掌握MySQL查询优化,提升数据库性能的秘密武器
发表时间: 2021-05-06 16:23
先来巩固一下索引的优点,检索数据快、查询稳定、存储具有顺序性避免服务器建立临时表、将随机的I/O变为有序的I/O。
但索引一旦创建的不规范就会造成以下问题,占用额外空间,浪费内存,降低数据的增、删、改性能。
所以只有在理解索引数据结构的基础上才能创建出高效的索引。
一、创建索引规范
在学习索引优化之前,需要对创建索引的规范有一定的了解,此规范来自于阿里巴巴开发手册。
二、索引失效原因
创建索引需知道在什么情况下索引会失效,只有了解索引失效的原因,在创建索引时才不会出现一些已知错误。
这句经典的语句就是涵盖创建索引时一定要符合最左侧原则。
例如表结构为u_id,u_name,u_age,u_sex,u_phone,u_time
创建索引为idx_user_name_age_sex。
查询条件必须带上u_name这一列。
不在索引列上做任何计算、函数、自动或者手动的类型转换,否则会进行全表扫描。简而言之不要在索引列上做任何操作。
例如建立了索引idx_user_name,name字段类型为varchar
在查询时使用where name = kaka,这样的查询方式会直接造成索引失效。
正确的用法为where name = “kaka”。
创建索引为idx_user_name
执行语句为select * from user where name like “kaka%”;可以命中索引。
执行语句为select name from user where name like “%kaka”;可以使用到索引(仅在8.0以上版本)。
执行语句为select * from user where name like ‘’%kaka";会直接导致索引失效
创建索引为idx_user_name_age_sex
执行语句select * from user where name = ‘kaka’ and age > 11 and sex = 1;
上面这条sql语句只会命中name和age索引,sex索引会失效。
复合索引失效需要查看key_len的长度即可。
总结:%在后边会命令索引,当使用了覆盖索引时任何查询方式都可命中索引。
以上就是关于索引失效会出现的原因总结,在很多文章中没有标注MySQL版本,所以你有可能会看到is null 、or索引会失效的结论。
在写完SQL语句之后必须要做的一件事情就是使用Explain进行SQL语句检测,看是否命中索引。
下图就是使用explain输出格式,接下来将会对输出格式进行简单的解释。
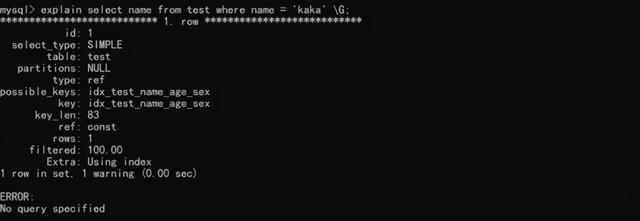
这列就是查询的编号,如果查询语句中没有子查询或者联合查询这个标识就一直是1。
如存在子查询或者联合查询这个编号会自增。
最常见的类型就是SIMPLE和PRIMARY,此列知道就行了。
理解为表名即可
此列是在优化SQL语句时最需要关注的列之一,此列显示了查询使用了何种类型。
以下排序从最优到最差。
此列显示的可能会使用到的索引
优化器从possible_keys中命中的索引
查询用到的索引长度(字节数),key_len只计算where条件用到的索引长度,而排序和分组就算用到了索引,也不会计算到key_len中。
如果是使用的常数等值查询,这里会显示const。
如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段。
如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为func。
这是mysql估算的需要扫描的行数(不是精确值)。
这个值非常直观显示 SQL 的效率好坏, 原则上 rows 越少越好。
此列表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比,不是具体记录数
在大多数情况下会出现以下几种情况。
以上就是关于Explain所有列的说明,在平时开发的过程中,一般只会关注type、key、rows、extra这四列。
四、SQL优化杀手锏之慢查询
上文说到了可以直接使用explain来分析自己的SQL语句是否合理,接下来再聊一个点那就是慢查询。
查看慢查询是否打开
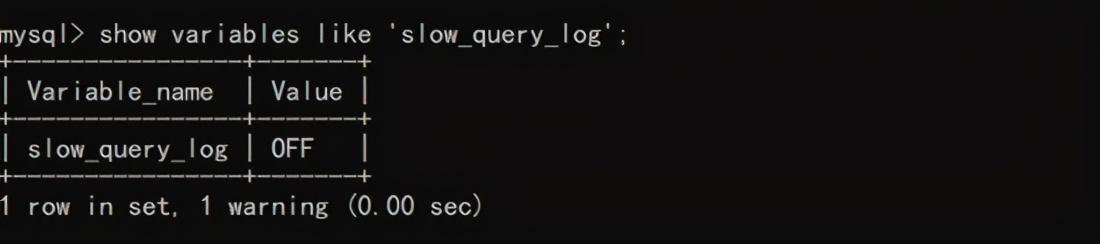
查看是否记录没有使用索引的SQL语句

开启慢查询、开启记录没有使用到索引的SQL语句
set global log_queries_not_using_idnexes=‘on’;
set global log_queries_not_using_indexes=‘on’;

查询以上俩个配置是否打开

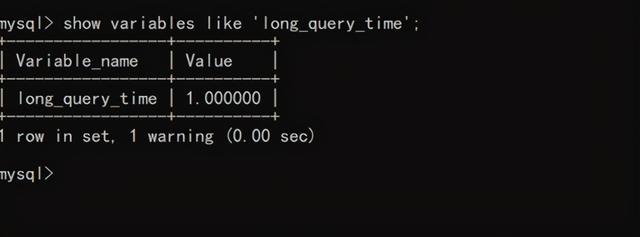
设置慢查询时间,这个时间由自己把控,一般1s即可set globle long_query_time=1;
如果查看这个时间没有变,则关于客户端再重新连接一次即可。
查看慢查询存储位置

然后随便执行一条不执行索引的语句即可在这个日志中查看到此语句

上图中一般需要主要观察的是Query_time、SQL语句内容。
以上就是关于如何使用慢查询来查看项目中出现问题的SQL语句。
五、优化大法
此处跟大家聊一些常用的SQL语句优化方案,以上的俩个工具要好好地利用,辅助我们进行打怪。
原文链接:
http://www.cnblogs.com/chaichaichai/p/14734946.html
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号