭缓存)
第一阶段:
相关配置参数:
query_cache_type # 设置查询缓存是否可用query_cache_size # 设置查询缓存的内存大小query_cache_limit # 设置查询缓存可用的存储最大值(加上sql_no_cache可以提高效率)query_cache_wlock_invalidate # 设置数据表被锁后是否返回缓存中的数据query_cache_min_res_unit # 设置查询缓存分配的内存块的最小单
缓存查找是利用对大小写敏感的哈希查找来实现的,Hash查找只能进行全值查找(sql完全一致),如果缓存命中,检查用户权限,如果权限允许,直接返回,查询不被解析,也不会生成查询计划。
在一个读写比较频繁的系统中,建议关闭缓存,因为缓存更新会加锁。将query_cache_type设置为off,query_cache_size设置为0。
1.2.3 第二阶段:MySQL依照执行计划和存储引擎进行交互
这个阶段包括了多个子过程:



一条查询可以有多种查询方式,查询优化器会对每一种查询方式的(存储引擎)统计信息进行比较,找到成本最低的查询方式,这也就是索引不能太多的原因。
1.3 会造成MySQL生成错误的执行计划的原因
1、统计信息不准确
2、成本估算与实际的执行计划成本不同

3、给出的最优执行计划与估计的不同

4、MySQL不考虑并发查询
5、会基于固定规则生成执行计划
6、MySQL不考虑不受其控制的成本,如存储过程,用户自定义函数
1.4 MySQL优化器可优化的SQL类型
查询优化器:对查询进行优化并查询mysql认为的成本最低的执行计划。 为了生成最优的执行计划,查询优化器会对一些查询进行改写
可以优化的sql类型
1、重新定义表的关联顺序;

2、将外连接转换为内连接;
3、使用等价变换规则;

4、优化count(),min(),max();

5、将一个表达式转换为常数;
6、子查询优化;

7、提前终止查询,如发现一个不成立条件(如where id = -1),立即返回一个空结果;
8、对in()条件进行优化;
1.5 查询处理各个阶段所需要的时间
1.5.1 使用profile(目前已经不推荐使用了)
set profiling = 1; #启动profile,这是一个session级的配制执行查询show profiles; # 查询每一个查询所消耗的总时间的信息show profiles for query N; # 查询的每个阶段所消耗的时间
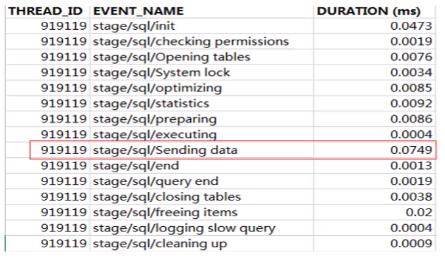
1.5.2 performance_schema是5.5引入的一个性能分析引擎(5.5版本时期开销比较大)
启动监控和历史记录表:use performance_schema
update setup_instruments set enabled='YES',TIME = 'YES' WHERE NAME LIKE 'stage%';update set_consumbers set enabled='YES',TIME = 'YES' WHERE NAME LIKE 'event%';

1.6 特定SQL的查询优化
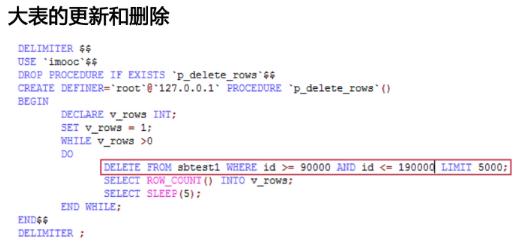
1.6.1 大表的数据修改

1.6.2 大表的结构修改

添加一个新表(修改后的结构),老表数据导入新表,老表建立触发器,修改数据同步到新表, 老表加一个排它锁(重命名), 新表重命名, 删除老表。

修改语句这个样子:
alter table sbtest4 modify c varchar(150) not null default ''
利用工具修改:

1.6.3 优化not in 和 <> 查询
子查询改写为关联查询:

2.1 分库分表的几种方式
分担读负载 可通过 一主多从,升级硬件来解决。
2.1.1 把一个实例中的多个数据库拆分到不同实例(集群)

拆分简单,不允许跨库。但并不能减少写负载。
2.1.2 把一个库中的表分离到不同的数据库中

该方式只能在一定时间内减少写压力。
以上两种方式只能暂时解决读写性能问题。
2.1.3 数据库分片
对一个库中的相关表进行水平拆分到不同实例的数据库中
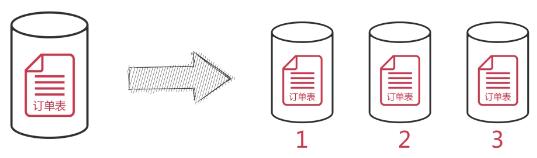
2.1.3.1 如何选择分区键
2.1.3.2 分片中如何生成全局唯一ID

声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号