JVM深度解析:从入门到精通
发表时间: 2021-11-23 22:06
我们知道java语言是跨平台的,一处编译,到处运行。一处编译就是将java文件编译成.class字节码文件。
只要编译的字节码文件符合jvm的规范,那么就可以在java虚拟机上运行,这也说明了它的语言无关性。
那么什么是JVM?
JVM是Java Virtual Machine(Java虚拟机)的缩写,是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。Java虚拟机主要由字节码指令集、寄存器、栈、垃圾回收堆和存储方法域等构成。 JVM屏蔽了与具体操作系统平台相关的信息,使Java程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。JVM在执行字节码时,实际上最终还是把字节码解释成具体平台上的机器指令执行。
JVM的生命周期
JVM伴随Java程序的开始而开始,程序的结束而停止。一个Java程序会开启一个JVM进程,一台计算机上可以运行多个程序,也就可以运行多个JVM进程。
要先了解JVM内存模型,
首先要理解class文件的基本结构
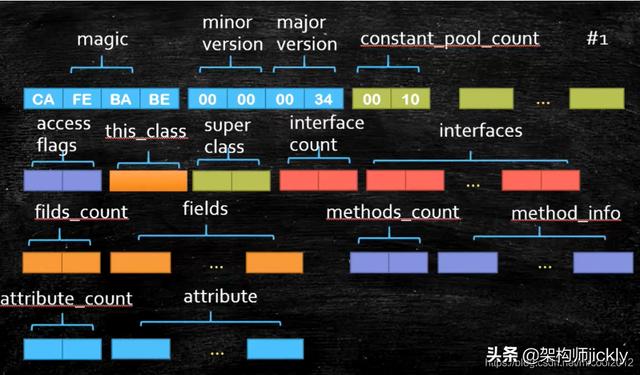
文件以CA FE BA BE开始,后面紧跟的是minor version小版本号,major version大版本号,
constant_poop_count常量池数量,后面紧跟的就是常量池内容
access flags代表的是位运算
this_class、super class是class的信息
interface count是接口数量
interfaces是相关接口的信息
field_count是属性数量
fields是属性信息
methods_count是方法数量
method_info是相关方法信息
attribute_count是属性数量
attribute是相关属性信息(包含预定义属性,也可以是自定义信息)
其次总体把握JVM的运行原理,如图
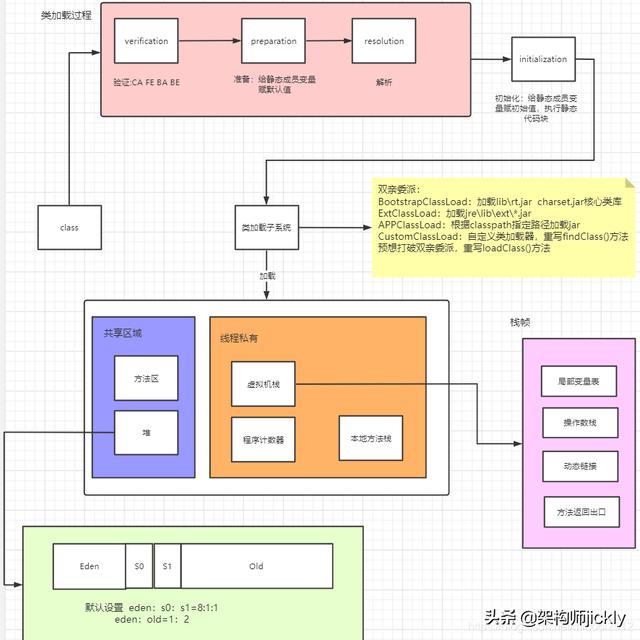
程序计数器(线程私有):
是当前线程锁执行字节码的行号计时器,每条线程都有一个独立的程序计数器,这类内存也称为“线程私有”的内存。正在执行java方法的话,计数器记录的是虚拟机字节码指令的地址(当前指令的地址)。如果是Native方法,则为空。
java 虚拟机栈(线程私有)
也是线程私有的。
每个方法在执行的时候也会创建一个栈帧,存储了局部变量,操作数,动态链接,方法返回地址。
每个方法从调用到执行完毕,对应一个栈帧在虚拟机栈中的入栈和出栈。
通常所说的栈,一般是指在虚拟机栈中的局部变量部分。
局部变量所需内存在编译期间完成分配,
如果线程请求的栈深度大于虚拟机所允许的深度,则StackOverflowError。
如果虚拟机栈可以动态扩展,扩展到无法申请足够的内存,则OutOfMemoryError。
本地方法栈(线程私有)
和虚拟机栈类似,主要为虚拟机使用到的Native方法服务。也会抛出StackOverflowError 和OutOfMemoryError。
Java堆(线程共享)
被所有线程共享的一块内存区域,在虚拟机启动的时候创建,用于存放对象实例。
对可以按照可扩展来实现(通过-Xmx 和-Xms 来控制)
当队中没有内存可分配给实例,也无法再扩展时,则抛出OutOfMemoryError异常。
堆内存可以分为两个部分:年轻代和老年代。下图中的Perm代表的是永久代,但是注意永久代并不属于堆内存中的一部分,同时jdk1.8之后永久代也将被移除。
方法区(线程共享)
被所有方法线程共享的一块内存区域。
用于存储已经被虚拟机加载的类信息,常量,静态变量等。
这个区域的内存回收目标主要针对常量池的回收和堆类型的卸载。
对象的创建过程
1.classloading
2.classlinking(verification,preparation,resolution)
verification:验证
preparation:准备,静态变量赋默认值
resolution:解析
3.classinitializing:初始化;静态变量赋初始值,执行静态代码块
4.申请对象内存
5.成员变量赋默认值
6.调用构造方法(init)
a.成员变量顺序赋初始值
b.执行构造方法语句:先调用super()
一个完整对象包含:对象头,对象体和对齐字节
其中对象头包含的内容

可以看到存放分代年龄是4bit,所以1.8默认的PS+PO垃圾回收器,默认的分代年龄最大是15,即是由此而来
既然说到GC,垃圾回收器
那么什么是垃圾?
没有任何一个引用指向的一个或多个对象(循环引用)
如何定位垃圾?
引用计数法(ReferenceCount)
根可达算法(RootSearching)
常见的垃圾回收算法
标记清除(mark sweep)--位置不连续,产生碎片,效率偏低(两遍扫描)
拷贝算法(copying)--没有碎片,浪费空间
标记压缩(mark compact)--没有碎片,效率偏低(两遍扫描,指针需要调整)
JVM内存分代模型(用于分代垃圾回收算法)
常见的垃圾回收器
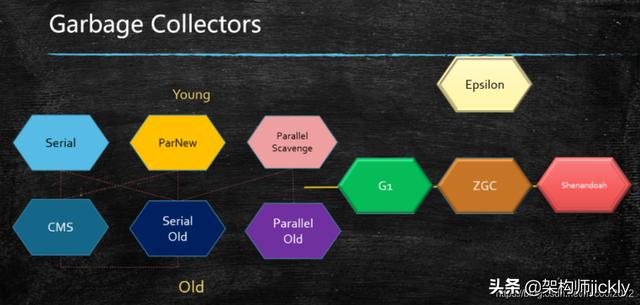
1. JDK诞生 Serial追随 提高效率,诞生了PS,为了配合CMS,诞生了PN,CMS是1.4版本后期引入,CMS是里程碑式的GC,它开启了并发回收的过程,
但是CMS毛病较多,因此目前任何一个JDK版本默认是CMS 并发垃圾回收是因为无法忍受STW
2. Serial 年轻代 串行回收
3. PS 年轻代 并行回收
4. ParNew 年轻代 配合CMS的并行回收
5. SerialOld
6. ParallelOld
7. ConcurrentMarkSweep 老年代 并发的, 垃圾回收和应用程序同时运行,降低STW的时间(200ms) CMS问题比较多,所以现在没有一个版本默认是CMS,只能手工指定 CMS既然是MarkSweep,就一定会有碎片化的问题,碎片到达一定程度,CMS的老年代分配对象分配不下的时候,使用SerialOld 进行老年代回收
想象一下:
PS + PO -> 加内存 换垃圾回收器 -> PN + CMS + SerialOld(几个小时 - 几天的STW)
几十个G的内存,单线程回收 -> G1 + FGC 几十个G -> 双T内存的服务器 ZGC
算法:三色标记 + Incremental Update
8. G1(10ms)
算法:三色标记 + SATB
9. ZGC (1ms) PK C++
算法:ColoredPointers + LoadBarrier
10. Shenandoah
算法:ColoredPointers + WriteBarrier
11. Eplison:调试用得多
12. 垃圾收集器跟内存大小的关系
常见垃圾回收器组合参数设定(JDK 1.8)
* -XX:+UseSerialGC = Serial New (DefNew) + Serial Old
* 小型程序。默认情况下不会是这种选项,HotSpot会根据计算及配置和JDK版本自动选择收集器
* -XX:+UseParNewGC = ParNew + SerialOld
* 这个组合已经很少用(在某些版本中已经废弃)
* -XX:+UseConc (urrent)MarkSweepGC = ParNew + CMS + Serial Old
* -XX:+UseParallelGC = Parallel Scavenge + Parallel Old (1.8默认) 【PS + SerialOld】
* -XX:+UseParallelOldGC = Parallel Scavenge + Parallel Old
* -XX:+UseG1GC = G1
* Linux中没找到默认GC的查看方法,而windows中会打印UseParallelGC
* java +XX:+PrintCommandLineFlags -version
* 通过GC的日志来分辨
* Linux下1.8版本默认的垃圾回收器到底是什么?
* 1.8.0_181 默认(看不出来)Copy MarkCompact
* 1.8.0_222 默认 PS + PO
调优前的基础概念
1.吞吐量:
用户代码时间 / (用户代码时间+垃圾回收时间)
2.响应时间:
STW越短,响应时间越好
所谓调优
首先确定追求啥?吞吐量优先,还是响应时间优先?还是在满足一定的响应时间的情况下,要求达到多大的吞吐量...
什么是调优?
1.根据需求进行JVM规划和预调优
2.优化运行JVM运行环境(慢,卡顿)
3.解决JVM运行过程中出现的各种问题(OOM)
到此为止,如果都理解,那么JVM应该是可以简单入门了,至于更详细的执行原理,不同垃圾回收器的垃圾回收算法等等,请听下回分解咯O(∩_∩)O
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号